در این مقاله، یاد خواهید گرفت که چگونه یک ترانسفورماتور توکن های ورودی را به نمایش های زمینه و در نهایت احتمالات توکن بعدی تبدیل می کند.
موضوعاتی که به آنها خواهیم پرداخت عبارتند از:
- نحوه توکنسازی، ادغامها و اطلاعات مکان، ورودیها را آماده میکند
- چه شبکه های توجه و بازخورد چند جهتی در هر لایه مشارکت می کنند
- چگونه طرح نهایی و سافت مکس احتمالات توکن بعدی را تولید می کنند
بیایید سفر خود را شروع کنیم.
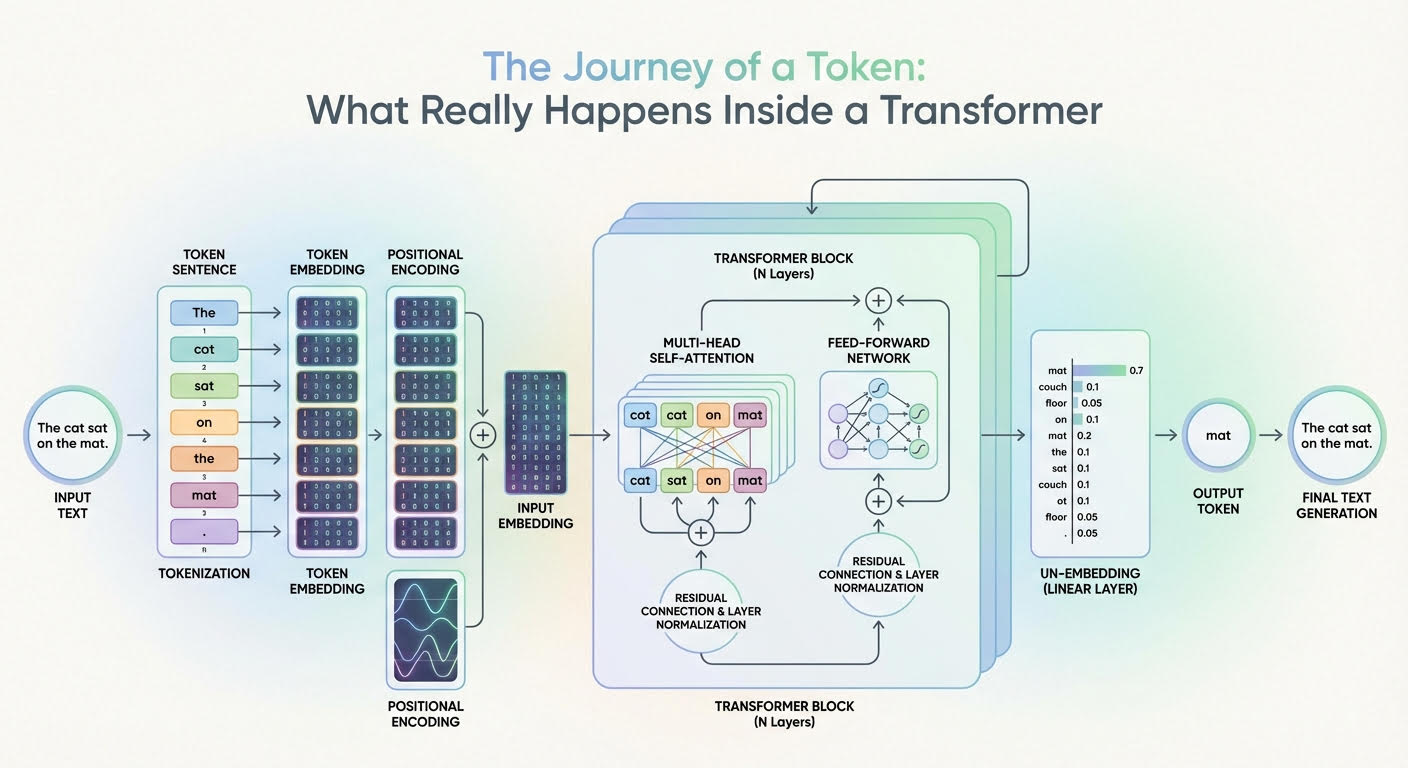
سفر یک نشانه: آنچه واقعا در داخل یک ترانسفورماتور اتفاق می افتد (برای بزرگنمایی کلیک کنید)
تصویر توسط ناشر
سفر آغاز می شود
مدل های زبان بزرگ (LLM) بر اساس معماری ترانسفورماتور، یک شبکه عصبی عمیق پیچیده است که ورودی آن دنبالهای از جاسازیهای نشانه است. پس از یک فرآیند عمیق – که به نظر می رسد یک رژه از توجه و تحولات بازخورد زیادی است – یک توزیع احتمال ایجاد می کند که نشان می دهد کد بعدی باید به عنوان بخشی از پاسخ مدل تولید شود. اما چگونه می توانیم این مسیر را از ورودی به خروجی برای یک توکن در دنباله ورودی توضیح دهیم؟
در این مقاله، آنچه را که در داخل یک مدل ترانسفورماتور (معماری پشت LLM) در سطح توکن اتفاق میافتد، یاد خواهید گرفت. به عبارت دیگر، خواهیم دید که چگونه نشانههای ورودی یا بخشهایی از یک دنباله متن ورودی به خروجیهای متن تولید شده تبدیل میشوند و همچنین دلیل تغییرات و تبدیلهایی که در داخل ترانسفورماتور رخ میدهند، میشوند.
