
توسعه مدلهای زبان هوش مصنوعی عمدتاً تحت تسلط انگلیسی بوده است و بسیاری از زبانهای اروپایی کمتر معرفی شدهاند. این عدم تعادل قابل توجهی را در نحوه درک و پاسخگویی فناوری های هوش مصنوعی به زبان ها و فرهنگ های مختلف ایجاد کرده است. موزل با ایجاد مجموعه ای جامع و منبع باز از داده های گفتاری برای 24 زبان رسمی اتحادیه اروپا، قصد دارد این روایت را تغییر دهد. با ارائه دادههای زبانی متنوع، MOSEL به دنبال تضمین این است که مدلهای هوش مصنوعی جامعتر و نمایانگر چشمانداز زبانی غنی اروپا هستند.
تنوع زبان برای اطمینان از جامعیت در توسعه هوش مصنوعی بسیار مهم است. اتکای بیش از حد به مدلهای انگلیسی محور میتواند منجر به فناوریهایی شود که برای گویندگان زبانهای دیگر کمتر مؤثر و یا حتی غیرقابل دسترسی هستند. مجموعه دادههای چند زبانه به ایجاد سیستمهای هوش مصنوعی کمک میکنند که به همه، صرف نظر از زبانی که صحبت میکنند، خدمت کنند. استقبال از تنوع زبانی، دسترسی به فناوری را افزایش می دهد و بازنمایی عادلانه فرهنگ ها و جوامع مختلف را تضمین می کند. با ترویج فراگیری زبانی، هوش مصنوعی می تواند واقعاً نیازها و صدای کاربران خود را منعکس کند.
مروری بر MOSEL
MOSEL یا دادههای متنباز گفتاری عظیم برای زبانهای اروپایی، پروژهای پیشگامانه است که هدف آن ایجاد مجموعهای گسترده و منبع باز از دادههای گفتاری است که تمام 24 زبان رسمی اتحادیه اروپا را پوشش میدهد. MOSEL که توسط یک تیم بین المللی از محققان توسعه یافته است، داده های 18 پروژه مختلف مانند CommonVoice، LibriSpeech، و VoxPopuli را ادغام می کند. این مجموعه شامل ضبطهای گفتار رونویسیشده و دادههای صوتی بدون برچسب است که منبع مهمی برای پیشرفت توسعه هوش مصنوعی چندزبانه است.
یکی از کمک های کلیدی MOSEL گنجاندن داده های رونویسی شده و بدون برچسب است. دادههای رونویسی شده پایهای قابل اعتماد برای آموزش مدلهای هوش مصنوعی فراهم میکند، در حالی که دادههای صوتی بدون برچسب را میتوان برای تحقیقات و آزمایشهای بیشتر، بهویژه برای زبانهای ضعیف استفاده کرد. ترکیب این مجموعه دادهها فرصتی منحصر به فرد برای توسعه مدلهای زبانی ایجاد میکند که فراگیرتر و قادر به درک چشمانداز زبانی متنوع اروپا هستند.
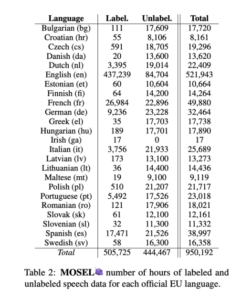
پر کردن شکاف دادهها برای زبانهای کمتر ارائهشده
توزیع دادههای گفتاری در بین زبانهای اروپایی بسیار ناهموار است و انگلیسی بر اکثر مجموعه دادههای موجود غالب است. این عدم تعادل چالشهای مهمی را برای توسعه مدلهای هوش مصنوعی که میتوانند زبانهای کمتر ارائه شده را درک کنند و به دقت پاسخ دهند، ایجاد میکند. بسیاری از زبانهای رسمی اتحادیه اروپا، مانند مالتی یا ایرلندی، دادههای بسیار محدودی دارند که مانع از توانایی فناوریهای هوش مصنوعی برای خدمترسانی مؤثر به این جوامع زبانی میشود.
