
عناوین همچنان می آیند. مدل های Deepseek معیارهای چالش برانگیز ، تعیین استانداردهای جدید و ایجاد سر و صدای زیادی بوده اند. اما اتفاق جالبی که فقط در صحنه تحقیقاتی هوش مصنوعی رخ داده است که ارزش توجه شما را نیز دارد.
آلن اوی بی سر و صدا جدید خود را منتشر کرد Tülu 3 خانواده مدل ها ، و نسخه پارامتر 405B آنها فقط با DeepSeek رقابت نمی کند – بلکه آن را در معیارهای کلیدی مطابقت یا ضرب و شتم می کند.
بگذارید این موضوع را در چشم انداز قرار دهیم.
مدل 405B Tülu 3 در برابر مجریان برتر مانند بالا می رود Deepseek v3 در طیف وسیعی از کارها. ما در مناطقی مانند مشکلات ریاضی ، چالش های برنامه نویسی و دستورالعمل های دقیق زیر شاهد عملکرد قابل مقایسه یا برتر هستیم. و آنها همچنین این کار را با یک رویکرد کاملاً باز انجام می دهند.
آنها خط لوله آموزش کامل ، کد و حتی روش یادگیری تقویت کننده جدید آنها را به نام Revorce Unduction با پاداش های قابل تأیید (RLVR) منتشر کرده اند که این امر را امکان پذیر کرده است.
تحولات مانند این در طی چند هفته گذشته واقعاً در حال تغییر چگونگی پیشرفت سطح بالا AI است. وقتی کاملاً مدل منبع باز می تواند با بهترین مدل های بسته در آنجا مطابقت داشته باشد ، این امکان را باز می کند که قبلاً در پشت دیوارهای خصوصی شرکت ها قفل شده بودند.
نبرد فنی
چه چیزی باعث شده Tülu 3 ایستادگی کند؟ این به یک فرایند آموزش منحصر به فرد چهار مرحله ای می رسد که فراتر از رویکردهای سنتی است.
بگذارید ببینیم که چگونه آلن AI این مدل را ساخته است:
مرحله 1: انتخاب داده های استراتژیک
این تیم می دانست که کیفیت مدل با کیفیت داده شروع می شود. آنها مجموعه داده های مستقر مانند وحشی وت دستیار باز با محتوای سفارشی اما در اینجا بینش کلیدی وجود دارد: آنها فقط داده ها را جمع نکردند – آنها مجموعه داده های هدفمند را برای مهارت های خاص مانند استدلال ریاضی و مهارت برنامه نویسی ایجاد کردند.
مرحله 2: ایجاد پاسخ های بهتر
در مرحله دوم ، آلن AI بر آموزش مهارتهای خاص مدل خود تمرکز داشت. آنها مجموعه های مختلفی از داده های آموزشی ایجاد کردند – برخی برای ریاضیات ، برخی دیگر برای برنامه نویسی و موارد دیگر برای کارهای کلی. با آزمایش این ترکیبات به طور مکرر ، آنها دقیقاً می توانند ببینند که این مدل از کجا عالی است و در کجا به کار نیاز دارد. این فرایند تکراری پتانسیل واقعی آنچه Tülu 3 می تواند در هر منطقه به دست آورد ، نشان داد.
مرحله 3: یادگیری از مقایسه
اینجاست که آلن AI خلاقیت پیدا کرد. آنها سیستمی را ساختند که فوراً می تواند پاسخ های Tülu 3 را در برابر سایر مدل های برتر مقایسه کند. اما آنها همچنین یک مشکل مداوم را در هوش مصنوعی حل کردند – تمایل به مدل ها برای نوشتن پاسخ های طولانی فقط به خاطر طول. رویکرد آنها ، استفاده بهینه سازی اولویت مستقیم-عادی (DPO)، به معنای مدل آموخته شده برای ارزش گذاری کیفیت بیش از کمیت است. نتیجه؟ پاسخ هایی که هم دقیق و هم هدفمند هستند.
هنگامی که مدل های هوش مصنوعی از ترجیحات یاد می گیرند (کدام پاسخ بهتر است ، A یا B؟) ، آنها تمایل به ایجاد تعصب ناامیدکننده دارند: آنها شروع به فکر کردن می کنند که پاسخ های طولانی تر همیشه بهتر هستند. مثل این است که آنها سعی می کنند با گفتن بیشتر به جای گفتن چیزها ، برنده شوند.
DPO با طول ، با تنظیم نحوه یادگیری مدل از ترجیحات ، این مسئله را برطرف می کند. به جای اینکه فقط به این نکته توجه کنیم که کدام پاسخ ترجیح داده می شود ، طول هر پاسخ را در نظر می گیرد. این را به عنوان پاسخهای داوری با کیفیت آنها در هر کلمه ، و نه فقط تأثیر کل آنها فکر کنید.