شرح این سفر از طریق یک مدل ترانسفورماتور با نمودار بالا هدایت می شود که یک معماری عمومی ترانسفورماتور و چگونگی جریان و تکامل اطلاعات از طریق آن را نشان می دهد.
ورود به ترانسفورماتور: از متن ورودی خام تا جاسازی ورودی
قبل از وارد شدن به اعماق مدل ترانسفورماتور، برخی از دگرگونی ها قبلاً در ورودی متن رخ می دهد، عمدتاً به طوری که به شکلی کاملاً قابل درک توسط لایه های داخلی ترانسفورماتور نشان داده می شود.
توکن سازی
توکنایزر یک جزء الگوریتمی است که عموماً در همزیستی با مدل ترانسفورماتور LLM عمل می کند. دنباله ای از متن ساده، به عنوان مثال درخواست کاربر، را می گیرد و آن را به نشانه های گسسته (اغلب واحدهای زیر کلمه یا بایت ها، گاهی اوقات کلمات کامل)، با هر کد زبان مبدأ به یک شناسه نگاشت تقسیم می کند. من.
ادغام توکن
یک جدول ادغام آموخته شده وجود دارد E با شکل |V| × d (اندازه واژگان بر اساس بعد ادغام). یافتن شناسه های یک دنباله طولی n یک ماتریس ادغام می دهد X با شکل n × d. یعنی هر شناسه توکن به a نگاشت می شود د-بردار تعبیه بعدی که یک ردیف از X. دو بردار تعبیه شده اگر با نشانه هایی با معانی مشابه مرتبط باشند، به عنوان مثال پادشاه و امپراتور، یا برعکس، مشابه خواهند بود. توجه به این نکته ضروری است که در این مرحله، هر جاسازی نشانه حاوی اطلاعات معنایی و واژگانی برای آن نشانه واحد است، بدون اینکه اطلاعاتی در مورد بقیه دنباله جاسازی شود (حداقل هنوز).
رمزگذاری موقعیت
قبل از ورود کامل به قسمت های مرکزی ترانسفورماتور، لازم است به هر بردار تعبیه توکن، یعنی داخل هر ردیف از ماتریس تعبیه، تزریق شود. X – اطلاعات مربوط به موقعیت این نشانه در دنباله. این تزریق اطلاعات موقعیتی نیز نامیده می شود و معمولاً با توابع مثلثاتی مانند سینوس و کسینوس انجام می شود، اگرچه تکنیک هایی نیز بر اساس ادغام موقعیتی آموخته شده وجود دارد. یک جزء تقریباً باقیمانده به بردار ادغام قبلی اضافه می شود e_t مرتبط با یک توکن، به شرح زیر:
\[
x_t^{(0)} = e_t + p_{\text{pos}}
با p_pos
حالا وقت آن است که وارد اعماق ترانسفورماتور شوید و ببینید داخل آن چه خبر است!
در قلب ترانسفورماتور: از ادغام ورودی تا احتمالات خروجی
بیایید توضیح دهیم که برای هر یک از بردارهای تعبیه شده "غنی شده" در هنگام عبور از لایه ترانسفورماتور چه اتفاقی می افتد، سپس برای توصیف آنچه در کل پشته لایه ها اتفاق می افتد، بزرگنمایی کنیم.
فرمول
\[
h_t^{(0)} = x_t^{(0)}
\]
برای نشان دادن نمایش یک نشانه در سطح 0 (لایه اول) استفاده می شود، در حالی که به طور کلی تر از آن استفاده خواهیم کرد ht(l) برای نشان دادن نمایش جاسازی توکن در لایه من.
