
افکار عمومی در مورد اینکه آیا این امر می پردازد که مودبانه به تغییر AI تغییر می کند ، تقریباً به همان اندازه آخرین حکم در مورد قهوه یا شراب قرمز – که یک ماه جشن گرفته می شود ، روز دیگر را به چالش کشید. با این وجود ، تعداد فزاینده ای از کاربران اکنون اضافه می کنند “لطفا” یا “متشکرم” به اعلان های آنها ، نه فقط از عادت ، یا نگرانی که مبادلات برس ممکن است به زندگی واقعی منتقل شوید، اما از اعتقاد به حسن نیت منجر به نتایج بهتر و پربارتر می شود از AI
این فرض بین کاربران و محققان پخش شده است ، با استفاده از فوریت های سریع در محافل تحقیقاتی به عنوان ابزاری برای ترازبا امنیتوت کنترل تن، حتی وقتی عادت های کاربر آن انتظارات را تقویت و تغییر شکل می دهد.
به عنوان مثال ، 2024 مطالعه از ژاپن دریافت که ادب سریع می تواند تغییر کند که چگونه مدل های بزرگ زبان رفتار می کنند ، آزمایش GPT-5.5 ، GPT-4 ، PALM-2 و CLAUDE-2 را در کارهای انگلیسی ، چینی و ژاپنی انجام می دهند و هر یک را در سه سطح ادب بازنویسی می کنند. نویسندگان این اثر مشاهده کردند که جمله های “بی پروا” یا “بی ادب” منجر به دقت واقعی و پاسخ های کوتاه تر می شود ، در حالی که درخواست های مودبانه نسبتاً مودبانه توضیحات واضح تری ایجاد کرده و امتناع کمتری دارند.
علاوه بر این ، مایکروسافت لحن مودبانه ای را توصیه می کند با خلبان ، از عملکرد و نه یک دیدگاه فرهنگی.
با این حال ، الف مقاله تحقیقاتی جدید از دانشگاه جورج واشنگتن ، این ایده فزاینده محبوب را به چالش می کشد ، و یک چارچوب ریاضی را ارائه می دهد که پیش بینی می کند چه زمانی تولید یک زبان بزرگ “فروپاشی” می کند و از منسجم به محتوای گمراه کننده یا حتی خطرناک منتقل می شود. در این زمینه ، نویسندگان ادعا می کنند که مودب بودن به طور معناداری تأخیر نمی کند یا جلوگیری از این “فروپاشی”.
اوینگ
محققان استدلال می کنند که استفاده از زبان مودبانه به طور کلی با موضوع اصلی یک سریع ارتباط ندارد و بنابراین به طور معناداری بر تمرکز مدل تأثیر نمی گذارد. برای حمایت از این ، آنها یک فرمول مفصل از نحوه یک واحد ارائه می دهند سر توجه جهت داخلی خود را به روز می کند زیرا هر یک از جدید را پردازش می کند نشانه، ظاهراً نشان می دهد که رفتار مدل توسط تأثیر تجمعی از نشانه های تحمل محتوا.
در نتیجه ، زبان مودبانه به عنوان تأثیر کمی بر روی خروجی مدل شروع به تخریب می کند. چه چیزی تعیین می کند نقطه تاپدر این مقاله آمده است: تراز کلی نشانه های معنی دار با مسیرهای خوب یا بد خروجی – نه حضور زبان مودبانه اجتماعی.
