
انعکاس 70B است یک مدل زبان بزرگ منبع باز (LLM) که توسط HyperWrite. این مدل جدید رویکردی را برای شناخت هوش مصنوعی معرفی میکند که میتواند نحوه تعامل و تکیه ما با سیستمهای هوش مصنوعی را در زمینههای متعدد، از پردازش زبان گرفته تا حل مشکلات پیشرفته، تغییر دهد.
اعمال نفوذ Reflection-Tuning، یک تکنیک پیشگامانه که به مدل اجازه می دهد تا اشتباهات خود را در زمان واقعی ارزیابی و تصحیح کند. GPT-4 و غزل کلود 3.5 در چندین معیار، از جمله MMLU، ریاضی، و HumanEval.
Reflection 70B بر روی مقاوم ساخته شده است لاما 3.1-70B معماری، اما مکانیسم خود پالایش آن را متمایز می کند. این مدل از طریق چرخههای تکراری بازتاب، تشخیص خطا و پالایش خروجی، شناخت انسان را به شیوهای بیسابقه تقلید میکند و مرزهای آنچه را که هوش مصنوعی میتواند به دست آورد، افزایش میدهد. در نتیجه، Reflection 70B نه تنها دقت بینظیری را ارائه میکند، بلکه بینش عمیقتری را در فرآیند تصمیمگیری خود ارائه میدهد، که یک ویژگی حیاتی برای برنامههایی است که شفافیت و دقت در آنها اهمیت بالایی دارد.
Reflection 70B چیست؟
در هسته آن، Reflection 70B ساخته شده است متن باز متا لاما 3.1-70B مدل آموزش. با این حال، چیزی که واقعاً آن را متمایز می کند، توانایی منحصر به فرد آن برای درگیر شدن در فرآیندی شبیه به بازتاب انسان است – از این رو نام آن است. این قابلیت از تکنیکی به نام «Reflection-Tuning“، که مدل را قادر می سازد تا خطاهای خود را در زمان واقعی شناسایی و اصلاح کند، بنابراین دقت و قابلیت اطمینان آن را بهبود می بخشد.
مت شومر، مدیر عامل HyperWrite، Reflection 70B را با این ادعای جسورانه معرفی کرد که “برترین مدل AI منبع باز جهان.اما دقیقاً چه چیزی این مدل را بسیار خاص میکند و چگونه در برابر غولهای صنعتی مانند GPT-4 و غزل کلود 3.5? بیایید کاوش کنیم.
درک تنظیم بازتاب انتخابی: تغییر پارادایم در آموزش هوش مصنوعی
انتخابی Reflection-Tuning رویکردی را معرفی می کند تنظیم دستورالعمل، که در آن هدف بهبود هر دو است کیفیت داده های دستورالعمل و سازگاری آن با مدل دانشجویی در حال تنظیم دقیق روشهای سنتی اغلب بر بهبود خود دادهها تمرکز میکنند، اما نادیده میگیرند که جفتهای داده بهبودیافته چقدر با اهداف یادگیری مدل همسو میشوند. تنظیم بازتاب انتخابی این شکاف را با تقویت یک پل پر می کند همکاری معلم و دانش آموز، جایی که a مدل معلم داده ها را درون نگری می کند و جفت های دستور-پاسخ تصفیه شده را ارائه می دهد، در حالی که مدل دانشجویی فقط آن بهبودهایی را ارزیابی و انتخاب می کند که به بهترین وجه با نیازهای آموزشی خود مطابقت دارند.
