در این مقاله، پنج تکنیک فشرده سازی سریع عملی را خواهید آموخت که توکن ها را کاهش می دهد و تولید مدل های زبان بزرگ (LLM) را بدون کاهش کیفیت کار تسریع می بخشد.
موضوعاتی که به آنها خواهیم پرداخت عبارتند از:
- خلاصه معنایی چیست و چه زمانی باید از آن استفاده کرد
- چگونه درخواستهای ساختاریافته، فیلتر مربوطه، و سئوی دستورالعملها تعداد توکنها را کاهش میدهند
- انتزاع مدل کجا مناسب است و چگونه آن را به طور مداوم اعمال کنیم
بیایید این تکنیک ها را بررسی کنیم.
فشرده سازی سریع برای بهینه سازی تولید LLM و کاهش هزینه
تصویر توسط ناشر
مقدمه
مدل های زبان بزرگ (LLM) اصولاً برای ایجاد پاسخهای متنی به درخواستها یا درخواستهای کاربر، با استدلال پیچیده که نه تنها شامل تولید زبان با پیشبینی هر نشانه بعدی در دنباله خروجی میشود، بلکه شامل درک عمیق الگوهای زبانی پیرامون ورودی متن توسط کاربر است.
فشرده سازی سریع این تکنیک ها یک موضوع تحقیقاتی هستند که اخیراً در چشم انداز LLM به دلیل نیاز به کاهش استنتاج آهسته و وقت گیر ناشی از درخواست های بزرگتر کاربر و پنجره های بازشو مورد توجه قرار گرفته است. این تکنیک ها برای کمک به کاهش استفاده از توکن، سرعت بخشیدن به تولید توکن و کاهش هزینه های محاسباتی کلی طراحی شده اند و در عین حال کیفیت نتیجه کار را تا حد امکان حفظ می کنند.
این مقاله پنج تکنیک فشرده سازی سریع را که معمولاً مورد استفاده قرار می گیرد برای تسریع تولید LLM در سناریوهای چالش برانگیز معرفی و توصیف می کند.
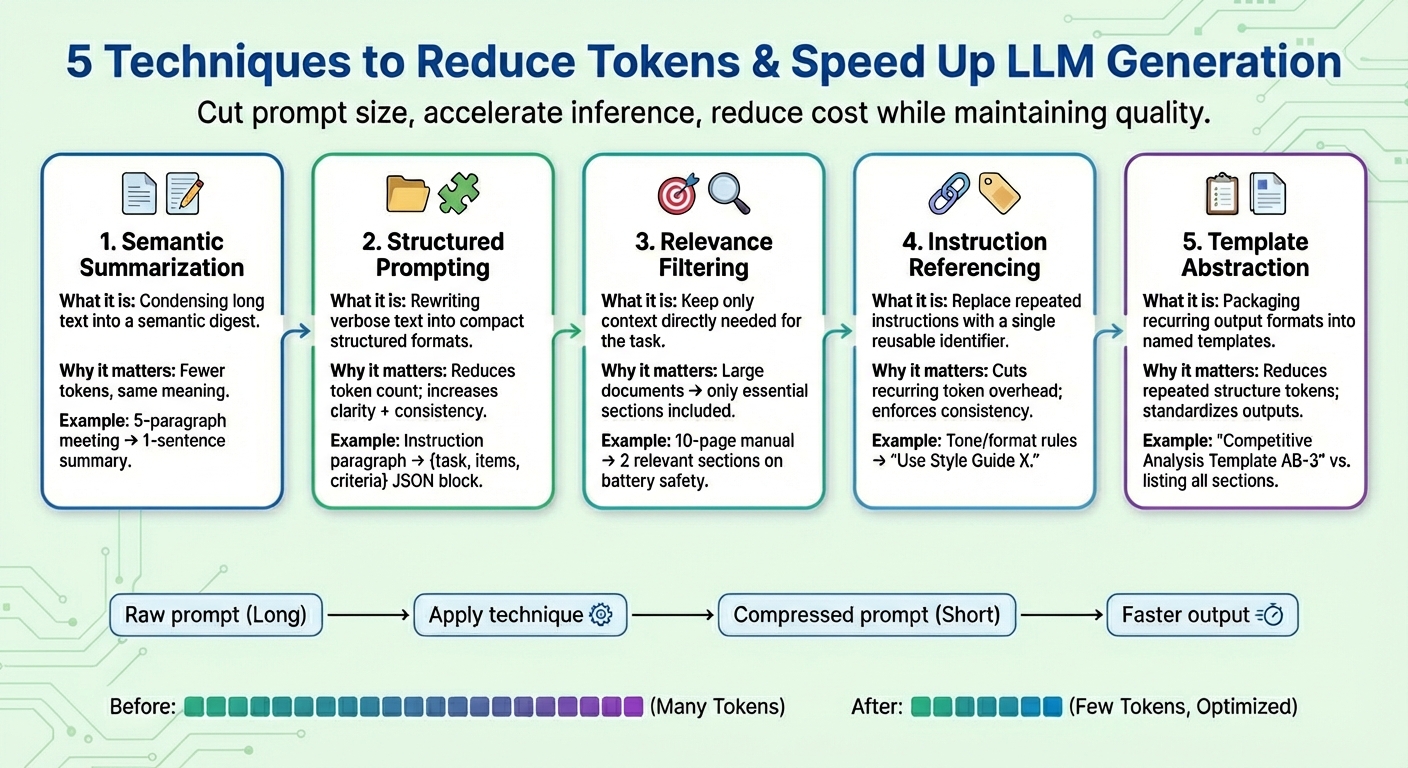
1. خلاصه معنایی
خلاصهسازی معنایی تکنیکی است که محتوای طولانی یا تکراری را در نسخهای مختصرتر فشرده میکند و در عین حال معنای اساسی خود را حفظ میکند. به جای ارسال مکرر کل مکالمه یا اسناد متنی به مدل، خلاصه ای که فقط شامل موارد ضروری است منتقل می شود. نتیجه: تعداد نشانههای ورودی که مدل باید بخواند کاهش مییابد، در نتیجه روند تولید توکن بعدی را سرعت میبخشد و هزینهها را بدون از دست دادن اطلاعات کلیدی کاهش میدهد.
