
ابتکار جدیدی از گروه علیبابا یکی از بهترین روشهایی را که برای تولید آواتارهای تمامبدنی انسان از یک مدل پایه مبتنی بر انتشار پایدار دیدهام، ارائه میکند.
عنوان شده است MIMO (MIMتپش با Object Interactions)، این سیستم از طیف وسیعی از فناوریها و ماژولهای محبوب، از جمله مدلهای انسانی مبتنی بر CGI و AnimateDiff، برای فعال کردن جایگزینی موقت کاراکترها در ویدیوها – یا در غیر این صورت برای هدایت یک شخصیت با حالت اسکلتی تعریف شده توسط کاربر.
در اینجا کاراکترهایی را می بینیم که از یک منبع تصویر واحد درون یابی شده اند و توسط یک حرکت از پیش تعریف شده هدایت می شوند:
[Click video below to play]
از تصاویر تک منبع، سه کاراکتر متنوع توسط یک توالی حالت سه بعدی (سمت چپ) با استفاده از سیستم MIMO هدایت می شوند. برای مثالهای بیشتر و وضوح برتر، به وبسایت پروژه و ویدیوی YouTube همراه (جاسازیشده در انتهای این مقاله) مراجعه کنید. منبع: https://menyifang.github.io/projects/MIMO/index.html
کاراکترهای تولید شده، که میتوانند از فریمهای ویدیویی و به روشهای مختلف دیگر نیز تهیه شوند، میتوانند در فیلمهای دنیای واقعی ادغام شوند.
MIMO یک سیستم جدید ارائه می دهد که سه رمزگذاری مجزا را ایجاد می کند، هر کدام برای شخصیت، صحنه و انسداد (به عنوان مثال، مات کردن، زمانی که یک شی یا شخص از جلوی شخصیتی که به تصویر کشیده می شود عبور می کند). این رمزگذاری ها در زمان استنتاج یکپارچه می شوند.
[Click video below to play]
MIMO میتواند شخصیتهای اصلی را با شخصیتهای واقعی یا سبکشده جایگزین کند که حرکت ویدیوی مورد نظر را دنبال میکنند. برای مثالهای بیشتر و وضوح برتر، به وبسایت پروژه و ویدیوی YouTube همراه (جاسازیشده در انتهای این مقاله) مراجعه کنید.
این سیستم بر روی مدل Stable Diffusion V1.5، با استفاده از یک مجموعه داده سفارشی که توسط محققان تهیه شده است، آموزش داده شده است و به طور مساوی از ویدیوهای دنیای واقعی و شبیه سازی شده تشکیل شده است.
مشکل بزرگ ویدیوهای مبتنی بر انتشار است ثبات زمانی، که در آن محتوای ویدیو یا سوسو میزند یا به روشهایی «تکامل» مییابد که برای نمایش یکنواخت کاراکتر مطلوب نیست.
MIMO، در عوض، به طور موثر از یک تصویر واحد به عنوان یک نقشه برای راهنمایی سازگار استفاده می کند، که می تواند توسط بینابینی هماهنگ و محدود شود. SMPL مدل CGI
از آنجایی که مرجع منبع سازگار است، و مدل پایه ای که سیستم بر روی آن آموزش داده شده است با نمونه های حرکت نماینده کافی بهبود یافته است، قابلیت های سیستم برای خروجی سازگار زمانی بسیار بالاتر از استاندارد عمومی برای آواتارهای مبتنی بر انتشار است.
[Click video below to play]
نمونههای بیشتر از شخصیتهای MIMO مبتنی بر حالت. برای مثالهای بیشتر و وضوح برتر، به وبسایت پروژه و ویدیوی YouTube همراه (جاسازیشده در انتهای این مقاله) مراجعه کنید.
استفاده از تصاویر منفرد به عنوان منبعی برای بازنمایی های عصبی مؤثر، یا به تنهایی یا به روشی چندوجهی، همراه با اعلان های متنی، رایج تر می شود. به عنوان مثال، محبوب LivePortrait سیستم انتقال چهره همچنین می تواند چهره های عمیق جعلی بسیار قابل قبولی ایجاد کند از تصاویر تک چهره.
محققان معتقدند که اصول استفاده شده در سیستم MIMO را می توان به انواع دیگر و جدید سیستم ها و چارچوب های مولد تعمیم داد.
