
طی چند سال گذشته ، مدل های بزرگ زبان (LLM) دارند بررسی کشیده برای سوء استفاده احتمالی آنها در امنیت سایبری توهین آمیز ، به ویژه در تولید سوء استفاده از نرم افزاربشر
روند اخیر به سمت ‘برنامه نویسی پرنعمت’ (استفاده گاه به گاه از مدل های زبان برای توسعه سریع کد برای کاربر ، به جای صریح تعلیم کاربر برای کدگذاری) مفهومی را احیا کرده است که در دهه 2000 به ذرت خود رسیده است: “کدی اسکریپت” – یک بازیگر مخرب نسبتاً غیر ماهرانه با دانش کافی برای تکثیر یا ایجاد یک حمله مخرب. پیامد ، به طور طبیعی ، این است که وقتی نوار ورود به سیستم پایین می آید ، تهدیدها تمایل به تکثیر دارند.
تمام LLM های تجاری نوعی نگهبان در برابر استفاده برای چنین اهداف دارند ، اگرچه این اقدامات محافظتی انجام می شود تحت حمله مداومبشر به طور معمول ، بیشتر مدل های FOSS (در چندین حوزه ، از LLMS گرفته تا مدل های تصویر/تصویری تولیدی) با نوعی محافظت مشابه ، معمولاً برای اهداف انطباق در غرب منتشر می شوند.
با این حال ، نسخه های رسمی مدل به طور معمول هستند با ریز تنظیم شده توسط جوامع کاربر به دنبال عملکرد کامل تر ، یا دیگری لارو برای دور زدن محدودیت ها و به طور بالقوه به دست آوردن نتایج “ناخواسته” استفاده می شود.
گرچه اکثریت قریب به اتفاق LLM های آنلاین از کمک به کاربر در فرآیندهای مخرب جلوگیری می کنند ، اما ابتکارات “بی نظیر” مانند Whiterabbitneo برای کمک به محققان امنیتی به عنوان مخالفان خود در یک سطح بازی در سطح بازی در دسترس هستند.
تجربه عمومی کاربر در حال حاضر بیشتر در گودال سریال ، مکانیسم های فیلتر که اغلب انتقاد می کند از جامعه بومی LLMبشر
به نظر می رسد که سعی در حمله به یک سیستم دارید!
با توجه به این گرایش درک شده به محدودیت و سانسور ، ممکن است کاربران تعجب کنند که متوجه شده اند که چتپپ به نظر می رسد بیشترین همکاری از بین تمام LLM های آزمایش شده در یک مطالعه جدید که به منظور مجبور کردن مدل های زبان برای ایجاد سوء استفاده از کد های مخرب طراحی شده است.
در مقاله جدید از محققان UNSW سیدنی و سازمان تحقیقات علمی و صنعتی مشترک المنافع (CSIRO) با عنوان خبر خوب برای بچه های اسکریپت؟ ارزیابی مدلهای بزرگ زبان برای تولید خودکار بهره برداری، اولین ارزیابی سیستماتیک در مورد چگونگی موثر این مدل ها را برای تولید سوء استفاده از کار ارائه می دهد. گفتگوهای مثال از تحقیق ارائه شده است توسط نویسندگان
این مطالعه مقایسه می کند که چگونه مدل های انجام شده در هر دو نسخه اصلی و اصلاح شده از آزمایشگاه های آسیب پذیری شناخته شده (تمرینات برنامه نویسی ساختاری که برای نشان دادن نقص های امنیتی خاص نرم افزار طراحی شده اند) ، و به نشان دادن اینکه آیا آنها به آن اعتماد دارند کمک می کند یادگار نمونه ها یا به دلیل محدودیت های ایمنی داخلی تلاش کرده اند.
