
اگر سال 2022 لحظه ای بود که پتانسیل مخرب هوش مصنوعی مولد برای اولین بار توجه عمومی را به خود جلب کرد، سال 2024 سالی بود که سؤالات مربوط به قانونی بودن داده های زیربنایی آن برای مشاغلی که مشتاق به استفاده از قدرت آن هستند در کانون توجه قرار گرفت.
ایالات متحده آمریکا دکترین استفاده منصفانههمراه با مجوز علمی ضمنی که مدتها به بخشهای تحقیقاتی دانشگاهی و تجاری اجازه میداد تا هوش مصنوعی مولد را کاوش کنند، بهطور فزایندهای غیرقابل دفاع شد. شواهد سرقت ادبی ظاهر شد. متعاقبا، ایالات متحده در حال حاضر، غیر مجاز محتوای تولید شده توسط هوش مصنوعی به دلیل داشتن حق چاپ.
این مسائل به دور از حل و فصل، و به دور از حل و فصل قریب الوقوع است. در سال 2023، تا حدی به دلیل رسانه های رو به رشد و نگرانی عمومی در مورد وضعیت حقوقی خروجی تولید شده توسط هوش مصنوعی، اداره حق نسخه برداری ایالات متحده تحقیقاتی طولانی را در مورد این جنبه از هوش مصنوعی مولد آغاز کرد. بخش اول (در مورد کپی های دیجیتال) در جولای 2024.
در این میان، منافع تجاری به دلیل احتمال اینکه مدلهای گرانقیمتی که میخواهند از آنها بهرهبرداری کنند میتواند آنها را در معرض عواقب قانونی قرار دهد، زمانی که قوانین و تعاریف قطعی در نهایت ظهور پیدا میکنند، ناامید هستند.
راهحل گرانمدت کوتاهمدت مشروعیت بخشیدن به مدلهای تولیدی با آموزش آنها بر روی دادههایی است که شرکتها حق بهرهبرداری از آنها را دارند. تبدیل متن به تصویر Adobe (و اکنون متن به ویدئو) معماری فایرفلای در درجه اول توسط آن نیرو می گیرد خرید مجموعه داده عکس استوک Fotolia در سال 2014، تکمیل شده است با استفاده از داده های مالکیت عمومی منقضی شده با حق نسخه برداری*. در همان زمان، تامین کنندگان عکس سهام فعلی مانند Getty و Shutterstock با حروف بزرگ در ارزش جدید داده های دارای مجوز آنها، با تعداد فزاینده معاملات برای مجوز محتوا یا توسعه سیستم های GenAI سازگار با IP خود.
راه حل های مصنوعی
از زمان حذف داده های دارای حق چاپ از آموزش دیده فضای نهفته یک مدل هوش مصنوعی است مملو از مشکلات، اشتباهات در این زمینه به طور بالقوه می تواند برای شرکت هایی که با راه حل های مصرف کننده و تجاری که از یادگیری ماشینی استفاده می کنند، بسیار پرهزینه باشد.
یک راه حل جایگزین و بسیار ارزان تر برای سیستم های بینایی کامپیوتری (و همچنین مدل های زبان بزرگ، یا LLMs) استفاده از داده های مصنوعی، که در آن مجموعه داده از نمونه های تولید شده به طور تصادفی از دامنه هدف (مانند چهره ها، گربه ها، کلیساها یا حتی مجموعه داده های کلی تر) تشکیل شده است.
سایتهایی مانند thispersondoesnotexist.com مدتها پیش این ایده را رایج کردند که عکسهای واقعی از افراد «غیر واقعی» را میتوان ترکیب کرد (در آن مورد خاص، از طریق شبکههای متخاصم مولد، یا GAN ها) بدون داشتن هیچ ارتباطی با افرادی که واقعاً در دنیای واقعی وجود دارند.
بنابراین، اگر یک سیستم تشخیص چهره یا یک سیستم تولیدی را بر روی چنین مثالهای انتزاعی و غیر واقعی آموزش دهید، در تئوری میتوانید استاندارد واقعی بهرهوری را برای یک مدل هوش مصنوعی بدون نیاز به بررسی اینکه آیا دادهها از نظر قانونی قابل استفاده هستند یا خیر، به دست آورید.