را کاغذ جدید عنوان شده است MIMO: ترکیب ویدیوی کاراکتر قابل کنترل با مدلسازی تجزیهشده فضاییو از چهار محقق در موسسه محاسبات هوشمند گروه علی بابا می آید. کار دارای ویدئو بارگیری است صفحه پروژه و همراه ویدیوی یوتیوبکه در انتهای این مقاله نیز درج شده است.
روش
MIMO به صورت خودکار و بدون نظارت جداسازی سه مولفه فضایی فوق، در یک معماری انتها به انتها (یعنی تمام فرآیندهای فرعی در سیستم یکپارچه شده اند و کاربر فقط باید مواد ورودی را ارائه دهد).
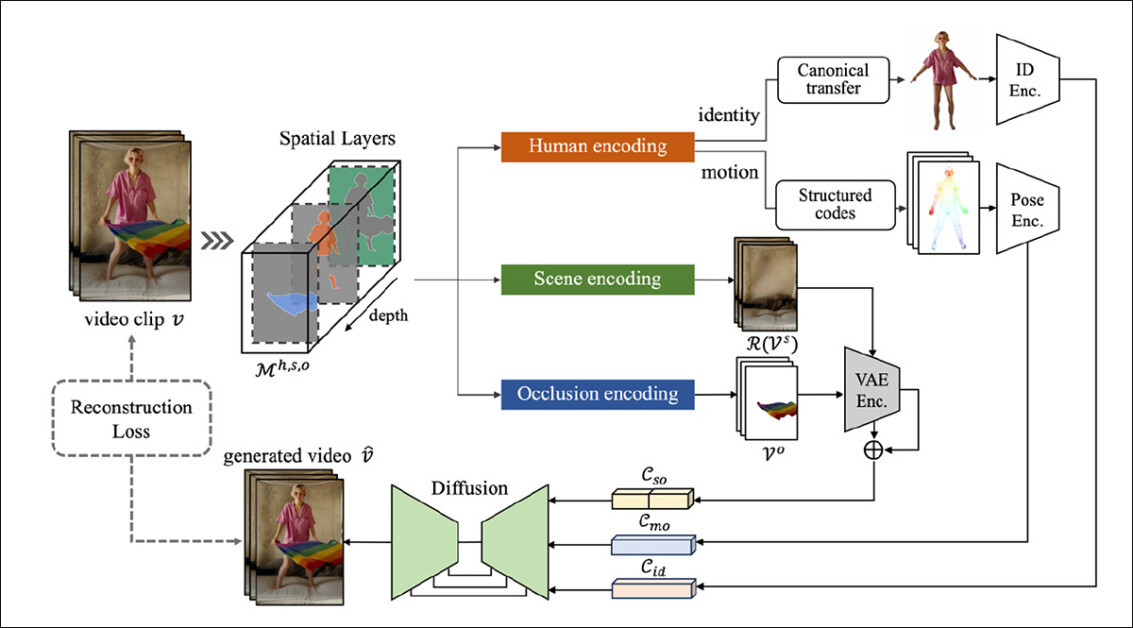
طرح مفهومی برای MIMO. منبع: https://arxiv.org/pdf/2409.16160
اشیاء در ویدیوهای منبع از دو بعدی به سه بعدی ترجمه می شوند، ابتدا با استفاده از تخمینگر عمق تک چشمی عمق هر چیزی. عنصر انسانی در هر قاب با روش های اقتباس شده از آن استخراج می شود آهنگ-A-Video پروژه
اینها ویژگی ها سپس از طریق تحقیقات فیس بوک به جنبه های حجمی مبتنی بر ویدیو ترجمه می شوند بخش هر چیزی 2 معماری
خود لایه صحنه با حذف اشیاء شناسایی شده در دو لایه دیگر به دست می آید و به طور موثر یک ماسک به سبک روتوسکوپی به صورت خودکار ارائه می کند.
برای حرکت، مجموعه ای از استخراج شده است کدهای پنهان زیرا عنصر انسانی به یک مدل SMPL مبتنی بر CGI انسانی پیشفرض متصل میشوند که حرکات آن زمینه را برای محتوای انسانی ارائهشده فراهم میکند.
یک 2 بعدی نقشه ویژگی زیرا محتوای انسانی توسط الف به دست می آید شطرنج ساز متمایز مشتق شده از a ابتکار 2020 از NVIDIA با ترکیب دادههای سهبعدی بهدستآمده از SMPL با دادههای دوبعدی بهدستآمده با روش NVIDIA، کدهای پنهان نشاندهنده «شخص عصبی» مطابقت محکمی با زمینه نهایی خود دارند.
