

فرآیندهای پاکسازی داده ها را با پانداها به صورت خودکار انجام دهید
تعداد کمی از پروژه های علم داده از نیاز به پاکسازی داده ها مستثنی هستند. پاکسازی داده ها شامل مراحل اولیه آماده سازی داده ها می شود. هدف خاص آن این است که فقط اطلاعات مرتبط و مفید زیر داده ها را حفظ کند، چه برای تجزیه و تحلیل بعدی، چه برای استفاده به عنوان ورودی به یک مدل هوش مصنوعی یا یادگیری ماشین و غیره. یکسان سازی یا تبدیل انواع داده ها، برخورد با مقادیر از دست رفته، حذف مقادیر نویز از اندازه گیری های اشتباه، و حذف موارد تکراری نمونه هایی از فرآیندهای معمول در مرحله پاکسازی داده ها هستند.
همانطور که ممکن است فکر کنید، هرچه دادهها پیچیدهتر باشند، پاکسازی دادهها پیچیدهتر، خستهکنندهتر و زمانبرتر میشود، به خصوص زمانی که به صورت دستی اجرا شود.
این مقاله بر ویژگی های ارائه شده توسط کتابخانه پانداها برای خودکارسازی فرآیند پاکسازی داده ها تمرکز دارد. در اینجا ما می رویم!
پاکسازی داده ها با پانداها: عملکردهای رایج
خودکارسازی فرآیندهای پاکسازی داده ها با پانداها به سیستماتیک کردن کاربرد ترکیبی و متوالی چندین عملکرد پاکسازی داده برای کپسوله کردن توالی اقدامات در یک خط لوله پاکسازی داده خلاصه می شود. قبل از انجام این کار، اجازه دهید برخی از توابع متداول پانداها را برای مراحل مختلف پاکسازی داده ها معرفی کنیم. در ادامه مثالی از متغیر پایتون را در نظر می گیریم df که شامل مجموعه داده ای است که در یک پاندا محصور شده است DataFrame شی
- پر کردن مقادیر از دست رفته: pandas روش هایی را برای مقابله خودکار با مقادیر از دست رفته در یک مجموعه داده ارائه می دهد، چه با جایگزین کردن مقادیر از دست رفته با یک مقدار “پیش فرض” با استفاده از
df.fillna()روش، یا با حذف هر سطر یا ستون حاوی مقادیر گم شده از طریقdf.dropna()روش - حذف نمونه های تکراری: حذف خودکار ورودیهای تکراری (ردیفها) در یک مجموعه داده نمیتواند سادهتر با
df.drop_duplicates()روشی که اجازه حذف نمونه های اضافی را می دهد زمانی که یک مقدار مشخصه خاص یا همه مقادیر نمونه در ورودی دیگری کپی می شوند. - دستکاری رشته کاراکترها: برخی از توابع پانداها برای استانداردسازی قالب ویژگی های رشته مفید هستند. به عنوان مثال، اگر ترکیبی از مقادیر کوچک، عبارت و حروف بزرگ برای a وجود داشته باشد
'column'ویژگی و ما می خواهیم همه آنها با حروف کوچک باشندdf['column'].str.lower()روش کار را انجام می دهد. برای حذف فضاهای سفید پیشرو و انتهایی به طور تصادفی، روش را امتحان کنیدdf['column'].str.strip()روش - تاریخ و زمان رسیدگی: THE
pd.to_datetime(df['column'])ستون های رشته ای حاوی اطلاعات تاریخ و زمان، به عنوان مثال در فرمت dd/mm/yyyy، را به اشیاء datetime Python تبدیل می کند، و دستکاری آنها را در آینده آسان تر می کند. - تغییر نام ستون ها: خودکارسازی فرآیند تغییر نام ستونها میتواند به ویژه زمانی مفید باشد که مجموعه دادههای متعددی وجود داشته باشد که بر اساس شهر، منطقه، پروژه و غیره از هم جدا شدهاند، و ما میخواهیم پیشوندها یا پسوندهایی را برای شناسایی آسان به برخی یا همه آنها اضافه کنیم.
df.rename(columns={old_name: new_name})روش این امکان را فراهم می کند.
قرار دادن همه چیز در کنار هم: خط لوله پاکسازی خودکار داده ها
وقت آن رسیده است که روش های مثال بالا را در یک خط لوله قابل استفاده مجدد بسته بندی کنیم که به خودکارسازی بیشتر فرآیند پاکسازی داده ها در طول زمان کمک می کند. مجموعه داده های کوچکی از تراکنش های شخصی را با سه ستون در نظر بگیرید: نام شخص، تاریخ خرید و مبلغ خرج شده:

این مجموعه داده در یک DataFrame pandas ذخیره شده است، df.
برای ایجاد یک خط لوله پاکسازی داده ساده اما محصور شده، یک کلاس سفارشی به نام ایجاد می کنیم DataCleanerبا یک سری روش های سفارشی برای هر یک از مراحل پاکسازی داده ها که در بالا توضیح داده شد، به شرح زیر:
کلاس پاک کننده داده ها: دف __ابتدا__(خود): عبور کند |
دف fill_missing_values(خود، df): برگشت df.پر کردن(روش=پر کردن).پر کردن(روش=“پر کردن”) |
توجه: THE ffill و bfill مقادیر آرگومان در روش «fillna» دو نمونه از استراتژیهای مدیریت مقادیر از دست رفته هستند. به خصوص، ffill یک “فلو به جلو” را اعمال می کند که مقادیر گمشده از مقدار ردیف قبلی را به حساب می آورد. سپس یک “back fill” با اعمال می شود bfill برای پر کردن مقادیر گمشده باقیمانده با استفاده از مقدار نمونه بعدی، اطمینان حاصل شود که هیچ مقدار از دست رفته باقی نمانده است.
دف حذف مقادیر از دست رفته(خود، df): برگشت df.رها کردن() |
دف remove_duplicates(خود، df): برگشت df.drop_dupliates() |
دف کانال ها را پاک کن(خود، df، ستون): df[column] = df[column].خ.باند().خ.پایین تر() برگشت df |
دف convert_to_date_time(خود، df، ستون): df[column] = p.d..at_date_time(df[column]) برگشت df |
دف rename_columns(خود، df، ستون_دیکت): برگشت df.تغییر نام دهید(ستون ها=ستون_دیکت) |
سپس روش “هسته” این کلاس است که تمام مراحل تمیز کردن را در یک خط لوله جمع می کند. به یاد داشته باشید که مانند هر فرآیند دستکاری داده ها، ترتیب مهم است: این به شما بستگی دارد که منطقی ترین ترتیب را برای اعمال مراحل مختلف برای به دست آوردن آنچه در داده های خود به دنبال آن هستید، تعیین کنید، بسته به مشکل خاصی که به آن پرداخته می شود.
دف own_data(خود، df): df = خود.fill_missing_values(df) df = خود.حذف مقادیر از دست رفته(df) df = خود.remove_duplicates(df) df = خود.کانال ها را پاک کن(df، ‘نام’) df = خود.convert_to_date_time(df، “تاریخ”) df = خود.rename_columns(df، {‘نام’: “نام و نام خانوادگی”}) برگشت df |
در نهایت، از کلاس جدید ایجاد شده برای اعمال کل فرآیند پاکسازی در یک حرکت و نمایش نتیجه استفاده می کنیم.
تمیز کننده = پاک کننده داده ها() cleaned_df = تمیز کننده.own_data(df) چاپ کنید(“\nDataFrame پاک شد:”) چاپ کنید(cleaned_df) |
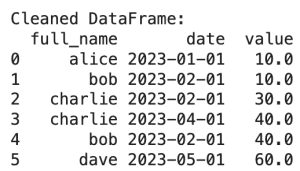
و شما آن را دارید! ما پس از اعمال برخی ویرایشها، نسخه بسیار زیباتر و یکنواختتری از دادههای اصلی خود داریم.
این خط لوله محصور شده به گونهای طراحی شده است که فرآیند کلی پاکسازی دادهها را برای هر دسته جدید دادهای که از این پس دریافت میکنید، بسیار آسانتر و آسانتر کند.
با راهنمای مبتدیان برای علم داده شروع کنید!

طرز فکر موفقیت در پروژه های علم داده را بیاموزید
… فقط با استفاده از حداقل ریاضی و آمار، مهارت های خود را با مثال های کوتاه در پایتون بسازید
نحوه کار را در کتاب الکترونیکی جدید من بیابید:
راهنمای مبتدیان برای علم داده
فراهم می کند آموزش های خودآموز با همه کد کار در پایتون تا شما را از مبتدی به متخصص برساند. او به شما نشان می دهد که چگونه یافتن نقاط پرت، تایید نرمال بودن داده ها، یافتن ویژگی های مرتبط، کنترل چولگی، بررسی مفروضاتو خیلی بیشتر… همه به شما کمک می کند تا از مجموعه ای از داده ها داستانی بسازید.