قانون تعادل
مشکل این است که سیستمهایی که دادههای مصنوعی تولید میکنند، خودشان بر روی دادههای واقعی آموزش دیدهاند. اگر آثاری از آن دادهها وارد دادههای مصنوعی شود، این به طور بالقوه شواهدی را ارائه میدهد که از مطالب محدود یا غیرمجاز برای سود پولی استفاده شده است.
برای جلوگیری از این امر، و برای تولید تصاویر واقعاً تصادفی، چنین مدلهایی باید اطمینان حاصل کنند که خوب هستند.تعمیم یافته است. تعمیم معیار توانایی یک مدل هوش مصنوعی آموزش دیده برای درک ذاتی مفاهیم سطح بالا (مانند “صورت”، “مرد”، یا “زن) بدون توسل به تکرار داده های آموزشی واقعی.
متأسفانه، تولید (یا تشخیص) برای سیستم های آموزش دیده دشوار است. جزئیات دانه ای مگر اینکه به طور گسترده روی یک مجموعه داده آموزش ببیند. این سیستم را در معرض خطر قرار می دهد حفظ کردن: تمایل به بازتولید، تا حدی، نمونه هایی از داده های آموزشی واقعی.
این را می توان با تنظیم آرامش بیشتر کاهش داد میزان یادگیری، یا با پایان دادن به آموزش در مرحله ای که مفاهیم اصلی هنوز انعطاف پذیر هستند و با هیچ نقطه داده خاصی مرتبط نیستند (مانند تصویر خاصی از یک شخص، در مورد مجموعه داده چهره).
با این حال، هر دوی این راهحلها احتمالاً به مدلهایی با جزئیات کمتر منتهی میشوند، زیرا سیستم فرصتی برای پیشرفت فراتر از «اصول» دامنه هدف و پایینتر رفتن به جزئیات را نداشت.
بنابراین، در ادبیات علمی، نرخ یادگیری بسیار بالا و برنامه های آموزشی جامع به طور کلی اعمال می شود. در حالی که محققان معمولاً سعی میکنند بین کاربرد گسترده و جزئیات در مدل نهایی سازش کنند، حتی سیستمهای «حافظهشده» نیز اغلب میتوانند خود را بهخوبی تعمیمیافته – حتی در آزمایشهای اولیه – به اشتباه معرفی کنند.
فاش کردن چهره
این ما را به یک مقاله جدید جالب از سوئیس میرساند، که ادعا میکند برای اولین بار نشان میدهد که تصاویر اصلی و واقعی که دادههای مصنوعی را تامین میکنند، میتوانند از تصاویر تولید شده بازیابی شوند که در تئوری باید کاملاً تصادفی باشند:

نمونههایی از تصاویر چهره که از دادههای آموزشی به بیرون درز کرده است. در ردیف بالا، تصاویر اصلی (واقعی) را می بینیم. در ردیف زیر، تصاویری را می بینیم که به صورت تصادفی تولید شده اند که به طور قابل توجهی با تصاویر واقعی مطابقت دارد. منبع: https://arxiv.org/pdf/2410.24015
نویسندگان استدلال می کنند که نتایج نشان می دهد که ژنراتورهای “مصنوعی” در حقیقت بسیاری از نقاط داده آموزشی را در جستجوی خود برای دانه بندی بیشتر به خاطر سپرده اند. آنها همچنین نشان میدهند که سیستمهایی که بر دادههای مصنوعی برای محافظت از تولیدکنندگان هوش مصنوعی در برابر عواقب قانونی متکی هستند، میتوانند در این زمینه بسیار غیرقابل اعتماد باشند.
محققان یک مطالعه گسترده بر روی شش مجموعه داده مصنوعی پیشرفته انجام دادند و نشان دادند که در همه موارد، دادههای اصلی (بالقوه دارای حق چاپ یا محافظت شده) قابل بازیابی هستند. اظهار نظر می کنند:
آزمایشهای ما نشان میدهد که مجموعه دادههای تشخیص چهره مصنوعی پیشرفته حاوی نمونههایی هستند که در دادههای آموزشی مدلهای مولدشان به نمونهها بسیار نزدیک هستند. در برخی موارد، نمونههای مصنوعی حاوی تغییرات کوچکی نسبت به تصویر اصلی هستند، با این حال، ما همچنین میتوانیم در برخی موارد مشاهده کنیم که نمونه تولید شده دارای تنوع بیشتری است (به عنوان مثال، حالتهای مختلف، شرایط نور، و غیره) در حالی که هویت حفظ میشود.
