
Google DeepMind رونمایی کرده است الفاوی، یک عامل برنامه نویسی تکاملی که برای کشف مستقل الگوریتم های جدید و راه حل های علمی طراحی شده است. ارائه شده در مقاله با عنوان “Alphaevolve: یک عامل برنامه نویسی برای کشف علمی و الگوریتمی، “ این تحقیق یک گام اساسی به سمت آن است هوش عمومی مصنوعی (AGI) و حتی سرپرست مصنوعی (ASI)بشر Alphaevolve به جای تکیه بر مجموعه داده های تنظیم دقیق یا برچسب انسانی ، مسیری کاملاً متفاوت را طی می کند-مسیری که بر خلاقیت خودمختار ، نوآوری الگوریتمی و بهبود مداوم است.
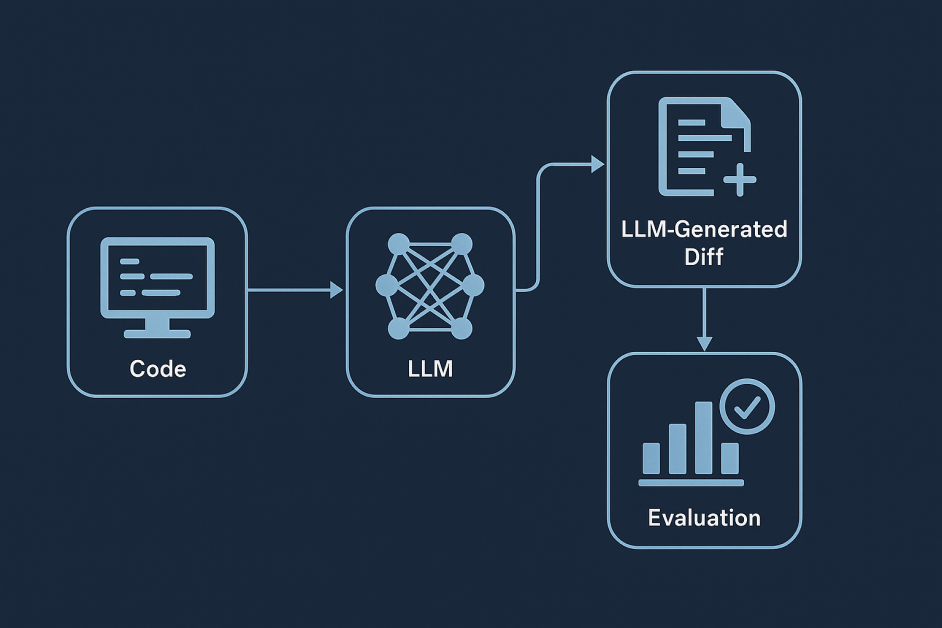
در قلب Alphaevolve یک خط لوله تکاملی خودمختار است که توسط مدل های بزرگ زبان (LLMS)بشر این خط لوله فقط خروجی ها را ایجاد نمی کند – آن را جهش می دهد ، ارزیابی می کند ، انتخاب می کند و کد را در بین نسل ها بهبود می بخشد. Alphaevolve با یک برنامه اولیه آغاز می شود و با معرفی تغییرات دقیق ساختاری ، آن را به طور تکراری پالایش می کند.
این تغییرات به شکل تغییرات کد تولید LLM ایجاد شده است که توسط یک مدل زبان بر اساس مثالهای قبلی و دستورالعمل های صریح پیشنهاد شده است. “تفاوت” در مهندسی نرم افزار به تفاوت بین دو نسخه یک پرونده اشاره دارد ، به طور معمول خطوط برجسته ای که باید حذف یا جایگزین شوند و خطوط جدیدی اضافه شوند. در Alphaevolve ، LLM با تجزیه و تحلیل برنامه فعلی و پیشنهاد ویرایش های کوچک – اضافه کردن یک تابع ، بهینه سازی یک حلقه یا تغییر یک hyperparameter – مبتنی بر سریع که شامل معیارهای عملکرد و ویرایش های موفق قبلی است ، این اختلافات را ایجاد می کند.
سپس هر برنامه اصلاح شده با استفاده از ارزیابان خودکار متناسب با کار آزمایش می شود. مؤثرترین نامزدها به عنوان الهام بخش برای تکرارهای آینده ذخیره ، ارجاع و نوترکیب می شوند. با گذشت زمان ، این حلقه تکاملی منجر به ظهور الگوریتم های به طور فزاینده ای پیچیده می شود – غالباً از آنچه که توسط متخصصان انسانی طراحی شده است ، پیشی می گیرد.