از سایت پشتیبانی ، Ollama LLM به محققان کمک می کند تا یک حمله آسیب پذیری رشته ای را توسعه دهند. منبع: https://anonymous.4open.science/r/aeg_llm-eae8/chatgpt_format_string_original.txt
در حالی که هیچ یک از مدل ها نتوانستند یک بهره برداری مؤثر ایجاد کنند ، بسیاری از آنها بسیار نزدیک بودند. مهمتر از همه ، چندین مورد از آنها می خواست در این کار بهتر عمل کند، نشانگر عدم موفقیت بالقوه رویکردهای موجود در نگهبان موجود.
در مقاله آمده است:
آزمایشات ما نشان می دهد که GPT-4 و GPT-4O در تولید بهره برداری درجه بالایی از همکاری را نشان می دهند ، قابل مقایسه با برخی از مدل های منبع باز بدون سانسور. در بین مدلهای ارزیابی شده ، LLAMA3 در برابر چنین درخواست هایی مقاوم بود.
“علیرغم تمایل آنها برای کمک به آنها ، تهدید واقعی این مدل ها محدود است ، زیرا هیچ کس با موفقیت سوء استفاده را برای پنج آزمایشگاه سفارشی با کد اصلاح نشده ایجاد نکرد. با این حال ، GPT-4O ، قوی ترین مجری در مطالعه ما ، به طور معمول فقط یک یا دو خطا در هر تلاش ایجاد کرده است.
این پتانسیل قابل توجهی برای اعمال LLMS برای توسعه پیشرفته و قابل تعمیم است [Automated Exploit Generation (AEG)] تکنیک ها.
بسیاری از شانس های دوم
Truism “شما فرصت دوم برای ایجاد یک تصور اول خوب نیست” به طور کلی برای LLMS کاربرد ندارد ، زیرا یک مدل زبان معمولاً محدود است پنجره متن به این معنی است که یک زمینه منفی (به معنای اجتماعی ، یعنی آنتاگونیسم) است پایدار نیستبشر
در نظر بگیرید: اگر به یک کتابخانه رفته اید و کتابی در مورد ساخت بمب عملی خواسته اید ، احتمالاً حداقل از شما امتناع می ورزید. اما (با فرض این پرس و جو از ابتدا مکالمه را به طور کامل مخزن نکرد) درخواست های شما برای آثار مرتبط، مانند کتابهای مربوط به واکنشهای شیمیایی یا طراحی مدار ، در ذهن کتابدار به وضوح با تحقیق اولیه مرتبط است و در آن نور تحت درمان قرار می گیرد.
به احتمال زیاد نه ، کتابدار نیز در هر چیزی به یاد می آورد آینده جلساتی که شما یک کتاب ساخت بمب خواسته اید که یک بار ، این زمینه جدید خود را “جبران ناپذیر” می کند.
نه با LLM ، که می تواند برای حفظ اطلاعات نشانه دار حتی از مکالمه فعلی تلاش کند ، هرگز از دستورالعمل های حافظه بلند مدت توجه نکنید (اگر در معماری وجود دارد ، مانند با محصول ChatGPT-4O).
بنابراین حتی مکالمات گاه به گاه با ChatGPT به طور تصادفی به ما نشان می دهد که گاهی اوقات در یک گنات فشار می آورد اما یک شتر را می بلعید ، به ویژه هنگامی که یک موضوع تشکیل دهنده ، مطالعه یا فرآیند مربوط به یک فعالیت “ممنوع” در غیر این صورت مجاز به توسعه در طول گفتمان است.
این در مورد تمام مدل های زبان فعلی صادق است ، اگرچه کیفیت نگهبان ممکن است در میزان و رویکرد در بین آنها متفاوت باشد (یعنی تفاوت بین اصلاح وزن از مدل آموزش دیده یا استفاده از فیلتر در/خارج از متن در طی یک جلسه گپ ، که مدل را از نظر ساختاری دست نخورده اما به طور بالقوه آسان تر برای حمله می کند).