مراقب چندین سر باشید
اولین جزء اصلی در داخل هر لایه تکرار شده ترانسفورماتور است مراقب چندین سر باشید. این مسلماً تأثیرگذارترین مؤلفه کل معماری در هنگام شناسایی و گنجاندن اطلاعات معنادار زیادی در مورد نقش آن در کل دنباله و روابط آن با سایر نشانههای متن، اعم از نحوی، معنایی، یا هر نوع رابطه زبانی دیگر به میان میآید. سرهای متعدد این به اصطلاح مکانیسم توجه، هر کدام در گرفتن همزمان جنبه ها و الگوهای زبانی مختلف نشانه و کل دنباله ای که به آن تعلق دارد، تخصص دارند.
نتیجه داشتن یک بازنمایی نمادین ht(l) (با اطلاعات موقعیت تزریق شده است پیشینیبه یاد داشته باشید!) سفر از طریق این توجه چند سر در داخل یک لایه، یک نمایش نشانه غنی شده یا آگاه از زمینه است. با استفاده از اتصالات باقیمانده و نرمال سازی لایه ها در سراسر لایه ترانسفورماتور، بردارهای تازه تولید شده به مخلوط تثبیت شده ای از نمایش های قبلی خود و خروجی توجه چند سر تبدیل می شوند. این به بهبود سازگاری در طول فرآیند کمک می کند، که به طور مکرر در سراسر لایه ها اعمال می شود.
شبکه عصبی فید فوروارد
بعد چیزی نسبتاً کمتر پیچیده می آید: چند شبکه عصبی پیشخور (FFN). به عنوان مثال، اینها می توانند پرسپترون های چند لایه (MLP) در هر نشانه باشند که هدف آنها تغییر و اصلاح بیشتر ویژگی های نشانه هایی است که به تدریج آموخته می شوند.
تفاوت اصلی بین مرحله توجه و این در این است که توجه، اطلاعات متنی از همه نشانهها را در هر بازنمایی نشانهای ترکیب و ترکیب میکند، اما مرحله FFN بهطور مستقل بر روی هر نشانه اعمال میشود، و مدلهای بافت از قبل یکپارچهشده را برای استخراج «دانش» مفید اصلاح میکند. این لایه ها همچنین با اتصالات باقیمانده و نرمال سازی لایه ها تکمیل می شوند و از طریق این فرآیند در انتهای یک لایه ترانسفورماتور یک نمایش به روز شده داریم. ht(l+1) که به ورودی لایه ترانسفورماتور بعدی تبدیل می شود و بنابراین وارد بلوک توجه چند سر دیگری می شود.
کل فرآیند به تعداد لایههای انباشته تعریف شده در معماری ما تکرار میشود، بنابراین به تدریج توکن جاسازی شده با اطلاعات زبانی سطح بالاتر، انتزاعی و دوربرد در پشت این اعداد به ظاهر غیرقابل کشف غنی میشود.
مقصد نهایی
پس در نهایت چه اتفاقی می افتد؟ در بالای پشته، پس از عبور از آخرین لایه ترانسفورماتور تکرار شده، یک نمایش نهایی از نشانه دریافت می کنیم. ht*(L) (یا t* موقعیت پیش بینی فعلی را نشان می دهد) که از طریق a پیش بینی می شود لایه خروجی خطی به دنبال آن a سافت مکس.
لایه خطی امتیازهای غیر عادی ایجاد می کند که به آن می گویند لوجیت هاو softmax این logit ها را به احتمالات توکن بعدی تبدیل می کند.
محاسبه لجیت:
\[
\text{logits}_j = W_{\text{vocab}, j} \cdot h_{t^*}^{(L)} + b_j
\]
استفاده از softmax برای محاسبه احتمالات نرمال شده:
\[
\text{softmax}(\text{logits})_j = \frac{\exp(\text{logits}_j)}{\sum_{k} \exp(\text{logits}_k)}
\]
استفاده از خروجی های سافت مکس به عنوان احتمالات توکن بعدی:
\[
P(\text{token} = j) = \text{softmax}(\text{logits})_j
\]
این احتمالات برای تمام نشانه های ممکن در واژگان محاسبه می شود. سپس توکن بعدی تولید شده توسط LLM انتخاب میشود - اغلب یکی با بالاترین احتمال، اگرچه استراتژیهای رمزگشایی مبتنی بر نمونهبرداری نیز رایج هستند.
پایان سفر
این مقاله در سطح کمی از جزئیات فنی، معماری ترانسفورماتور را بررسی کرده است تا درک کلی از آنچه برای متن ارائه شده به یک LLM - مهمترین مدل مبتنی بر معماری ترانسفورماتور - اتفاق میافتد و نحوه پردازش و تبدیل این متن در داخل مدل در سطح نشانه برای در نهایت تبدیل به خروجی یک مدل ارائه دهد: کلمه بعدی که باید تولید شود.
امیدواریم از سفرهای مشترک ما لذت برده باشید و مشتاقانه منتظر فرصتی هستیم تا در آینده نزدیک سفر دیگری را آغاز کنیم.