سیستم های مغزیپیشگام در محاسبات هوش مصنوعی با کارایی بالا، راه حلی پیشگامانه را معرفی کرده است که قرار است استنتاج هوش مصنوعی را متحول کند. در 27 آگوست 2024، این شرکت راه اندازی Cerebras Inference، سریع ترین سرویس استنتاج هوش مصنوعی در جهان را اعلام کرد. با معیارهای عملکردی که نسبت به سیستمهای مبتنی بر GPU سنتی کوچکتر است، Cerebras Inference سرعتی 20 برابر با کسری از هزینه ارائه میکند و معیار جدیدی را در محاسبات هوش مصنوعی ایجاد میکند.
سرعت بی سابقه و کارایی هزینه
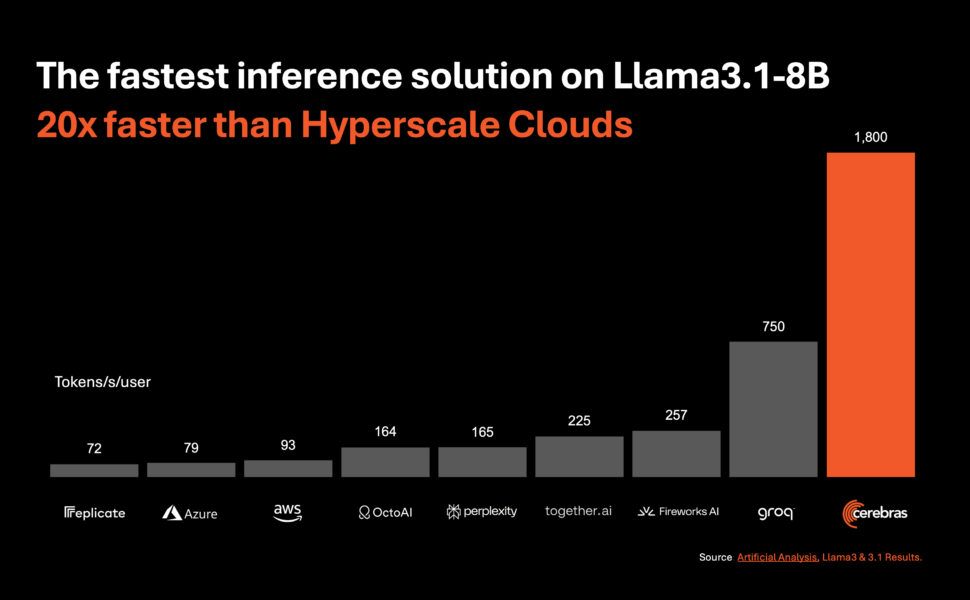
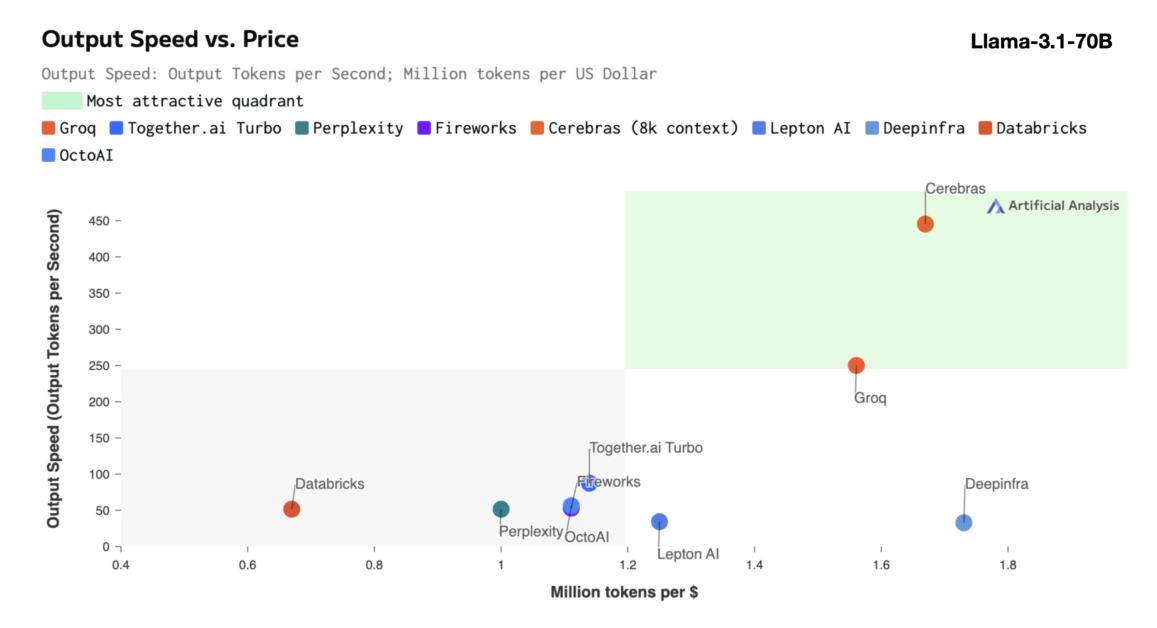
Cerebras Inference برای ارائه عملکرد استثنایی در مدل های مختلف هوش مصنوعی، به ویژه در بخش به سرعت در حال تکامل طراحی شده است. مدل های زبان بزرگ (LLMs). برای مثال، 1800 توکن در ثانیه برای مدل Llama 3.1 8B و 450 توکن در ثانیه برای مدل Llama 3.1 70B پردازش میکند. این عملکرد نه تنها 20 برابر سریعتر از راه حل های مبتنی بر GPU NVIDIA است، بلکه هزینه بسیار کمتری نیز دارد. Cerebras این سرویس را با شروع فقط 10 سنت در هر میلیون توکن برای مدل Llama 3.1 8B و 60 سنت در هر میلیون توکن برای مدل Llama 3.1 70B ارائه می دهد که نشان دهنده بهبود 100 برابری در قیمت عملکرد در مقایسه با ارائه های مبتنی بر GPU موجود است.