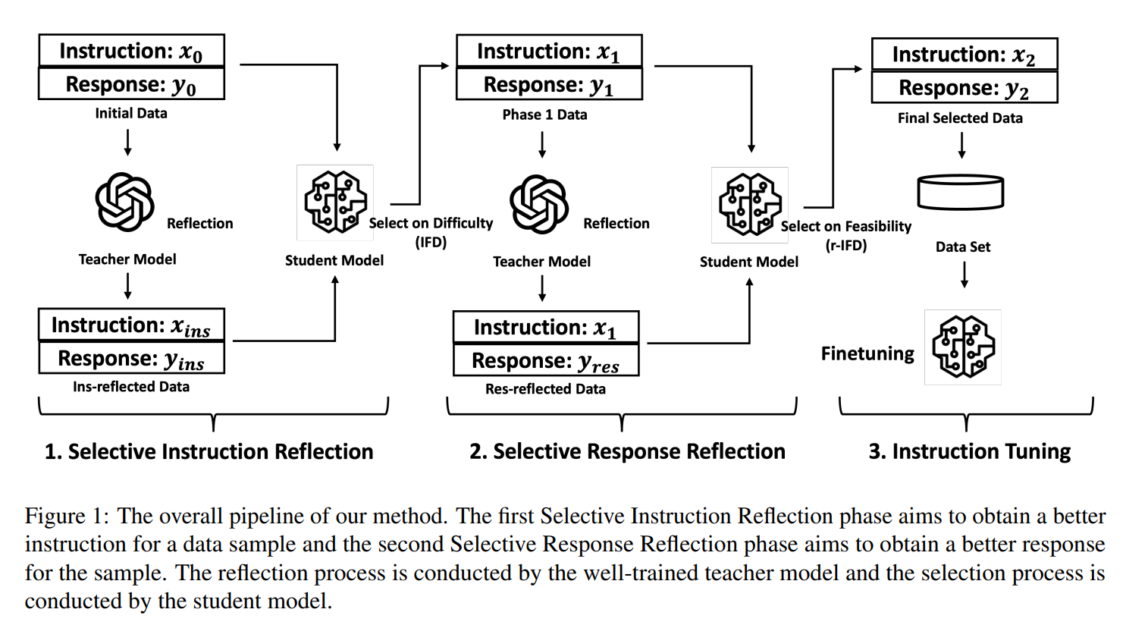
این فرآیند شامل دو مرحله کلیدی است:
- بازتاب دستورالعمل انتخابی: مدل معلم دستورالعمل یک نمونه داده شده را منعکس می کند و یک جفت دستور-پاسخ تصفیه شده ایجاد می کند. سپس مدل دانشجو ارزیابی می کند که آیا این دستورالعمل جدید بر اساس معیاری به نام مفید است یا خیر سختی دنبال کردن دستورالعمل (IFD). نمره IFD دشواری نمونه را برای مدل دانشجویی ارزیابی میکند و اطمینان میدهد که تنها دادههایی که مدل را بهطور مناسب به چالش میکشند حفظ میشوند.
- بازتاب پاسخ انتخابی: در این مرحله، الگوی معلم بر پاسخ های ایجاد شده در مرحله اول منعکس می شود. مدل دانش آموز با استفاده از این پاسخ ها را ارزیابی می کند آموزش معکوس به دنبال دشواری (r-IFD)، معیاری است که میزان امکان پذیر بودن دانش آموز را برای استنباط دستورالعمل بر اساس پاسخ اندازه گیری می کند. این تضمین می کند که پاسخ نه تنها استدلال مدل را بهبود می بخشد بلکه به خوبی با دانش موجود دانش آموز همسو می شود.
با اعمال هر دو IFD و r-IFDSelective Reflection-Tuning جفت های داده ای را تولید می کند که هنوز چالش برانگیز هستند شدنی، بهبود فرآیند تنظیم دستورالعمل بدون نیاز به مجموعه داده های اضافی. نتیجه بیشتر است نمونه کارآمد و با عملکرد بالا LLM که از بسیاری از مدل های بزرگتر بهتر عمل می کند.
معماری فکر: چگونه بازتاب 70B “فکر می کند”
معماری زیربنایی Reflection 70B با تقسیم فرآیند تفکر به چند مرحله، استدلال هوش مصنوعی را به سطح جدیدی می برد. هر مرحله به مدل اجازه می دهد تا به طور مکرر از طریق خود بازتابی، مانند شناخت انسان، بهبود یابد:
- داده های اولیه و پاسخ: مدل با ایجاد یک پاسخ به دستورالعمل داده شده شروع می شود. این خروجی اولیه مشابه خروجی های استاندارد LLM است.