در این مرحله، ایجاد یک مرجع معمولاً در معماری هایی که از SMPL استفاده می کنند ضروری است ژست متعارف. این به طور کلی شبیه داوینچی است “مرد ویترویی”، به این صورت که یک الگوی حالت صفر را نشان می دهد که می تواند محتوا را بپذیرد و سپس تغییر شکل داده و محتوای نقشه برداری بافت (به طور مؤثر) را با خود بیاورد.
این تغییر شکلها، یا «انحراف از هنجار»، حرکت انسان را نشان میدهد، در حالی که مدل SMPL کدهای پنهانی را که هویت انسانی استخراج شده را تشکیل میدهند، حفظ میکند و بنابراین آواتار حاصل را به درستی از نظر حالت و بافت نشان میدهد.
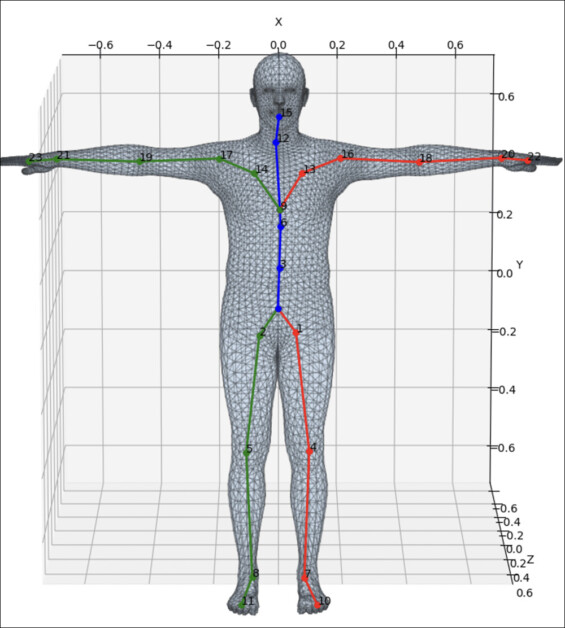
نمونه ای از ژست متعارف در شکل SMPL. منبع: https://www.researchgate.net/figure/Layout-of-23-joints-in-the-SMPL-models_fig2_351179264
با توجه به موضوع درهم تنیدگی (میزانی که دادههای آموزشدیده میتوانند غیرقابل انعطاف باشند وقتی آنها را فراتر از محدودیتها و انجمنهای آموزشدیده آن بکشید)، نویسندگان میگویند*:
برای جدا کردن کامل ظاهر از فریمهای ویدیویی طرحشده، یک راهحل ایدهآل این است که بازنمایی انسان پویا را از ویدیوی تک چشمی یاد بگیرید و آن را از فضای ژست به فضای متعارف تبدیل کنید.
با توجه به کارایی، ما از یک روش سادهشده استفاده میکنیم که مستقیماً تصویر انسان را به نتیجه متعارف در حالت A استاندارد با استفاده از یک مدل استراحت انسانی از پیش آموزشدیده تبدیل میکند. تصویر ظاهر متعارف سنتز شده برای به دست آوردن هویت به رمزگذارهای شناسه داده می شود.
این طراحی ساده باعث میشود که ویژگیهای هویت و حرکت کاملاً از هم باز شود. دنبال کردن [Animate Anyone]، رمزگذارهای شناسه شامل a کلیپ رمزگذار تصویر و یک معماری شبکه مرجع برای جاسازی برای ویژگی جهانی و محلی، [respectively].
برای صحنه و جنبه های انسداد، اشتراک گذاری و ثابت است رمزگذار خودکار متغیر (VAE – در این مورد مشتق از a انتشار 2013) برای جاسازی صحنه و عناصر انسداد در فضای نهفته استفاده می شود. ناسازگاری ها توسط یک کنترل می شود داخل نقاشی روش از سال 2023 ProPainter پروژه
پس از مونتاژ و روتوش به این روش، هم پسزمینه و هم هرگونه اشیاء مسدود کننده در ویدیو، مات را برای آواتار متحرک انسان فراهم میکنند.
سپس این ویژگی های تجزیه شده به a وارد می شوند U-Net ستون فقرات مبتنی بر معماری Stable Diffusion V1.5. کد صحنه کامل با نویز نهفته بومی سیستم میزبان الحاق شده است. جزء انسان از طریق یکپارچه شده است توجه به خود و توجه متقابل لایه ها به ترتیب
سپس، بی صدا نتیجه از طریق رمزگشا VAE خروجی می شود.