یک زمینه طولانی و سریع متشکل از صورتجلسات جلسه را فرض کنید، مانند «در جلسه دیروز، ایوان ارقام فصلی را بررسی کرد…“، خلاصه کردن حداکثر پنج پاراگراف. پس از یک خلاصه معنایی، متن کوتاه شده ممکن است شبیه به “خلاصه: ایوان ارقام سه ماهه را بررسی کرد، کاهش فروش در سه ماهه چهارم را برجسته کرد و اقدامات کاهش هزینه را پیشنهاد کرد.»
2. اعلان ساختاریافته (JSON)
این تکنیک بر بیان تکههای طولانی و روان اطلاعات متنی در قالبهای فشرده و نیمهساختار یافته مانند JSON (یعنی جفتهای کلید-مقدار) یا یک لیست گلوله تمرکز دارد. قالبهای هدف مورد استفاده برای درخواستهای ساختاریافته معمولاً شامل کاهش تعداد نشانهها میشوند. این به مدل کمک میکند تا دستورالعملهای کاربر را با اطمینان بیشتری تفسیر کند و بنابراین، سازگاری مدل را بهبود میبخشد و ابهام را کاهش میدهد در حالی که درخواستها را در طول مسیر کاهش میدهد.
الگوریتمهای اعلان ساختیافته میتوانند اعلانهای خام را با دستورالعملهایی مانند تغییر شکل دهند لطفاً مقایسه دقیقی بین محصول X و محصول Y با تمرکز بر قیمت، ویژگیهای محصول و نظرات مشتریان ارائه دهید. در یک فرم ساختار یافته مانند: {وظیفه: “مقایسه”، عناصر: [“Product X”, “Product Y”]معیارها: [“price”, “features”, “ratings”]}
3. فیلتر کردن بر اساس ارتباط
فیلتر ارتباط، اصل «تمرکز بر آنچه واقعاً مهم است» را اعمال میکند: ارتباط بخشهای خاصی از متن را اندازهگیری میکند و تنها آن عناصری از زمینه را که واقعاً با کار مورد نظر مرتبط هستند، در پیام نهایی ادغام میکند. به جای حذف کل اطلاعات، مانند اسنادی که بخشی از زمینه هستند، تنها زیرمجموعه های کوچکی از اطلاعات که بیشتر مرتبط با پرس و جوی هدف هستند حفظ می شوند. این روش دیگری برای کاهش قابل توجه اندازه اعلانها و کمک به عملکرد بهتر مدل از نظر تمرکز و بهبود دقت پیشبینی است (به یاد داشته باشید که تولید توکن LLM، در اصل، یک کار پیشبینی کلمه بعدی است که چندین بار تکرار میشود).