چرا این موضوع مهم است؟ از آنجا که به Tülu 3 کمک می کند تا یاد بگیرد که دقیق و کارآمد باشد. به جای اینکه پاسخ های اضافی را با کلمات اضافی جامد تر به نظر برساند ، می آموزد که ارزش را در هر طول که در واقع لازم باشد ارائه دهد.
این ممکن است یک جزئیات کوچک به نظر برسد ، اما برای ساخت هوش مصنوعی که به طور طبیعی ارتباط برقرار می کند بسیار مهم است. بهترین کارشناسان انسانی می دانند چه موقع مختصر هستند و چه موقع باید توضیح دهند-و این دقیقاً همان چیزی است که DPO با طول نرمال به آموزش مدل کمک می کند.
مرحله 4: نوآوری RLVR
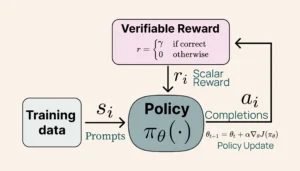
این پیشرفت فنی است که سزاوار توجه است. RLVR مدل های پاداش ذهنی را با تأیید بتن جایگزین می کند.
اکثر مدل های هوش مصنوعی از طریق یک سیستم پیچیده از مدل های پاداش یاد می گیرند – اساساً حدس های تحصیل کرده در مورد آنچه که پاسخ خوبی را ایجاد می کند. اما آلن AI با RLVR مسیری متفاوت را طی کرد.
به این فکر کنید که چگونه ما در حال حاضر مدل های AI را آموزش می دهیم. ما معمولاً به سایر مدلهای هوش مصنوعی (به نام مدل های پاداش) نیاز داریم تا در صورت پاسخگویی خوب یا خیر ، قضاوت کنیم. این ذهنی ، پیچیده و اغلب متناقض است. برخی از پاسخ ها ممکن است خوب به نظر برسند اما حاوی خطاهای ظریف هستند که از بین می روند.
RLVR این رویکرد را روی سر خود می چرخاند. به جای تکیه بر داوری های ذهنی ، از نتایج مشخص و قابل اثبات استفاده می کند. وقتی مدل یک مشکل ریاضی را امتحان می کند ، منطقه خاکستری وجود ندارد – جواب درست یا غلط است. وقتی کد را می نویسد ، آن کد به درستی اجرا می شود یا اینطور نیست.
اینجا جایی است که جالب می شود:
- این مدل بازخورد باینری فوری و باینری می شود: 10 امتیاز برای پاسخ های صحیح ، 0 برای موارد نادرست
- جایی برای اعتبار جزئی یا ارزیابی فازی وجود ندارد
- یادگیری متمرکز و دقیق می شود
- این مدل یاد می گیرد که دقت را نسبت به پاسخ های مناسب اما نادرست اما نادرست در اولویت قرار دهد
آموزش RLVR (آلن AI)
نتایج؟ Tülu 3 پیشرفت های قابل توجهی در کارهایی نشان داد که در آن صحت بیشترین اهمیت را دارد. عملکرد آن در استدلال ریاضی (معیار GSM8K) و چالش های برنامه نویسی قابل توجه بود. حتی پیروی از دستورالعمل آن دقیق تر شد زیرا این مدل آموخته است که دقت مشخصی را نسبت به پاسخ های تقریبی ارزیابی کند.
آنچه این موضوع را به ویژه هیجان انگیز می کند این است که چگونه بازی را برای منبع باز هوش مصنوعی تغییر می دهد. رویکردهای قبلی اغلب در تلاش بودند تا با دقت مدل های بسته در کارهای فنی مطابقت داشته باشند. RLVR نشان می دهد که با رویکرد آموزش مناسب ، مدل های منبع باز می توانند به همان سطح قابلیت اطمینان دست یابند.
نگاهی به اعداد
نسخه پارامتر 405B Tülu 3 به طور مستقیم با مدل های برتر در این زمینه رقابت می کند. بگذارید بررسی کنیم که از کجا عالی است و این به معنای منبع باز هوش مصنوعی چیست.
ریاضیات
Tülu 3 در استدلال پیچیده ریاضی برتری دارد. در معیارهایی مانند GSM8K و MATH ، با عملکرد Deepseek مطابقت دارد. این مدل مشکلات چند مرحله ای را بر عهده دارد و قابلیت استدلال ریاضی قوی را نشان می دهد.
رمز
نتایج برنامه نویسی به همان اندازه چشمگیر است. با تشکر از آموزش RLVR ، Tülu 3 کدی را می نویسد که مشکلات را به طور مؤثر حل می کند. قدرت آن در درک دستورالعمل های برنامه نویسی و تولید راه حل های عملکردی نهفته است.
دستورالعمل دقیق زیر
توانایی مدل در پیروی از دستورالعمل ها به عنوان یک قدرت اصلی مشخص است. در حالی که بسیاری از مدلها دستورالعمل تقریبی یا تعمیم می دهند ، Tülu 3 دقت قابل توجهی در اجرای دقیقاً آنچه خوانده می شود نشان می دهد.
باز کردن جعبه سیاه توسعه AI
آلن AI هم یک مدل قدرتمند و هم یک روند توسعه کامل آنها را منتشر کرد.