داده ها و آزمون ها
برای آموزش، محققان مجموعه داده های ویدئویی انسانی را با عنوان HUD-7K ایجاد کردند که شامل 5000 فیلم شخصیت واقعی و 2000 انیمیشن مصنوعی ساخته شده توسط En3D سیستم ویدئوهای واقعی به دلیل ماهیت غیر معنایی روش های استخراج شکل در معماری MIMO نیازی به حاشیه نویسی ندارند. داده های مصنوعی به طور کامل حاشیه نویسی شد.
این مدل بر روی هشت پردازنده گرافیکی NVIDIA A100 آموزش داده شده است (البته مقاله مشخص نمی کند که آیا این مدل های 40 گیگابایتی یا 80 گیگابایتی VRAM هستند)، برای 50 تکرار، با استفاده از 24 فریم ویدیو و یک اندازه دسته از چهار، تا همگرایی.
ماژول حرکتی سیستم بر روی وزنه های AnimateDiff آموزش داده شد. در طول فرآیند آموزش، وزن رمزگذار/رمزگشا VAE و رمزگذار تصویر CLIP اندازه گیری شد. منجمد شده (بر خلاف کامل تنظیم دقیق، که تأثیر بسیار گسترده تری بر مدل فونداسیون خواهد داشت).
اگرچه MIMO بر روی سیستم های مشابه آزمایش نشد، محققان آن را روی توالی حرکت خارج از توزیع دشواری که منبع آن از AMASS و میکسامو. این حرکات شامل کوهنوردی، بازی و رقص بود.
آنها همچنین این سیستم را بر روی ویدیوهای انسانی در طبیعت آزمایش کردند. در هر دو مورد، مقاله «استحکام بالا» را برای این حرکات سه بعدی نادیده، از دیدگاههای مختلف گزارش میکند.
اگرچه این مقاله چندین نتیجه تصویر ثابت ارائه می دهد که کارایی سیستم را نشان می دهد، عملکرد واقعی MIMO با نتایج ویدیویی گسترده ارائه شده در صفحه پروژه، و در ویدیوی YouTube تعبیه شده در زیر (که از آن فیلم ها در ابتدای این مقاله مشتق شده است).
نویسندگان نتیجه گیری می کنند:
‘نتایج تجربی [demonstrate] که روش ما نه تنها کاراکتر، حرکت و کنترل صحنه را انعطاف پذیر می کند، بلکه مقیاس پذیری پیشرفته را برای شخصیت های دلخواه، عمومیت به حرکات سه بعدی جدید و قابلیت کاربرد در صحنه های تعاملی را نیز امکان پذیر می کند.
ما نیز [believe] که راه حل ما، که ماهیت سه بعدی ذاتی را در نظر می گیرد و به طور خودکار ویدیوی دو بعدی را به اجزای فضایی سلسله مراتبی رمزگذاری می کند، می تواند الهام بخش تحقیقات آینده برای سنتز ویدیوی سه بعدی باشد.
علاوه بر این، چارچوب ما نه تنها برای تولید فیلمهای شخصیتی مناسب است، بلکه میتواند به طور بالقوه با سایر کارهای ترکیبی ویدئویی قابل کنترل سازگار شود.
نتیجه گیری
دیدن یک سیستم آواتار مبتنی بر انتشار پایدار که به نظر میرسد قادر به چنین پایداری زمانی باشد، طراوت بخش است – به ویژه به این دلیل که آواتارهای گاوسی به نظر میرسد به دست آوردن جایگاه بالا در این بخش تحقیقاتی خاص
آواتارهای تلطیف شده نشان داده شده در نتایج موثر هستند، و در حالی که سطح فوتورئالیسمی که MIMO می تواند تولید کند در حال حاضر با آنچه Gaussian Splatting قادر به انجام آن است برابر نیست، مزایای متنوع ایجاد انسان های موقتی سازگار در یک شبکه انتشار پنهان مبتنی بر معنایی (LDM) ) قابل توجه هستند.
* تبدیل من از استنادهای درون خطی نویسندگان به پیوندها، و در صورت لزوم، پیوندهای توضیحی خارجی.
اولین بار چهارشنبه، 25 سپتامبر 2024 منتشر شد