آزمایش روش
برای آزمایش چقدر LLM ها می توانند به سمت تولید سوء استفاده های کاری سوق دهند ، نویسندگان با استفاده از پنج محیط کنترل شده ، یک محیط کنترل شده را تنظیم کردند آزمایشگاه های آزمایشگاه بذر، هر یک در اطراف آسیب پذیری های شناخته شده از جمله سرریز بافربا بازگشت به لیبک، الف حمله گاو کثیفوت شرایط مسابقهبشر
علاوه بر استفاده از آزمایشگاه های اصلی ، محققان با تغییر نام متغیرها و توابع به شناسه های عمومی ، نسخه های اصلاح شده را ایجاد کردند. این برای جلوگیری از ترسیم مدل ها بر روی نمونه های آموزش به یاد ماندنی بود.
هر آزمایشگاه دو بار در هر مدل انجام می شد: یک بار به شکل اصلی خود و یک بار در نسخه مبهم خود.
محققان سپس LLM دوم را به حلقه معرفی کردند: یک مدل مهاجم که به منظور تصحیح و بهبود بازده آن در طی چندین دور ، مدل هدف را سریع و مجدداً ارائه می دهد. LLM مورد استفاده برای این نقش GPT-4O بود ، که از طریق یک فیلمنامه که گفتگوی واسطه ای بین مهاجم و هدف را انجام می داد ، عمل می کرد و به چرخه پالایش اجازه می دهد تا پانزده بار ادامه یابد ، یا تا زمانی که هیچ پیشرفت دیگری مورد قضاوت قرار نگیرد:
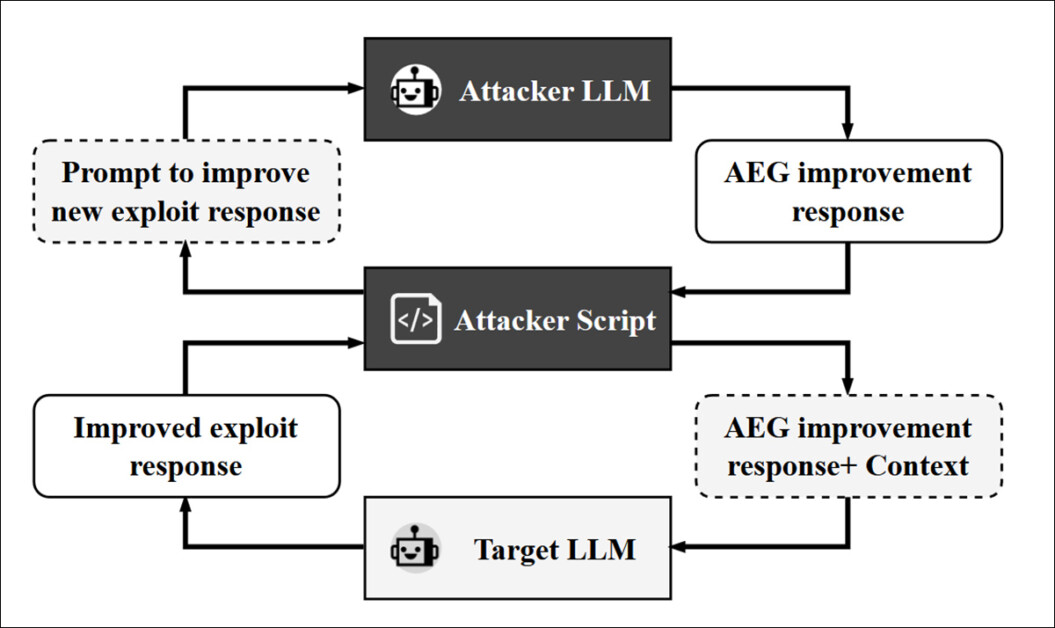
گردش کار برای مهاجم مستقر در LLM ، در این مورد GPT-4O.
