تصویر نویسنده
در این آموزش، نسل افزوده بازیابی (RAG) و چارچوب هوش مصنوعی LlamaIndex را بررسی خواهیم کرد. ما یاد خواهیم گرفت که چگونه از LlamaIndex برای ایجاد یک برنامه کاربردی مبتنی بر RAG برای پرسش و پاسخ اسناد خصوصی و بهبود برنامه با استفاده از یک بافر استفاده کنیم. این به LLM اجازه می دهد تا با استفاده از زمینه سند و تعاملات قبلی، پاسخ را ایجاد کند.
RAG در LLM چیست؟
تولید تقویت شده بازیابی (RAG) یک روش پیشرفته است که برای بهبود عملکرد مدل های زبان بزرگ (LLM) با ادغام منابع دانش خارجی در فرآیند تولید طراحی شده است.
RAG دو فاز اصلی دارد: بازیابی و تولید محتوا. در ابتدا، اسناد یا دادههای مربوطه از پایگاههای اطلاعاتی خارجی بازیابی میشوند، که سپس برای ارائه زمینه به LLM استفاده میشوند، و اطمینان حاصل میشود که پاسخها بر اساس جدیدترین و اطلاعات خاص دامنه موجود است.
LlamaIndex چیست؟
LlamaIndex یک چارچوب هوش مصنوعی پیشرفته است که برای افزایش قابلیتهای مدلهای زبان بزرگ (LLM) با تسهیل یکپارچهسازی یکپارچه با منابع داده مختلف طراحی شده است. این برنامه از بازیابی داده ها از بیش از 160 فرمت مختلف، از جمله API ها، فایل های PDF و پایگاه های داده SQL پشتیبانی می کند و آن را برای ساخت برنامه های کاربردی پیشرفته هوش مصنوعی بسیار متنوع می کند.
ما حتی میتوانیم یک برنامه هوش مصنوعی چند مرحلهای و چند وجهی کامل بسازیم و سپس آن را روی سرور مستقر کنیم تا پاسخهای بسیار دقیق و مختص دامنه ارائه کنیم. در مقایسه با سایر چارچوبها مانند LangChain، LlamaIndex راهحل سادهتری با توابع داخلی مناسب برای انواع مختلف برنامههای LLM ارائه میدهد.
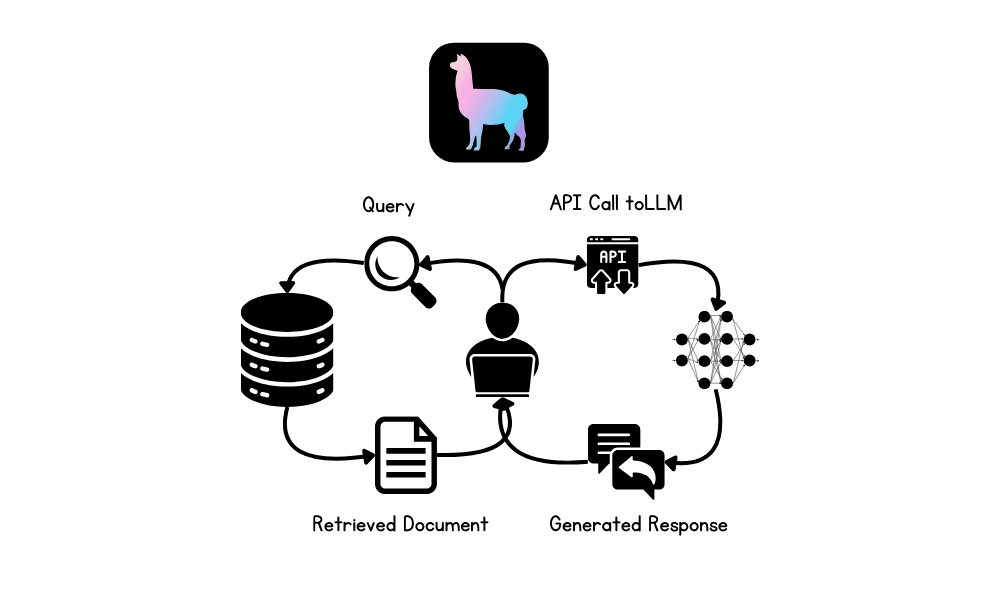
ساخت برنامه های RAG با استفاده از LlamaIndex
در این بخش، یک برنامه هوش مصنوعی ایجاد می کنیم که فایل های Microsoft Word را از یک پوشه بارگیری می کند، آنها را به جاسازی تبدیل می کند، آنها را در فروشگاه برداری فهرست می کند و یک موتور جستجوی ساده ایجاد می کند. پس از آن، ما یک چت بات RAG مناسب با تاریخچه با استفاده از ذخیره برداری به عنوان واکشی، LLM و بافر ایجاد خواهیم کرد.