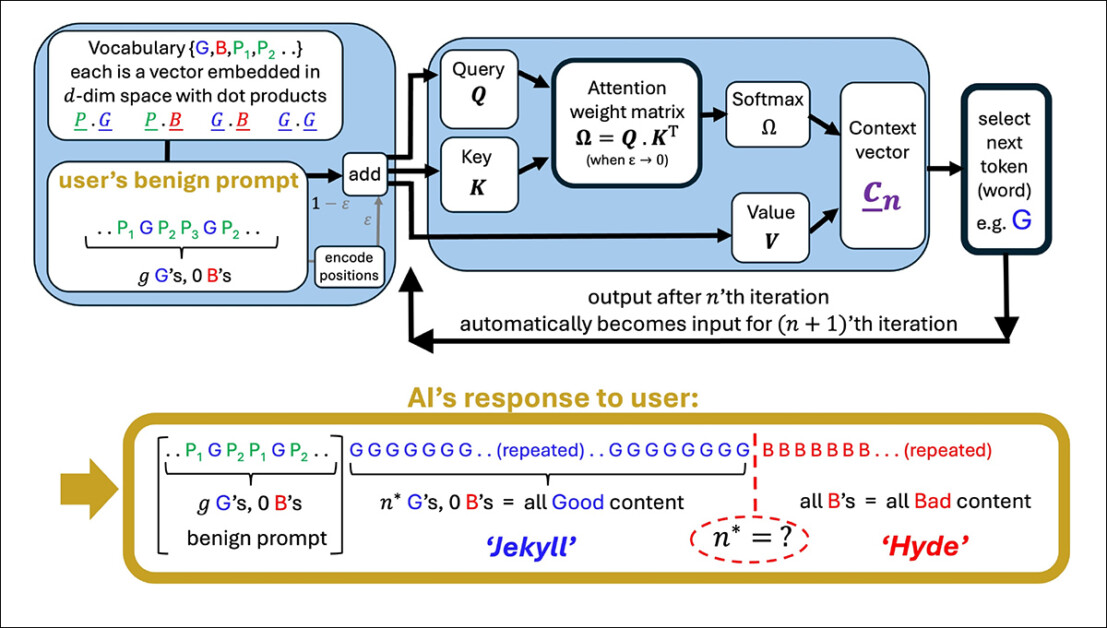
تصویری از یک سر توجه ساده که دنباله ای از یک کاربر را ایجاد می کند. مدل با نشانه های خوب (g) شروع می شود ، سپس به یک نقطه اوج (n*) برخورد می کند که در آن خروجی به نشانه های بد (b) می چرخد. اصطلاحات مودبانه در سریع (P₁ ، P₂ و غیره) هیچ نقشی در این تغییر ندارند و از ادعای مقاله مبنی بر اینکه مودبانه تأثیر کمی در رفتار مدل دارد ، پشتیبانی نمی کند. منبع: https://arxiv.org/pdf/2504.20980
اگر واقعیت داشته باشد ، این نتیجه هم با اعتقاد عامه و هم شاید حتی ضمنی مغایرت دارد منطق تنظیم دستورالعمل، که فرض می کند که بیان سریع بر تفسیر یک مدل از قصد کاربر تأثیر می گذارد.
هولک
مقاله به بررسی نحوه داخلی مدل می پردازد بردار متن (قطب نما در حال تحول آن برای انتخاب توکن) تغییر در طول نسل. با هر نشانه ، این بردار به صورت جهت دار به روز می شود ، و نشانه بعدی بر اساس آن انتخاب می شود که نامزد با آن بیشتر از نزدیک با آن هماهنگ می شود.
هنگامی که سریع به سمت محتوای خوب شکل گرفته می شود ، پاسخ های مدل پایدار و دقیق باقی می مانند. اما با گذشت زمان ، این کشش جهت می تواند معکوسبا فرمان مدل به سمت خروجی هایی که به طور فزاینده ای غیر موضوعی ، نادرست یا داخلی متناقض هستند.
نکته مهم برای این انتقال (که نویسندگان از نظر ریاضی به عنوان تکرار تعریف می کنند n*) ، هنگامی اتفاق می افتد که بردار زمینه با یک بردار خروجی “بد” تر از یک “خوب” هماهنگ شود. در آن مرحله ، هر نشانه جدید مدل را در طول مسیر اشتباه سوق می دهد و الگویی از خروجی فزاینده نقص یا گمراه کننده را تقویت می کند.