- بازتاب دستورالعمل انتخابی: پس از ایجاد پاسخ اولیه، مدل وارد می شود مرحله بازتاب دستورالعمل. مدل معلم دستورالعمل اصلی را منعکس می کند و بهبودهایی را پیشنهاد می کند. سپس این پیشنهادات توسط مدل دانشجویی با استفاده از امتیاز IFD برای تعیین اینکه آیا جفت دستورالعمل-پاسخ جدید برای تنظیم بیشتر مناسب است یا خیر.
- بازتاب پاسخ انتخابی: به دنبال بازتاب در دستورالعمل، مدل حرکت می کند تا خود پاسخ را اصلاح کند. در اینجا، مدل معلم یک پاسخ جدید بر اساس دستورالعمل به روز شده ایجاد می کند. مدل دانشجویی با استفاده از امتیاز r-IFD، ارزیابی می کند که آیا پاسخ جدید به استنباط مؤثرتر دستورالعمل کمک می کند.
- تنظیم دستورالعمل نهایی: هنگامی که بهترین جفت دستورالعمل-پاسخ انتخاب شد، به مجموعه داده نهایی مورد استفاده برای تنظیم دقیق مدل اضافه می شود. این فرآیند چند مرحله ای تضمین می کند که تنها مؤثرترین و منسجم ترین جفت های دستورالعمل-پاسخ در داده های تنظیم دقیق گنجانده شده است.
این بازتاب ساختار یافته فرآیند به کاربران اجازه می دهد تا ببینند که چگونه مدل از طریق فرآیند فکری خود تکرار می شود، شفافیت ایجاد می کند و به طور قابل توجهی دقت و ثبات در کارهای پیچیده را بهبود می بخشد.
بنچمارکینگ Brilliance: Reflection 70B in Action
استفاده از Reflection 70B از Selective Reflection-Tuning نه تنها یک فرآیند آموزشی پیچیدهتر را ارائه میدهد، بلکه عملکرد پیشرو در صنعت را در چندین معیار به دست میآورد. از طریق مکانیسم خودارزیابی تکراری خود، این مدل از مدل های اختصاصی که به طور قابل توجهی از نظر اندازه بزرگتر هستند، بهتر عمل می کند.
- MMLU (درک گسترده زبان چند وظیفه ای): Reflection 70B امتیاز قابل توجهی کسب کرد 72.2٪، بهتر از سایر مدل های منبع باز بزرگ مانند LLaMA 2.
- معیار ریاضی: در تکالیف استدلال ریاضی، این مدل با اختلاف قابل توجهی از GPT-4 و Claude 3.5 پیشی گرفت و قدرت خود را در مدیریت سناریوهای حل مسئله پیچیده نشان داد.
- IFEval و GSM8K: Reflection 70B نیز در این زمینه عالی بود IFEval، جایی که آن انسجام دستورالعمل و پاسخ مورد ارزیابی قرار گرفت و در GSM8K، یک معیار حل مسئله ریاضی. تنظیم خود انعکاسی به مدل اجازه داد تا مشکلات پیچیده و ظریف را به طور موثرتری نسبت به رقبای بزرگتر خود مدیریت کند.
با استفاده از تنظیم بازتاب انتخابی، Reflection 70B این را نشان داد اندازه تنها عامل نیست در دستیابی به عملکرد بالا توانایی برای خود تصحیح و تأمل کند بر روی خروجی های آن منجر به استدلال قوی تر و منسجم تر، آن را قادر می سازد از مدل هایی با پارامترهای بیشتر پیشی بگیرد.
sRecycled WizardLM 7B در مقابل مقایسه عملکرد مدل های دیگر
کاربردهای دنیای واقعی: مهار پتانسیل انعکاس 70B
تصحیح خطای بیدرنگ Reflection 70B و تصمیمگیری شفاف درهای جدیدی را در زمینههای مختلف باز میکند. در زیر چند مورد استفاده در دنیای واقعی آورده شده است:
حل مسائل پیچیده
قدرت Reflection 70B در رسیدگی به مشکلات پیچیده نهفته است. یک پرسش ریاضی چالش برانگیز را در نظر بگیرید:
User: "Solve the equation: 2x^2 + 5x - 3 = 0" Reflection 70B:Applying the quadratic formula... A correction in calculation...