حفظ دقت هنگام فشار دادن مرزهای سرعت
یکی از چشمگیرترین جنبه های استنتاج Cerebras توانایی آن در حفظ دقت پیشرفته و در عین حال ارائه سرعت بی نظیر است. بر خلاف روشهای دیگر که دقت را قربانی سرعت میکنند، راهحل Cerebras در کل اجرای استنتاج در محدوده 16 بیتی باقی میماند. این تضمین میکند که دستاوردهای عملکردی به قیمت کیفیت خروجیهای مدل هوش مصنوعی، عاملی حیاتی برای توسعهدهندگانی که بر دقت تمرکز دارند، نباشد.
میکا هیل اسمیت، یکی از بنیانگذاران و مدیر عامل شرکت تحلیل مصنوعی، اهمیت این دستاورد را برجسته کرد:Cerebras سرعتهای مرتبهای سریعتر از راهحلهای مبتنی بر GPU برای مدلهای متا Llama 3.1 8B و 70B AI ارائه میکند. ما در Llama 3.1 8B سرعت بالای 1800 توکن خروجی در ثانیه و در Llama 3.1 70B بالاتر از 446 توکن خروجی در ثانیه اندازهگیری میکنیم – یک رکورد جدید در این معیارها.
اهمیت رو به رشد استنتاج هوش مصنوعی
استنتاج هوش مصنوعی سریعترین بخش محاسبات هوش مصنوعی است که تقریباً 40 درصد از کل بازار سخت افزار هوش مصنوعی را به خود اختصاص داده است. ظهور استنتاج هوش مصنوعی پرسرعت، مانند آنچه توسط Cerebras ارائه میشود، شبیه به معرفی اینترنت پهن باند است – فرصتهای جدید را باز میکند و عصر جدیدی را برای برنامههای کاربردی هوش مصنوعی نوید میدهد. با Cerebras Inference، توسعهدهندگان اکنون میتوانند نسل بعدی برنامههای هوش مصنوعی را بسازند که به عملکرد پیچیده و در زمان واقعی نیاز دارند، مانند عوامل هوش مصنوعی و سیستمهای هوشمند.
اندرو نگ، بنیانگذار DeepLearning.AI، بر اهمیت سرعت در توسعه هوش مصنوعی تاکید کرد:DeepLearning.AI دارای چندین گردش کار عاملی است که برای به دست آوردن نتیجه نیاز به درخواست مکرر یک LLM دارد. Cerebras یک قابلیت استنتاج بسیار سریع ایجاد کرده است که برای چنین حجم کاری بسیار مفید خواهد بود.”
حمایت از صنعت گسترده و مشارکت های استراتژیک
سربراس حمایت قوی از رهبران صنعت به دست آورده است و مشارکت های استراتژیک برای تسریع توسعه برنامه های کاربردی هوش مصنوعی تشکیل داده است. کیم برانسون، معاون AI/ML در GlaxoSmithKline، یکی از مشتریان اولیه Cerebras، بر پتانسیل تحولآفرین این فناوری تاکید کرد: “سرعت و مقیاس همه چیز را تغییر می دهد.”