هر جنبه ای از فرایند آموزش مستند و در دسترس است. از رویکرد چهار مرحله ای به روش های تهیه داده ها و اجرای RLVR-کل فرآیند برای مطالعه و تکثیر باز است. این شفافیت استاندارد جدیدی را در توسعه هوش مصنوعی با کارایی بالا تعیین می کند.
توسعه دهندگان منابع جامع دریافت می کنند:
- خطوط لوله آموزش کامل
- ابزار پردازش داده ها
- چارچوبهای ارزیابی
- مشخصات اجرا
این تیم ها را قادر می سازد:
- فرآیندهای آموزش را اصلاح کنید
- روش ها را برای نیازهای خاص تطبیق دهید
- بر روی رویکردهای اثبات شده بنا کنید
- پیاده سازی های تخصصی ایجاد کنید
این رویکرد باز نوآوری را در سراسر زمینه تسریع می کند. محققان می توانند بر اساس روشهای تأیید شده بنا شوند ، در حالی که توسعه دهندگان می توانند به جای شروع از صفر ، روی پیشرفت ها تمرکز کنند.
ظهور تعالی منبع باز
موفقیت Tülu 3 لحظه بزرگی برای توسعه AI باز است. کی مدل های منبع باز با گزینه های خصوصی مطابقت دارند یا از آن فراتر می روند، اساساً صنعت را تغییر می دهد. تیم های تحقیقاتی در سراسر جهان به روشهای اثبات شده دسترسی پیدا می کنند ، کار خود را تسریع می کنند و نوآوری های جدید را تخم ریزی می کنند. آزمایشگاه های AI خصوصی نیاز به سازگاری دارند – یا با افزایش شفافیت یا فشار دادن مرزهای فنی حتی بیشتر.
با نگاهی به آینده ، پیشرفت های Tülu 3 در پاداش های قابل اثبات و تمرینی چند مرحله ای به آنچه در حال آمدن است ، اشاره می کنند. تیم ها می توانند بر روی این بنیادها بسازند ، و به طور بالقوه عملکرد را حتی بیشتر می کنند. کد وجود دارد ، روش ها مستند شده اند و موج جدیدی از توسعه هوش مصنوعی آغاز شده است. برای توسعه دهندگان و محققان ، فرصتی برای آزمایش و بهبود این روشها نشانگر شروع یک فصل هیجان انگیز در توسعه هوش مصنوعی است.
سوالات متداول (سؤالات متداول) در مورد Tülu 3
Tülu 3 چیست و ویژگی های اصلی آن چیست؟
Tülu 3 خانواده ای از LLM های منبع باز است که توسط Allen AI ساخته شده است که بر اساس معماری Llama 3.1 ساخته شده است. در اندازه های مختلف (پارامترهای 8B ، 70B و 405B) ارائه می شود. Tülu 3 برای بهبود عملکرد در میان کارهای متنوع از جمله دانش ، استدلال ، ریاضی ، برنامه نویسی ، دستورالعمل های زیر و ایمنی طراحی شده است.
روند آموزش Tülu 3 چیست و از چه داده هایی استفاده می شود؟
آموزش Tülu 3 شامل چندین مرحله کلیدی است. اول ، این تیم مجموعه متنوعی از اطلاعات را از هر دو مجموعه داده های عمومی و داده های مصنوعی که در مهارت های خاص هدف قرار می گیرند ، انجام می دهد ، و اطمینان می دهد که داده ها در برابر معیارها آلوده نمی شوند. دوم ، FinetUning تحت نظارت (SFT) بر روی ترکیبی از داده های پیروی از دستورالعمل ، ریاضی و برنامه نویسی انجام می شود. در مرحله بعد ، بهینه سازی اولویت مستقیم (DPO) با داده های اولویت تولید شده از طریق بازخورد انسان و LLM استفاده می شود. سرانجام ، یادگیری تقویت با پاداش های قابل تأیید (RLVR) برای کارهایی با صحت قابل اندازه گیری استفاده می شود. Tülu 3 برای هر مرحله از مجموعه داده های سرپرستی استفاده می کند ، از جمله دستورالعمل های شخصاً محور ، داده های ریاضی و کد.
چگونه Tülu 3 به ایمنی نزدیک می شود و از چه معیارهایی برای ارزیابی آن استفاده می شود؟
ایمنی یکی از مؤلفه های اصلی توسعه Tülu 3 است که در طول فرآیند آموزش مورد بررسی قرار می گیرد. یک مجموعه داده مخصوص ایمنی در طول SFT استفاده می شود ، که به نظر می رسد تا حد زیادی برای سایر داده های وظیفه گرا متعامد است.
RLVR چیست؟
RLVR تکنیکی است که در آن مدل برای بهینه سازی در برابر پاداش قابل اثبات مانند صحت یک پاسخ آموزش داده می شود. این با RLHF سنتی که از یک مدل پاداش استفاده می کند متفاوت است.