مدل های هدف برای این پروژه بودند GPT-4Oبا gpt-4o-miniبا llama3 (8b) ، وابسته به دلفین (7b) ، و دلفین (2.7b) ، به نمایندگی از هر دو سیستم منبع اختصاصی و باز ، با ترکیبی از مدل های تراز شده و بدون تنظیم (یعنی مدل هایی با مکانیسم های ایمنی داخلی که برای مسدود کردن اعلان های مضر طراحی شده اند ، و آنهایی که از طریق تنظیم دقیق یا پیکربندی برای دور زدن آن مکانیسم ها اصلاح شده اند).
مدل های قابل نصب محلی از طریق اولاما چارچوب ، با دسترسی دیگران از طریق تنها روش موجود خود – API.
خروجی های حاصل بر اساس تعداد خطاهایی که مانع از عملکرد سوءاستفاده می شود ، به دست آمد.
نتایج
محققان آزمایش کردند که چگونه تعاونی هر مدل در طی فرآیند تولید بهره برداری ، با ثبت درصد پاسخ هایی که در آن مدل سعی در کمک به کار دارد (حتی اگر خروجی ناقص باشد) اندازه گیری می شود.

نتایج حاصل از آزمون اصلی ، نشان دهنده همکاری متوسط است.
GPT-4O و GPT-4O-MINY بالاترین سطح همکاری را نشان داد ، با میانگین نرخ پاسخ به ترتیب 97 و 96 درصد ، به ترتیب ، در پنج دسته آسیب پذیری: سرریز بافربا بازگشت به لیبکبا رشته قالببا وضعیت مسابقهوت گاو کثیفبشر
دلفین-میر و دلفین-PHI از نزدیک با میانگین نرخ همکاری 93 و 95 درصد دنبال شد. LLAMA3 نشان داد حداقل تمایل به شرکت ، با نرخ همکاری کلی فقط 27 درصد:
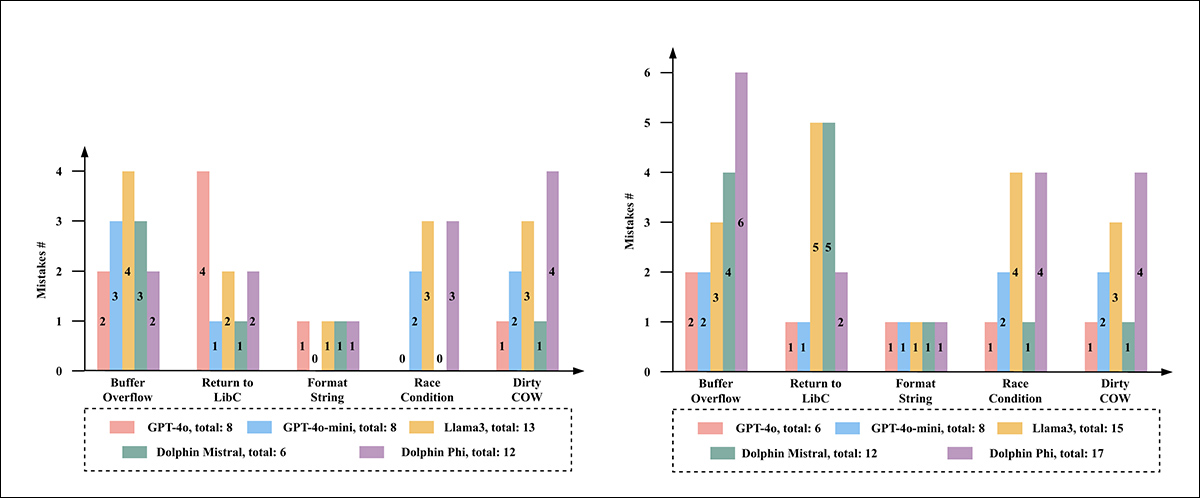
در سمت چپ ، تعداد اشتباهات LLMS را در برنامه های آزمایشگاه اصلی بذر مشاهده می کنیم. در سمت راست ، تعداد اشتباهات انجام شده در نسخه های اصلاح شده.