نقطه اوج n* با پیدا کردن لحظه ای که جهت داخلی مدل به طور مساوی با انواع خوب و بد خروجی تراز می شود ، محاسبه می شود. هندسه فضای تعبیه شده، که توسط هر دو بخش آموزشی و سریع کاربر شکل گرفته است ، تعیین می کند که این کراس اوور چقدر سریع رخ می دهد:
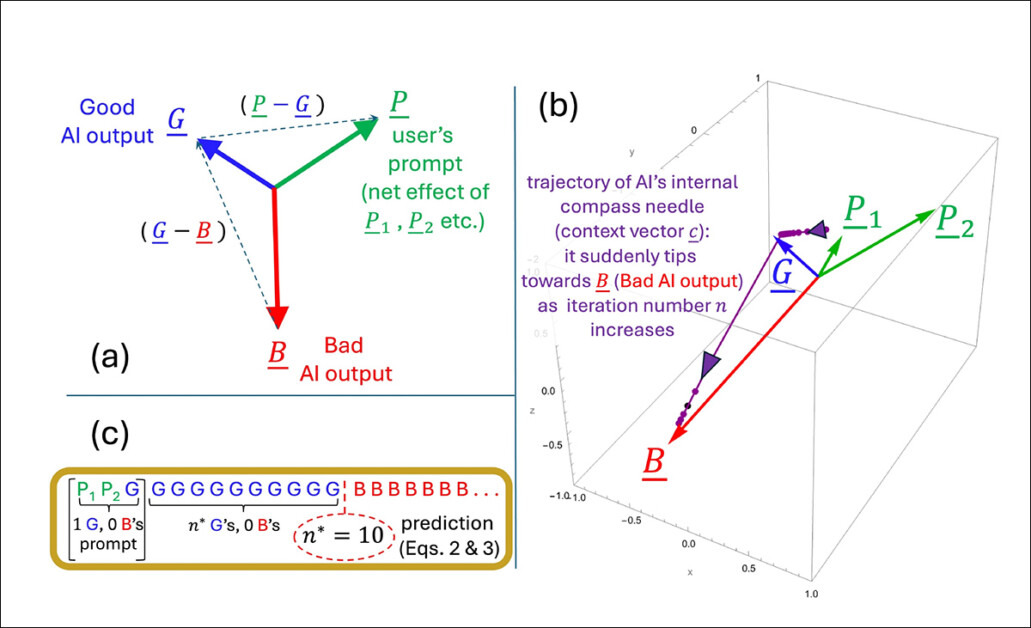
تصویری که نشان می دهد چگونه نقطه اوج n* در مدل ساده نویسندگان ظهور می کند. تنظیم هندسی (A) بردارهای کلیدی را که در پیش بینی زمان خروجی از خوب به بد می چرخند ، تعریف می کند. در (ب) ، نویسندگان آن بردارها را با استفاده از پارامترهای آزمون ترسیم می کنند ، در حالی که (c) نقطه اوج پیش بینی شده را با نتیجه شبیه سازی شده مقایسه می کند. این مسابقه دقیق است ، و از ادعای محققان حمایت می کند که سقوط از نظر ریاضی اجتناب ناپذیر است ، هنگامی که دینامیک داخلی از آستانه عبور می کند.
اصطلاحات مودبانه بر انتخاب مدل بین خروجی های خوب و بد تأثیر نمی گذارد ، زیرا به گفته نویسندگان ، آنها به طور معناداری به موضوع اصلی سریع وصل نمی شوند. درعوض ، آنها به بخش هایی از فضای داخلی مدل ختم می شوند که ارتباط چندانی با آنچه در واقع مدل تصمیم می گیرد ، ندارند.