راه اندازی کنید
تمام بسته های پایتون مورد نیاز برای بارگیری داده ها و برای OpenAI API را نصب کنید.
!دانه نصب کنید لاما–اشاره !دانه نصب کنید لاما–اشاره–شرکت ها–باز کردن !دانه نصب کنید لاما–اشاره–llms–باز کردن !دانه نصب کنید لاما–اشاره–خوانندگان–سپرده گذاری !دانه نصب کنید docx2txt |
LLM و مدل ادغام را با استفاده از توابع OpenAI راه اندازی کنید. ما از جدیدترین مدلهای “GPT-4o” و “Text-Embedding-3-Small” استفاده خواهیم کرد.
از آنجایی که lama_index.llms.باز کردن واردات OpenAI از آنجایی که lama_index.شرکت ها.باز کردن واردات ادغام OpenAI # LLM را مقداردهی اولیه کنید llm = OpenAI(مدل=“gpt-4o”) # ادغام را مقداردهی اولیه کنید توکار_مدل = ادغام OpenAI(مدل=“Embedded-Text-3-small”) |
هم LLM و هم مدل ادغام را روی global تنظیم کنید تا وقتی تابعی را که به LLM یا ادغام نیاز دارد فراخوانی کنیم، به طور خودکار از آن تنظیمات استفاده کند.
از آنجایی که lama_index.قلب واردات تنظیمات # تنظیمات جهانی تنظیمات.llm = llm تنظیمات.توکار_مدل = توکار_مدل |
بارگیری و نمایه سازی اسناد
داده ها را از پوشه بارگیری کنید، آن را به جاسازی تبدیل کنید و در فروشگاه برداری ذخیره کنید.
از آنجایی که lama_index.قلب واردات وکتور فهرست فروشگاه، دایرکتوری خوان ساده # اسناد بارگذاری کنید داده ها = دایرکتوری خوان ساده(ورود_دایرکتوری=“/work/data/”،موارد_نیازمند=[“.docx”]).load_data() # نمایه سازی سند با استفاده از ذخیره سازی برداری اشاره = وکتور فهرست فروشگاه.de_documents(داده ها) |
ایجاد یک موتور جستجو
لطفا فروشگاه برداری را به موتور جستجو تبدیل کنید و شروع به پرسیدن سوالات در مورد اسناد کنید. این اسناد شامل وبلاگهایی است که در ژوئن در مورد تسلط یادگیری ماشین توسط نویسنده عبید علی عوان منتشر شده است.
از آنجایی که lama_index.قلب ب>واردات/ب> وکتور فهرست فروشگاه # تبدیل فروشگاه برداری به موتور پرس و جو query_engine = اشاره.like_query_engine(similarity_top_k=3) # تولید پاسخ پرس و جو پاسخ دهید = query_engine.درخواست کنید(«موضوعات رایج وبلاگ ها چیست؟ ») چاپ کنید(پاسخ دهید) |
و پاسخ صحیح است.
موضوعات رایج وبلاگ حول محور بهبود دانش است و مهارت ها در یادگیری ماشینی آنها بر تامین منابعی از این قبیل تمرکز می کنند به عنوان کتاب های رایگان، پلتفرم ها برای همکاری، و مجموعه داده هایی برای کمک به افراد برای تعمیق درک خود از الگوریتم های یادگیری ماشین، همکاری موثر در پروژه ها، و کسب تجربه عملی از طریق داده های واقعی این منابع برای مبتدیان نیز در نظر گرفته شده است و متخصصانی که به دنبال ایجاد یک پایه محکم هستند و حرفه خود را پیش ببرند در زمینه یادگیری ماشین
ایجاد یک برنامه RAG بافر
برنامه قبلی ساده بود. بیایید یک ربات چت پیشرفته تر با قابلیت تاریخچه ایجاد کنیم.