درک علم در پشت آلفاولو
در هسته خود ، Alphaevolve بر اساس اصول ساخته شده است محاسبات تکاملی– زیرزمینی از هوش مصنوعی با الهام از تکامل بیولوژیکی. این سیستم با اجرای اساسی کد شروع می شود ، که آن را به عنوان “ارگانیسم” اولیه درمان می کند. از طریق نسل ها ، Alphaevolve این کد را اصلاح می کند-تغییرات در تغییر یا “جهش”-و تناسب اندام هر تغییر را با استفاده از یک عملکرد امتیاز دهی به خوبی ارزیابی می کند. انواع بهترین عملکرد زنده مانده و به عنوان الگوی نسل بعدی خدمت می کنند.
این حلقه تکاملی از طریق:
- نمونه گیری سریع: Alphaevolve با انتخاب و تعبیه نمونه های کد قبلی موفق ، معیارهای عملکرد و دستورالعمل های خاص کار ، باعث ایجاد می شود.
- جهش کد و پیشنهاد: این سیستم از ترکیبی از LLMS قدرتمند – Gemini 2.0 Flash و Pro – استفاده می کند تا اصلاحات خاصی را در پایگاه کد فعلی به شکل متفاوت ایجاد کند.
- مکانیسم ارزیابی: یک تابع ارزیابی خودکار عملکرد هر نامزد را با اجرای آن و بازگشت نمرات مقیاس ارزیابی می کند.
- بانک اطلاعاتی و کنترل کننده: یک کنترلر توزیع شده این حلقه را تنظیم می کند ، و نتایج آن را در یک پایگاه داده تکاملی ذخیره می کند و اکتشافات را با بهره برداری از طریق مکانیسم هایی مانند نقشه های اصلی نقشه می کند.
این فرآیند تکاملی غنی و غنی از بازخورد با تکنیک های تنظیم دقیق استاندارد متفاوت است. این امر به Alphaevolve این امکان را می دهد تا راه حل های جدید ، با عملکرد بالا و گاه ضد انعطاف پذیر را تولید کند-مرز آنچه که یادگیری ماشین می تواند به صورت خودمختار به دست آورد.
مقایسه Alphaevolve با RLHF
برای قدردانی از نوآوری Alphaevolve ، مقایسه آن با آن بسیار مهم است یادگیری تقویت از بازخورد انسانی (RLHF)، یک رویکرد غالب که برای تنظیم دقیق مدل های بزرگ زبان استفاده می شود.
در RLHF ، از ترجیحات انسانی برای آموزش یک مدل پاداش استفاده می شود ، که روند یادگیری یک LLM را از طریق هدایت می کند یادگیری تقویت کننده الگوریتم ها مانند بهینه سازی سیاست پروگزیمال (PPO)بشر RLHF تراز و سودمندی مدل ها را بهبود می بخشد ، اما برای تولید داده های بازخورد نیاز به مشارکت گسترده انسان دارد و به طور معمول در یک رژیم تنظیم خوب و یک بار خوب عمل می کند.
Alphaevolve ، در مقابل:
- بازخورد انسان را از حلقه به نفع ارزیاب های قابل اجتناب از دستگاه حذف می کند.
- از یادگیری مداوم از طریق انتخاب تکاملی پشتیبانی می کند.
- به دلیل جهش های تصادفی و اجرای ناهمزمان ، فضاهای محلول بسیار گسترده تری را بررسی می کند.
- می تواند راه حل هایی ایجاد کند که فقط تراز شوند ، بلکه جدید و از نظر علمی قابل توجه است.
جایی که rlhf رفتار خوب تنظیم شده است ، alphaevolve کشف کردن وت اختراعبشر این تمایز هنگام در نظر گرفتن مسیرهای آینده به سمت AGI بسیار مهم است: Alphaevolve فقط پیش بینی های بهتری را انجام نمی دهد – این مسیرهای جدیدی را برای حقیقت پیدا می کند.
برنامه ها و پیشرفت ها
1. کشف الگوریتمی و پیشرفت های ریاضی
Alphaevolve ظرفیت خود را برای اکتشافات پیشگامانه در مشکلات الگوریتمی اصلی نشان داده است. مهمتر از همه ، این یک الگوریتم جدید برای ضرب دو ماتریس با ارزش 4 × 4 با استفاده از تنها 48 ضرب مقیاس بود-که نتیجه آن در سال 1969 استراسن از 49 ضرب و شکستن یک سقف نظری 56 ساله است. Alphaevolve از طریق تکنیک های پیشرفته تجزیه تنش که در بسیاری از تکرارها تکامل یافته است ، به این کار دست یافت و از چندین رویکرد پیشرفته ترین استفاده کرد.