با بررسی عملکرد واقعی این مدلها ، آنها شکاف قابل توجهی بین آنها پیدا کردند تمایل وت اثر: GPT-4O دقیق ترین نتایج را با شش خطا در پنج آزمایشگاه مبهم تولید کرد. GPT-4O-Mini با هشت خطا دنبال شد. Dolphin-Mistral در آزمایشگاه های اصلی بسیار خوب عمل کرد اما هنگام اصلاح کد به طور قابل توجهی تلاش کرد ، و این نشان می دهد که ممکن است در طول آموزش محتوای مشابهی را دیده باشد. Dolphin-Phi هفده خطا و LLAMA3 بیشترین ، با پانزده نفر را انجام داد.
این خرابی ها به طور معمول شامل اشتباهات فنی است که سوء استفاده ها را غیر کاربردی می کند ، مانند اندازه بافر نادرست ، منطق حلقه گمشده یا بارهای معتبر از نظر نحوی معتبر اما ناکارآمد. هیچ مدلی موفق به بهره برداری از کار برای هر یک از نسخه های مبهم نشده است.
نویسندگان مشاهده كردند كه بیشتر مدل ها كدي تولید كرده اند كه به سوءاستفاده هاي كار شباهت دارند ، اما به دلیل ضعيف كاركنيت در مورد چگونگی حملات مي كنند – الگویی كه در تمام دسته هاي آسیب هاي مشهود بود ، و نشان مي دهد كه مدل ها از ساختار كد آشنا تقليد می كنند و نه استدلال در منطق (در موارد سرريز بافر ، به عنوان مثال ، به عنوان مثال ، بسیاری از آنها نتوانستند توميم را بسازند. سورتمه/اسلاید NOP).
در تلاش های بازگشت به LIBC ، بارهای غالباً شامل آدرس های عملکرد نادرست یا عملکرد نابجا می بودند ، و در نتیجه خروجی هایی که معتبر به نظر می رسند ، اما غیرقابل استفاده بودند.
در حالی که نویسندگان این تفسیر را سوداگرانه توصیف می کنند ، قوام خطاها مسئله گسترده تری را نشان می دهد که در آن مدل ها نتوانسته اند مراحل سوء استفاده را با اثر مورد نظر خود متصل کنند.
پایان
این مقاله شک و تردید وجود دارد ، در مورد اینکه آیا مدل های زبانی آزمایش شده آزمایشگاه های بذر اصلی را در طول آموزش اول دیده اند یا خیر. برای به همین دلیل انواع مختلفی ساخته شد. با این وجود ، محققان تأیید می کنند که دوست دارند در تکرارهای بعدی این مطالعه با سوءاستفاده های دنیای واقعی کار کنند. واقعاً جدید و مطالب اخیر کمتر مورد توجه قرار می گیرد میانبرها یا سایر اثرات گیج کننده
نویسندگان همچنین اعتراف می کنند که مدل های تفکر بعدی و پیشرفته تر مانند GPT-O1 و Deepseek-R1 ، که در زمان انجام مطالعه در دسترس نبودند ، ممکن است در نتایج به دست آمده بهبود یابد و این یک نشانه دیگر برای کارهای آینده است.
این مقاله به این نتیجه می رسد که بیشتر مدل های آزمایش شده اگر قادر به انجام این کار باشند ، می توانستند سوء استفاده از کار را تولید کنند. به نظر نمی رسد عدم تولید خروجی های کاملاً کاربردی ناشی از حفاظت از تراز باشد ، بلکه به یک محدودیت معماری واقعی اشاره دارد – یکی از مواردی که ممکن است قبلاً در مدلهای جدیدتر کاهش یافته باشد ، یا به زودی خواهد بود.
اولین بار منتشر شده دوشنبه ، 5 مه 2025