این نشان میدهد که مدلهای مولد در حال یادگیری و حفظ اطلاعات مربوط به هویت از دادههای آموزشی هستند و ممکن است هویتهای مشابهی ایجاد کنند. این نگرانی های حیاتی در مورد استفاده از داده های مصنوعی در کارهای حساس به حریم خصوصی مانند بیومتریک و تشخیص چهره ایجاد می کند.
این کاغذ عنوان شده است پرده برداری از چهره های مصنوعی: چگونه مجموعه داده های مصنوعی می توانند هویت های واقعی را آشکار کنندو از دو محقق در موسسه تحقیقاتی Idiap در Martigny، École Polytechnique Fédérale de Lozanne (EPFL) و Université de Lozanne (UNIL) در لوزان می آید.
روش، داده ها و نتایج
چهره های حفظ شده در مطالعه توسط حمله استنتاج عضویت. اگرچه این مفهوم پیچیده به نظر می رسد، اما کاملاً توضیحی است: استنباط عضویت، در این مورد، به فرآیند زیر سوال بردن یک سیستم اشاره دارد تا زمانی که داده هایی را نشان دهد که یا با داده های مورد نظر شما مطابقت دارد یا به طور قابل توجهی شبیه آن است.

نمونه های بیشتر از منابع داده استنباط شده، از مطالعه. در این مورد، تصاویر مصنوعی منبع از مجموعه داده DCFace هستند.
محققان شش مجموعه داده مصنوعی را مطالعه کردند که منبع داده (واقعی) برای آنها مشخص بود. از آنجایی که هم مجموعه داده های واقعی و هم جعلی مورد بحث، همگی دارای حجم بسیار بالایی از تصاویر هستند، این کار در واقع مانند جستجوی سوزنی در انبار کاه است.
بنابراین نویسندگان از یک مدل تشخیص چهره خارج از قفسه استفاده کردند† با یک ResNet100 ستون فقرات آموزش دیده در AdaFace عملکرد از دست دادن (روی WebFace12M مجموعه داده).
شش مجموعه داده مصنوعی مورد استفاده عبارت بودند از: DCFace (یک مدل انتشار نهفته)؛ IDiff-Face (یکنواخت – یک مدل انتشار بر اساس FFHQ). IDiff-Face (دو مرحله ای – یک نوع با استفاده از روش نمونه گیری متفاوت)؛ GANDiffFace (بر اساس شبکه های متخاصم مولد و مدل های انتشار، با استفاده از StyleGAN3 برای تولید هویت های اولیه و سپس Dream Booth برای ایجاد نمونه های متنوع)؛ IDNet (یک روش GAN، بر اساس StyleGAN-ADA) و SFace (چارچوب محافظ هویت).
از آنجایی که GANDiffFace از هر دو روش GAN و Diffusion استفاده میکند، با مجموعه داده آموزشی StyleGAN مقایسه شد – نزدیکترین منبع به یک مبدأ چهره واقعی که این شبکه ارائه میکند.
نویسندگان مجموعههای داده مصنوعی را که از روشهای CGI به جای AI استفاده میکنند، کنار گذاشتند، و در ارزیابی نتایج، به دلیل ناهنجاریهای توزیعی در این زمینه، و همچنین تصاویر غیر چهره (که اغلب در مجموعه دادههای چهره، جایی که خراشهای وب رخ میدهد، منطبقها را برای کودکان کاهش دادند. سیستم ها برای اشیا یا مصنوعاتی که دارای ویژگی های چهره مانند هستند، موارد مثبت کاذب تولید می کنند.
شباهت کسینوس برای تمام جفتهای بازیابی شده محاسبه شد و به هیستوگرامهایی که در زیر نشان داده شده است، الحاق شد:
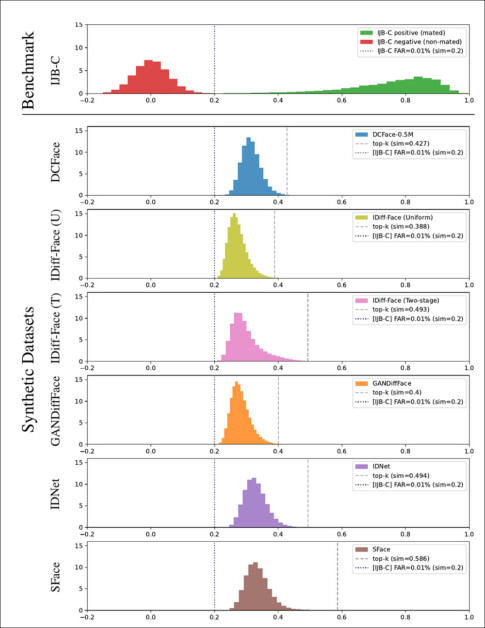
نمایش هیستوگرام برای نمرات شباهت کسینوس محاسبه شده در مجموعه داده های مختلف، همراه با مقادیر مشابه شباهت آنها برای جفت های top-k (خطوط عمودی چین دار).