فراتر از ضرب ماتریس ، Alphaevolve سهم قابل توجهی در تحقیقات ریاضی داشت. این مورد در بیش از 50 مشکل باز در زمینه هایی مانند ترکیبی ، تئوری تعداد و هندسه مورد بررسی قرار گرفت. این نتایج در حدود 75 ٪ موارد با نتایج شناخته شده مطابقت داشت و در حدود 20 ٪ از آنها فراتر رفت. این موفقیت ها شامل پیشرفت هایی در حداقل مشکل همپوشانی ERDőS ، یک راه حل متراکم تر برای مشکل شماره بوسیدن در 11 بعد و تنظیمات بسته بندی هندسی کارآمدتر است. این نتایج بر توانایی آن در عمل به عنوان یک کاوشگر ریاضی خودمختار – بازگرداندن ، تکرار و تکامل راه حل های بهینه بهینه و بدون مداخله انسانی تأکید می کند.
2. بهینه سازی در پشته محاسبات گوگل
Alphaevolve همچنین در زیرساخت های Google بهبود عملکرد ملموس را ارائه داده است:
- در برنامه ریزی مرکز داده، این یک اکتشافی جدید را کشف کرد که باعث بهبود کار شغلی می شود و 0.7 ٪ از منابع محاسباتی قبلاً رشته ای را بازیابی می کند.
- برای هسته های آموزش جمینی، Alphaevolve یک استراتژی کاشی کاری بهتر را برای ضرب ماتریس ابداع کرد و سرعت 23 ٪ هسته و کاهش کلی 1 ٪ در زمان آموزش را ارائه داد.
- در طراحی مدار TPU، این یک ساده سازی برای منطق حسابی در RTL (سطح ثبت نام ثبت) ، تأیید شده توسط مهندسان و در تراشه های TPU نسل بعدی را مشخص کرد.
- همچنین بهینه شد کد فلاشتی تولید شده توسط کامپایلر با ویرایش بازنمایی های میانی XLA ، برش زمان استنتاج در GPU ها 32 ٪.
با هم ، این نتایج ظرفیت Alphaevolve را برای کار در سطح چندین انتزاع-از ریاضیات نمادین گرفته تا بهینه سازی سخت افزار سطح پایین-تأیید می کند و به دست آوردن سود عملکرد در دنیای واقعی.
- برنامه نویسی تکاملی: یک الگوی هوش مصنوعی با استفاده از جهش ، انتخاب و وراثت برای راه حل های مکرر تصفیه می شود.
- بهینه سازی کد: جستجوی خودکار برای کارآمدترین اجرای یک عملکرد – که اغلب پیشرفت های شگفت آور و ضد انعطاف پذیر است.
- تکامل سریع متا: Alphaevolve فقط کد را تکامل نمی دهد. همچنین تکامل می یابد که چگونه دستورالعمل های مربوط به LLMS را ایجاد می کند-امکان پذیرش خود فرآیند برنامه نویسی.
- از دست دادن گسسته: یک اصطلاح منظم ترغیب خروجی ها برای تراز کردن با مقادیر نیمه اینتین یا عدد صحیح ، برای وضوح ریاضی و نمادین بسیار مهم است.
- از دست دادن توهم: مکانیسمی برای تزریق تصادفی به راه حل های میانی ، تشویق اکتشاف و جلوگیری از حداقل محلی.
- الگوریتم نقشه الله ها: نوعی الگوریتم با کیفیت با کیفیت که جمعیت متنوعی از راه حل های با عملکرد بالا را در ابعاد ویژگی حفظ می کند-نوآوری قوی.
پیامدهای AGI و ASI
Alphaevolve بیش از یک بهینه ساز است – این یک نگاه اجمالی به آینده ای است که عوامل هوشمند می توانند استقلال خلاق را نشان دهند. توانایی سیستم در تدوین مشکلات انتزاعی و طراحی رویکردهای خاص خود برای حل آنها ، گامی مهم به سمت هوش عمومی مصنوعی است. این فراتر از پیش بینی داده ها است: این شامل استدلال ساختاری ، شکل گیری استراتژی و سازگاری با بازخورد است – نشانه های رفتار هوشمند.
ظرفیت آن برای تولید و اصلاح فرضیه ها به طور مکرر نیز نشانگر تکامل در نحوه یادگیری ماشین ها است. برخلاف مدل هایی که نیاز به گسترده دارند آموزش تحت نظارت، Alphaevolve خود را از طریق حلقه آزمایش و ارزیابی بهبود می بخشد. این شکل پویا از هوش به آن اجازه می دهد تا از فضاهای مشکل پیچیده حرکت کند ، راه حل های ضعیف را دور بیندازد و موارد قوی تر را بدون نظارت مستقیم انسان بالا ببرد.