به عنوان مثال، یک کتابچه راهنمای کامل محصول 10 صفحه ای برای تلفن همراه را در نظر بگیرید که به عنوان پیوست اضافه شده است (زمینه فوری). پس از اعمال فیلتر مربوطه، تنها چند بخش کوتاه مربوط به “عمر باتری” و “فرایند شارژ” حفظ می شود، زیرا کاربر از پیامدهای ایمنی هنگام شارژ دستگاه مطلع شده است.
4. دستورالعمل های ارجاع
بسیاری از درخواستها همان نوع دستورالعملها را بارها و بارها تکرار میکنند، مانند «این لحن را بگیرید»، «در این قالب پاسخ دهید» یا «از جملات مختصر استفاده کنید»، به نام چند. ارجاع دستورالعمل، یک مرجع برای هر دستورالعمل رایج (شامل مجموعه ای از نشانه ها) ایجاد می کند، هر یک را فقط یک بار ذخیره می کند، و مجدداً از آن به عنوان یک شناسه نشانه منحصر به فرد استفاده می کند. هر زمان که درخواست های آینده یک “درخواست مشترک” ثبت شده را ذکر کنند، از این شناسه استفاده می شود. علاوه بر کوتاه کردن اعلانها، این استراتژی همچنین به حفظ رفتار ثابت در طول زمان کمک میکند.
مجموعه ای ترکیبی از دستورالعمل ها مانند “با لحن دوستانه بنویسید. از اصطلاحات خاص خودداری کنید. جملات را مختصر نگه دارید. مثال هایی ارائه دهید.” را می توان به “استفاده از راهنمای سبک X” ساده کرد. و پس از مشخص شدن مجدد دستورالعمل های معادل، دوباره مورد استفاده قرار گیرد.
5. انتزاع مدل
برخی از الگوها یا دستورالعملها اغلب در دستورات ظاهر میشوند، برای مثال ساختارهای گزارش، قالبهای ارزیابی، یا روشهای گام به گام. انتزاع مدل یک اصل مشابه را برای ارجاع به بیانیه اعمال می کند، اما بر شکل و قالبی که خروجی تولید شده باید داشته باشد، با کپسوله کردن این مدل های رایج تحت نام مدل، تمرکز می کند. سپس از ارجاع مدل استفاده می شود و LLM وظیفه پر کردن بقیه اطلاعات را بر عهده می گیرد. این نه تنها به شفافتر ماندن اعلانها کمک میکند، بلکه حضور توکنهای مکرر را نیز تا حد زیادی کاهش میدهد.
پس از انتزاع مدل، یک درخواست را می توان به چیزی مانند “تولید یک تحلیل رقابتی با استفاده از مدل AB-3” تبدیل کرد. که در آن AB-3 لیستی از بخش های محتوای درخواست شده برای تجزیه و تحلیل است که هر کدام به وضوح تعریف شده اند. چیزی شبیه به:
یک تحلیل رقابتی در چهار بخش تولید کنید:
- بررسی اجمالی بازار (2-3 پاراگراف که روندهای صنعت را خلاصه می کند)
- توزیع رقیب (جدول مقایسه حداقل 5 رقیب)
- نقاط قوت و ضعف (نقاط گلوله)
- توصیه های استراتژیک (3 مرحله قابل دستیابی).
نتیجه گیری
این مقاله پنج روش متداول را برای سرعت بخشیدن به تولید LLM در سناریوهای دشوار با فشردهسازی اعلانهای کاربر، که اغلب بر بخش متنی آنها متمرکز میشود، ارائه و توصیف میکند، که اغلب علت اصلی «اعلانهای بیش از حد» است که باعث کاهش سرعت LLM میشود.