تعداد شباهت ها در اسپک های نمودار بالا نشان داده شده است. این مقاله همچنین دارای مقایسه نمونه از شش مجموعه داده و تصاویر تخمینی مربوطه آنها در مجموعه داده های اصلی (واقعی) است که برخی از انتخاب ها در زیر نشان داده شده است:

نمونههایی از بسیاری از نمونههای بازتولید شده در مقاله منبع، که خواننده برای انتخاب جامعتر به آن ارجاع داده میشود.
نظر این روزنامه:
‘[The] مجموعه داده های مصنوعی تولید شده حاوی تصاویر بسیار مشابهی از مجموعه آموزشی مدل مولد خود است که نگرانی هایی را در مورد تولید چنین هویت هایی ایجاد می کند.
نویسندگان خاطرنشان میکنند که برای این رویکرد خاص، مقیاسبندی تا مجموعه دادههای با حجم بالاتر احتمالاً ناکارآمد است، زیرا محاسبات لازم بسیار سنگین خواهد بود. آنها همچنین مشاهده کردند که مقایسه بصری برای استنباط مطابقت ضروری است و تشخیص خودکار صورت به تنهایی احتمالاً برای یک کار بزرگتر کافی نخواهد بود.
با توجه به پیامدهای تحقیق و با توجه به راه های پیش رو، کار بیان می کند:
‘[We] میخواهم تاکید کنم که انگیزه اصلی برای تولید مجموعههای داده مصنوعی، رسیدگی به نگرانیهای حفظ حریم خصوصی در استفاده از مجموعه دادههای صورت خزیدهشده در مقیاس بزرگ است.
بنابراین، نشت هرگونه اطلاعات حساس (مانند هویت تصاویر واقعی در دادههای آموزشی) در مجموعه داده مصنوعی نگرانیهای حیاتی در مورد استفاده از دادههای مصنوعی برای کارهای حساس به حریم خصوصی، مانند بیومتریک را افزایش میدهد. مطالعه ما مشکلات حریم خصوصی در تولید مجموعه داده های تشخیص چهره مصنوعی را روشن می کند و راه را برای مطالعات آینده به سمت تولید مجموعه داده های مصنوعی چهره مصنوعی هموار می کند.
اگرچه نویسندگان قول انتشار کد برای این اثر را در سایت می دهند صفحه پروژه، هیچ پیوند مخزن فعلی وجود ندارد.
نتیجه گیری
اخیراً توجه رسانه ها بر این موضوع تأکید کرده است کاهش بازده با آموزش مدل های هوش مصنوعی بر روی داده های تولید شده توسط هوش مصنوعی به دست آمده است.
با این حال، تحقیقات جدید سوئیسی، توجه بیشتری را برای تعداد فزاینده شرکتهایی که میخواهند از هوش مصنوعی مولد بهره ببرند و از آن سود ببرند، مورد توجه قرار میدهد – تداوم الگوهای دادهای محافظتشده با IP یا غیرمجاز، حتی در مجموعه دادههایی که برای مبارزه با این عمل طراحی شده است. اگر بخواهیم تعریفی از آن ارائه کنیم، در این مورد ممکن است به آن «شستشوی صورت» گفته شود.
* با این حال، تصمیم Adobe برای اجازه دادن به تصاویر آپلود شده توسط کاربر که توسط هوش مصنوعی در Adobe Stock آپلود شده اند، به طور موثری خلوص قانونی این داده ها را تضعیف کرده است. بلومبرگ مناقشه کرد در آوریل 2024، تصاویر ارائه شده توسط کاربر از سیستم هوش مصنوعی MidJourney در قابلیت های Firefly گنجانده شده بود.
† این مدل در مقاله مشخص نشده است.
اولین بار چهارشنبه 6 نوامبر 2024 منتشر شد