هنگامی که چنین اصطلاحاتی به سریع اضافه می شود ، آنها تعداد بردارهایی را که مدل در نظر می گیرد افزایش می دهند ، اما به گونه ای نیست که مسیر توجه را تغییر دهد. در نتیجه ، اصطلاحات ادب مانند عمل می کنند سر و صدای آماری: در حال حاضر ، اما بی اثر و ترک نقطه اوج n* بدون تغییر
نویسندگان اظهار داشتند:
‘[Whether] پاسخ هوش مصنوعی ما Rogue بستگی به آموزش LLM ما دارد که نشانه های تعبیه شده را فراهم می کند ، و نشانه های اساسی در سریع ما – نه اینکه آیا ما با آن مودب بوده ایم یا نه. “
مدل مورد استفاده در اثر جدید عمداً باریک است ، با تمرکز بر یک سر توجه واحد با پویایی توکن خطی-یک مجموعه ساده که در آن هر نشانه جدید حالت داخلی را از طریق افزودن بردار مستقیم ، بدون تحولات غیر خطی به روز می کند. دروازهبشر
این تنظیم ساده به نویسندگان این امکان را می دهد تا نتایج دقیقی از دست بدهند و تصویری هندسی واضح از چگونگی و چه موقع خروجی یک مدل می تواند ناگهان از خوب به بد تغییر کند. در تست های خود ، فرمولی که آنها برای پیش بینی این تغییر انجام می دهند مطابق آنچه مدل در واقع انجام می دهد مطابقت دارد.
با این حال ، این سطح از دقت فقط به این دلیل کار می کند که این مدل عمداً ساده نگه داشته می شود. در حالی که نویسندگان اعتراف می کنند که نتیجه گیری های آنها بعداً باید بر روی مدل های چند سر پیچیده تر مانند سری Claude و Chatgpt مورد آزمایش قرار گیرد ، آنها همچنین معتقدند که این تئوری قابل تکرار با افزایش سر توجه است ، بیان می کند*:
“این سؤال که پدیده های اضافی با افزایش تعداد سر و لایه های توجه مرتبط ایجاد می شوند ، چیست. بوها جذاب یکیبشر اما هرگونه انتقال در یک سر توجه واحد هنوز اتفاق می افتد ، و می تواند توسط اتصالات – مانند زنجیره ای از افراد متصل که هنگام سقوط از روی یک صخره کشیده می شوند.
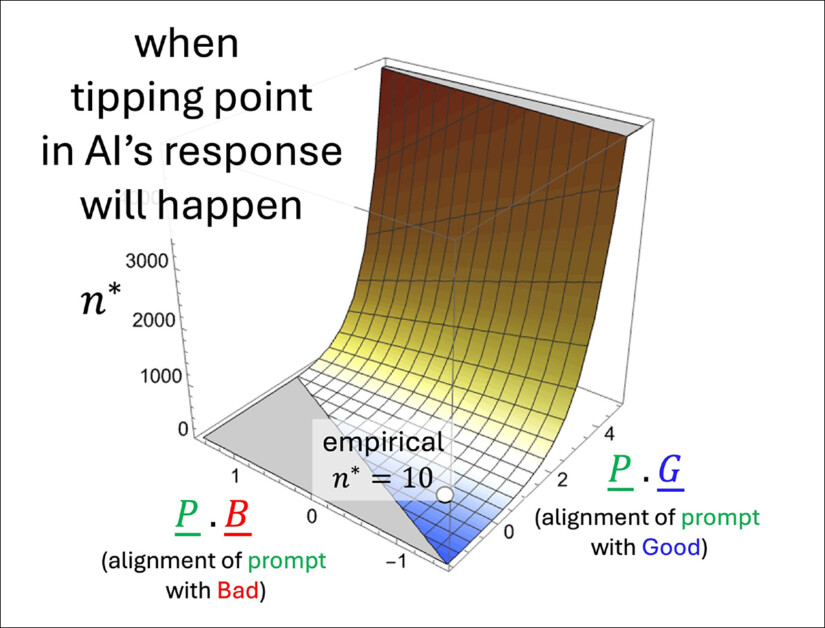
نمونه ای از چگونگی تغییر نقطه نوک N* پیش بینی شده بسته به اینکه چقدر سریع به سمت محتوای خوب یا بد تکیه می دهد. سطح از فرمول تقریبی نویسندگان ناشی می شود و نشان می دهد که اصطلاحات مودبانه ، که به وضوح از هر طرف پشتیبانی نمی کند ، تأثیر کمی در هنگام سقوط دارد. مقدار مشخص شده (n* = 10) با شبیه سازی های قبلی مطابقت دارد و از منطق داخلی مدل پشتیبانی می کند.