MOSEL قصد دارد با استفاده از اهرم این شکاف داده را پر کند مدل Whisper OpenAI برای رونویسی خودکار 441000 ساعت از داده های صوتی بدون برچسب قبلی. این رویکرد به طور قابل توجهی در دسترس بودن مواد آموزشی را گسترش داده است، به ویژه برای زبانهایی که فاقد دادههای رونویسی دستی گسترده هستند. اگرچه رونویسی خودکار کامل نیست، اما نقطه شروع ارزشمندی برای توسعه بیشتر فراهم میکند و امکان ساخت مدلهای زبانی فراگیرتری را فراهم میکند.
با این حال، چالش ها به ویژه برای زبان های خاصی مشهود است. به عنوان مثال، مدل Whisper با مالتی مشکل داشت و به نرخ خطای کلمه بیش از 80 درصد دست یافت. چنین نرخهای خطای بالایی نیاز به کار اضافی، از جمله بهبود مدلهای رونویسی و جمعآوری دادههای رونویسی دستی با کیفیت بالا را برجسته میکند. تیم MOSEL متعهد به ادامه این تلاشها است و تضمین میکند که حتی زبانهای با منابع ضعیف نیز میتوانند از پیشرفتهای فناوری هوش مصنوعی بهره ببرند.
نقش دسترسی آزاد در نوآوری هوش مصنوعی
در دسترس بودن منبع باز MOSEL یک عامل کلیدی در ایجاد نوآوری در تحقیقات هوش مصنوعی اروپا است. با دسترسی آزادانه به دادههای گفتاری، MOSEL به محققان و توسعهدهندگان این امکان را میدهد تا با مجموعه دادههای گسترده و با کیفیت بالا که قبلاً در دسترس نبودند یا محدود بودند، کار کنند. این دسترسی، همکاری و آزمایش را تشویق میکند و رویکرد جامعه محور را برای پیشرفت فناوریهای هوش مصنوعی برای همه زبانهای اروپایی تقویت میکند.
محققان و توسعهدهندگان میتوانند از دادههای MOSEL برای آموزش، آزمایش و اصلاح مدلهای زبان هوش مصنوعی، بهویژه برای زبانهایی که کمتر در چشمانداز هوش مصنوعی معرفی شدهاند، استفاده کنند. ماهیت باز این دادهها همچنین به سازمانهای کوچکتر و مؤسسات دانشگاهی اجازه میدهد در تحقیقات پیشرفته هوش مصنوعی شرکت کنند و موانعی را که اغلب به نفع شرکتهای فناوری بزرگ با منابع انحصاری است، از بین ببرند.
مسیرهای آینده و راه پیش رو
با نگاهی به آینده، تیم MOSEL قصد دارد به گسترش مجموعه دادهها، بهویژه برای زبانهایی که کمتر معرفی شدهاند، ادامه دهد. با جمعآوری دادههای بیشتر و بهبود دقت رونویسیهای خودکار، هدف MOSEL ایجاد یک منبع متعادلتر و فراگیر برای توسعه هوش مصنوعی است. این تلاشها برای حصول اطمینان از اینکه همه زبانهای اروپایی، صرفنظر از تعداد گویشوران، جایگاهی در چشمانداز در حال تکامل هوش مصنوعی دارند، حیاتی هستند.
موفقیت MOSEL همچنین می تواند الهام بخش ابتکارات مشابه در سطح جهانی باشد و تنوع زبانی را در هوش مصنوعی فراتر از اروپا ارتقا دهد. MOSEL با ایجاد سابقه ای برای دسترسی آزاد و توسعه مشارکتی، راه را برای پروژه های آتی هموار می کند که شامل بودن و نمایندگی در هوش مصنوعی را در اولویت قرار می دهد، و در نهایت به آینده فناوری عادلانه تر کمک می کند.