ترجمه زبان با حساسیت فرهنگی
برخلاف مدلهای ترجمه معمولی، Reflection 70B ترجمههای زبان را با زمینههای فرهنگی تطبیق میدهد:
User: "Translate 'It's raining cats and dogs' to French, considering cultural context." Reflection 70B: thinking :The literal translation would be "Il pleut des chats et des chiens"...thinking; reflection: A culturally appropriate translation would be "Il pleut des cordes."reflection; output: Translation provided.
بهبود اشکال زدایی و بهینه سازی کد
توانایی های تصحیح خطا Reflection 70B آن را برای اشکال زدایی و بهینه سازی کد ایده آل می کند:
User: "Debug this Python code..." Reflection 70B:Analyzing step by step... Identified infinite recursion.
گسترش چشم انداز رقابتی مدل های 70B
در حالی که Reflection 70B در حال ایجاد امواج است، بخشی از یک اکوسیستم گسترده تر از 70 میلیارد مدل پارامتر است. در اینجا نحوه مقایسه آن با دیگران است:
- متا لاما 3.1-70B: مدل پایه قوی که برای کاربردهای همه منظوره شناخته شده است.
- Claude 2 70B (Anthropic): مبتنی بر هوش مصنوعی اخلاقی، مهارت در استدلال و تولید محتوای طولانی مدت.
- GPT-3.5 70B (OpenAI): یک نسخه سبکتر از GPT-4 که در تعادل عملکرد به کارایی عالی است.
- BLOOM 70B: نیروگاه چند زبانه آموزش دیده بر روی زبان های طبیعی و برنامه نویسی.
- فالکون 70 بی: به دلیل کارایی آموزشی و استنتاجی آن مورد توجه قرار گرفته است.
اجرای موثر مدل های 70B: جدیدترین تکنیک ها
اجرای کارآمد مدل هایی با این اندازه کار کوچکی نیست. برای به حداکثر رساندن عملکرد، در اینجا آخرین استراتژی ها آمده است:
1. کوانتیزاسیون
کاهش دقت وزن مدل به کاهش استفاده از حافظه و زمان استنتاج کمک می کند. کوانتیزاسیون 4 بیتی تکنیک های استفاده از BitsAndBytes به Reflection 70B اجازه می دهد تا به طور موثر روی GPU های کوچکتر اجرا شود.
مثال:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-70b-hf", load_in_4bit=True)
2. مدل شاردینگ
تقسیم مدل در چندین GPU (به عنوان مثال، استفاده از DeepSpeed Zero) اجازه می دهد تا مدل های بزرگتر را بدون بیش از حافظه GPU مدیریت کنید.
from xformers.ops import memory_efficient_attention model.attention = memory_efficient_attention
3. دقت ترکیبی و توجه کارآمد
فلش توجه و xformers کاهش سربار توجه، بهبود زمان پردازش برای توالی های ورودی بزرگ.
from xformers.ops import memory_efficient_attention model.attention = memory_efficient_attention
4. CPU Offloading و Pruning
تخلیه CPU و هرس وزنههای بحرانی کمتر به اجرای مدلها بر روی سختافزار متوسطتر و در عین حال حفظ عملکرد کمک میکند.
from accelerate import cpu_offload model = cpu_offload(model)
نگاه به آینده: آینده با بازتاب 405B
مرز بعدی HyperWrite توسعه است Reflection 405B، مدلی که انتظار می رود هم در مقیاس و هم از نظر عملکرد از Reflection 70B پیشی بگیرد. این مدل قصد دارد مرزهای هوش مصنوعی منبع باز را کنار بزند و خود را در موقعیتی قرار دهد که حتی پیشرفتهترین مدلهای اختصاصی مانند GPT-5 را به چالش بکشد.
نتیجه گیری