شرکت های دیگر مانند LiveKit، گیجیو Meter نیز نسبت به تأثیری که Cerebras Inference بر عملیات آنها خواهد داشت ابراز اشتیاق کرده اند. این شرکتها از قدرت قابلیتهای محاسباتی Cerebras برای ایجاد تجربیات هوش مصنوعی انسانیمانندتر، بهبود تعامل با کاربر در موتورهای جستجو و بهبود سیستمهای مدیریت شبکه استفاده میکنند.
استنتاج مغزها: سطوح و دسترسی
Cerebras Inference در سه سطح با قیمت رقابتی در دسترس است: رایگان، توسعه دهنده و سازمانی. Free Tier دسترسی رایگان API را با محدودیتهای استفاده سخاوتمندانه فراهم میکند و آن را برای طیف گستردهای از کاربران در دسترس قرار میدهد. Developer Tier با مدل های Llama 3.1 با قیمت 10 سنت و 60 سنت به ازای هر میلیون توکن، گزینه ای انعطاف پذیر و بدون سرور را ارائه می دهد. رده Enterprise به سازمانهایی با حجم کاری پایدار پاسخ میدهد، مدلهای دقیق، توافقنامههای سطح خدمات سفارشی، و پشتیبانی اختصاصی را با قیمتگذاری در صورت درخواست ارائه میدهد.
قدرت استنتاج مغزها: موتور مقیاس ویفر 3 (WSE-3)
در قلب استنتاج Cerebras، سیستم Cerebras CS-3 قرار دارد که توسط موتور پیشرو در صنعت ویفر Scale Engine 3 (WSE-3) طراحی شده است. این پردازنده هوش مصنوعی از نظر اندازه و سرعت بی بدیل است و 7000 برابر پهنای باند حافظه بیشتر از H100 NVIDIA ارائه می دهد. مقیاس عظیم WSE-3 آن را قادر میسازد تا با بسیاری از کاربران همزمان کار کند و سرعت تاولآمیزی را بدون کاهش عملکرد تضمین میکند. این معماری به Cerebras اجازه میدهد تا از مبادلاتی که معمولاً سیستمهای مبتنی بر GPU را آزار میدهند کنار بگذارد و بهترین عملکرد را برای بارهای کاری هوش مصنوعی ارائه دهد.
یکپارچه سازی یکپارچه و API مناسب برای توسعه دهندگان
Cerebras Inference با در نظر گرفتن توسعه دهندگان طراحی شده است. دارای یک API است که کاملاً با OpenAI Chat Completions API سازگار است و امکان انتقال آسان با حداقل تغییرات کد را فراهم می کند. این رویکرد پسند توسعهدهنده تضمین میکند که ادغام Cerebras Inference در جریانهای کاری موجود تا حد امکان یکپارچه است و امکان استقرار سریع برنامههای هوش مصنوعی با کارایی بالا را فراهم میکند.
سیستم های مغزی: هدایت نوآوری در سراسر صنایع
Cerebras Systems نه تنها یک پیشرو در محاسبات هوش مصنوعی است، بلکه یک بازیگر کلیدی در صنایع مختلف از جمله مراقبت های بهداشتی، انرژی، دولت، محاسبات علمی و خدمات مالی است. راهحلهای این شرکت در ایجاد پیشرفتها در مؤسساتی مانند آزمایشگاههای ملی، الف آلفا، کلینیک مایو و گلاکسو اسمیتکلاین مؤثر بوده است.
با ارائه سرعت، مقیاسپذیری و دقت بینظیر، Cerebras سازمانها را در این بخشها قادر میسازد تا با برخی از چالشبرانگیزترین مشکلات در هوش مصنوعی و فراتر از آن مقابله کنند. چه در جهت تسریع کشف دارو در مراقبت های بهداشتی و چه افزایش قابلیت های محاسباتی در تحقیقات علمی، Cerebras در خط مقدم نوآوری است.
نتیجه گیری: عصر جدیدی برای استنتاج هوش مصنوعی
Cerebras Systems با راه اندازی Cerebras Inference استاندارد جدیدی برای استنتاج هوش مصنوعی تعیین می کند. Cerebras با ارائه 20 برابر سرعت سیستم های مبتنی بر GPU سنتی با کسری از هزینه، نه تنها هوش مصنوعی را در دسترس تر می کند، بلکه راه را برای نسل بعدی برنامه های کاربردی هوش مصنوعی هموار می کند. Cerebras با فناوری پیشرفته، مشارکت های استراتژیک و تعهد به نوآوری، آماده است تا صنعت هوش مصنوعی را به عصر جدیدی از عملکرد و مقیاس پذیری بی سابقه هدایت کند.
برای اطلاعات بیشتر در مورد سیستمهای مغزی و آزمایش استنتاج مغزی، به این سایت مراجعه کنید www.cerebras.ai.