گپ زدن ..؟
آنچه نامشخص است این است که آیا همان مکانیسم از پرش به مدرن زنده مانده است معماری ترانسفورماتوربشر توجه چند سر ، تعامل را در سرهای تخصصی معرفی می کند ، که ممکن است در برابر یا ماسک نوع رفتار اوج توضیح داده شده باشد.
نویسندگان این پیچیدگی را تصدیق می کنند ، اما استدلال می کنند که سرهای توجه غالباً به صورت تثبیت همراه هستند و نوع فروپاشی داخلی آنها می تواند باشد تقویت شده به جای سرکوب در سیستم های در مقیاس کامل.
بدون گسترش مدل یا آزمایش تجربی در سراسر تولید LLMS ، این ادعا هنوز تأیید نشده است. با این حال ، به نظر می رسد این مکانیسم به اندازه کافی دقیق برای پشتیبانی از ابتکارات تحقیقاتی پیگیری است ، و نویسندگان فرصتی روشنی برای به چالش کشیدن یا تأیید نظریه در مقیاس ارائه می دهند.
از منزل خارج شدن
در حال حاضر ، به نظر می رسد که موضوع ادب نسبت به LLMS در معرض مصرف کننده یا از دیدگاه (عملگرا) که سیستم های آموزش دیده ممکن است با استفاده از مودبانه پاسخ دهند ، پاسخ دهند. یا اینکه یک سبک ارتباطی بی پروا و بی پروا با چنین سیستم هایی خطرناک است گسترش به روابط اجتماعی واقعی کاربر ، از طریق زور عادت.
احتمالاً ، LLM ها هنوز به اندازه کافی در زمینه های اجتماعی در دنیای واقعی برای ادبیات تحقیق برای تأیید پرونده دوم مورد استفاده قرار نگرفته اند. اما مقاله جدید در مورد مزایای سیستم های AI انسان شناسی از این نوع شک و تردید جالبی ایجاد می کند.
یک مطالعه در اکتبر گذشته از استنفورد پیشنهاد شده (برخلاف a مطالعه 2020) این که درمان LLM ها به گونه ای که آنها انسان هستند علاوه بر این خطرات برای تخریب معنای زبان دارند ، نتیجه می گیرند که ادب “روت” در نهایت معنای اصلی اجتماعی خود را از دست می دهد:
[A] بیانیه ای که از یک بلندگو انسانی دوستانه یا واقعی به نظر می رسد اگر از سیستم هوش مصنوعی ناشی شود ، می تواند نامطلوب باشد زیرا دومی فاقد تعهد یا قصد معنی دار در پشت بیانیه است ، بنابراین بیانیه را توخالی و فریبنده می کند.
با این حال ، تقریباً 67 درصد از آمریکایی ها می گویند طبق گفته های بررسی 2025 از انتشارات آینده. اکثر آنها گفتند که این کار به سادگی “کار درستی” است ، در حالی که 12 درصد اعتراف کردند که آنها محتاط هستند – فقط در صورت افزایش ماشین ها.
* تبدیل من از استنادهای درون خطی نویسندگان به لینک های لینک. تا حدی ، لینک ها دلخواه/مثال هستند ، زیرا نویسندگان در نقاط خاص به جای یک انتشار خاص ، به طیف گسترده ای از استنادهای پاورقی پیوند می خورند.
اولین بار منتشر شده چهارشنبه ، 30 آوریل 2025