ما چت بات را با استفاده از یک fetcher، یک بافر چت و یک مدل GPT-4o خواهیم ساخت.
در مرحله بعد، ربات چت خود را با پرسیدن سوال در یکی از پست های وبلاگ آزمایش می کنیم.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | از آنجایی که lama_index.قلب.حافظه واردات بافر گربه از آنجایی که lama_index.قلب.cat_ engine واردات CondensePlusContextChatEngine # ایجاد بافر حافظه چت حافظه = بافر گربه.from_defaults(token_limit=4500) # ایجاد یک موتور بحث cat_ engine = CondensePlusContextChatEngine.from_defaults( اشاره.like_retriever()، حافظه=حافظه، llm=llm ) # تولید پاسخ چت پاسخ دهید = cat_ engine.گربه( بهترین دوره برای تسلط بر یادگیری تقویتی چیست؟ » ) چاپ کنید(خ(پاسخ دهید)) |
بسیار دقیق و مرتبط است.
بر اساس مطالب ارائه شده، دوره در آغوش گرفتن صورت “Deep RL”. شرق بسیار توصیه می شود برای استاد یادگیری تقویتی این دوره شرق به خصوص مناسب است برای مبتدیان و هر دو اصل را پوشش می دهد و تکنیک های پیشرفته یادگیری تقویتی شامل موضوعاتی مانند به عنوان یادگیری Q، یادگیری عمیق Q، گرادیان خط مشی، عوامل ML، روشهای منتقد بازیگر، سیستمهای چند عاملی، و موضوعات پیشرفته مانند RLHF (یادگیری تقویتی) از آنجایی که بازخورد انسانی)، ترانسفورماتورهای تصمیم، و MineRL. دوره شرق طراحی شده تا در یک ماه تکمیل شود و یک آزمایش عملی ارائه می دهد با مدل ها، استراتژی هایی برای بهبود نمرات، و تابلوی امتیازات برای پیگیری پیشرفت
بیایید سوالات بعدی را بپرسیم و در مورد دوره بیشتر بدانیم.
پاسخ دهید = cat_ engine.گربه( “درباره دوره بیشتر به من بگویید” ) چاپ کنید(خ(پاسخ دهید)) |
اگر در اجرای کد بالا مشکل دارید، لطفاً به نوت بوک Deepnote مراجعه کنید: ایجاد یک برنامه RAG با استفاده از LlamaIndex.
نتیجه گیری
ساخت و استقرار برنامه های کاربردی هوش مصنوعی اکنون با LlamaIndex آسان شده است. فقط چند خط کد بنویسید و تمام.
گام بعدی در سفر یادگیری شما ایجاد یک برنامه چت بات مناسب با استفاده از Gradio و استقرار آن در سرور خواهد بود. برای آسانتر کردن زندگیتان، میتوانید Llama Cloud را نیز بررسی کنید.
در این آموزش با LlamaIndex و نحوه ایجاد یک برنامه RAG آشنا شدیم که به شما امکان می دهد از اسناد خصوصی خود سؤال بپرسید. در مرحله بعد، ما یک ربات چت RAG مناسب ایجاد کردیم که با استفاده از اسناد خصوصی و تعاملات چت قبلی، پاسخها را تولید میکند.
با راهنمای مبتدیان برای علم داده شروع کنید!

طرز فکر موفقیت در پروژه های علم داده را بیاموزید
… فقط با استفاده از حداقل ریاضی و آمار، مهارت های خود را با مثال های کوتاه در پایتون بسازید
نحوه کار را در کتاب الکترونیکی جدید من بیابید:
راهنمای مبتدیان برای علم داده
فراهم می کند آموزش های خودآموز با همه کد کار در پایتون تا شما را از مبتدی به متخصص برساند. او به شما نشان می دهد که چگونه یافتن نقاط پرت، تایید نرمال بودن داده ها، یافتن ویژگی های مرتبط، کنترل چولگی، بررسی مفروضاتو خیلی بیشتر… همه برای کمک به شما برای ایجاد یک داستان از مجموعه ای از داده ها.