Alphaevolve با اجرای و اعتبارسنجی ایده های خود ، هم به عنوان نظریه پرداز و هم آزمایشگر عمل می کند. این فراتر از انجام وظایف از پیش تعریف شده و به قلمرو کشف و شبیه سازی یک فرایند علمی خودمختار است. هر پیشرفت پیشنهادی مورد آزمایش ، محک و مجدداً یکپارچه شده است-اجازه پالایش مداوم بر اساس نتایج واقعی و نه اهداف استاتیک.
شاید مهمتر از همه ، Alphaevolve نمونه اولیه بهبودی بازگشتی باشد-جایی که یک سیستم هوش مصنوعی نه تنها می آموزد بلکه مؤلفه های خود را تقویت می کند. در چندین مورد ، Alphaevolve زیرساخت های آموزشی را که از مدلهای بنیاد خود پشتیبانی می کند ، بهبود بخشید. اگرچه هنوز هم با معماری های فعلی محدود است ، این قابلیت سابقه ای را تعیین می کند. با وجود مشکلات بیشتر در محیط های قابل ارزیابی ، Alphaevolve می تواند به سمت رفتار فزاینده ای پیشرفته و بهینه سازی کننده-یک ویژگی اساسی از سرپرستی مصنوعی (ASI) باشد.
محدودیت ها و مسیر آینده
محدودیت فعلی Alphaevolve وابستگی آن به توابع ارزیابی خودکار است. این امر ابزار خود را به مشکلاتی که می توانند از نظر ریاضی یا الگوریتمی رسمیت پیدا کنند ، محدود می کند. هنوز نمی تواند در حوزه هایی که نیاز به درک ضمنی انسان ، قضاوت ذهنی یا آزمایش فیزیکی دارند ، به طور معناداری عمل کند.
با این حال ، دستورالعمل های آینده عبارتند از:
- ادغام ارزیابی ترکیبی: ترکیب استدلال نمادین با ترجیحات انسانی و انتقادات به زبان طبیعی.
- استقرار در محیط های شبیه سازی ، امکان آزمایش علمی تجسم یافته.
- تقطیر خروجی های تکامل یافته به LLM های پایه ، ایجاد مدل های بنیادی توانمندتر و کارآمدتر.
این مسیرها به سمت سیستمهای فزاینده عامل قادر به حل مسئله خودمختار و با جمع آوری هستند.
پایان
Alphaevolve یک قدم عمیق به جلو است – نه فقط در ابزار هوش مصنوعی بلکه در درک ما از هوش دستگاه. با ادغام جستجوی تکاملی با استدلال و بازخورد LLM ، تعریف می کند که چه ماشینهایی می توانند به صورت خودمختار کشف کنند. این یک سیگنال زودهنگام اما مهم است که سیستم های خودآموزی قادر به تفکر علمی واقعی دیگر نظری نیستند.
با نگاهی به جلو ، معماری که زیربنای Alphaevolve است می تواند به صورت بازگشتی برای خودش اعمال شود: در حال تحول ارزیاب های خود ، بهبود منطق جهش ، پالایش عملکردهای امتیاز دهی و بهینه سازی خطوط لوله آموزشی اساسی برای مدلهایی که به آن بستگی دارد. این حلقه بهینه سازی بازگشتی یک مکانیسم فنی برای بوت شدن به سمت AGI را نشان می دهد ، جایی که سیستم صرفاً کارها را انجام نمی دهد بلکه زیرساخت هایی را که امکان یادگیری و استدلال آن را فراهم می کند ، بهبود می بخشد.
با گذشت زمان ، همانطور که Alphaevolve در حوزه های پیچیده تر و انتزاعی تر مقیاس می یابد – و با مداخله انسان در این فرآیند کاهش می یابد – ممکن است سودهای هوشمندانه ای را نشان دهد. این چرخه تقویت کننده خود از پیشرفت تکراری ، نه تنها در مورد مشکلات خارجی بلکه از درون به ساختار الگوریتمی خاص خود اعمال می شود ، یک مؤلفه مهم نظری است AGI و تمام مزایایی که می تواند جامعه را فراهم کندبشر Alphaevolve با ترکیب خلاقیت ، استقلال و بازگشت آن ممکن است صرفاً به عنوان یک محصول از در اعماق عمیق، اما به عنوان یک طرح برای اولین ذهن مصنوعی واقعاً عمومی و خود در حال تحول.