
مدل های بزرگ زبان (LLM) به طور قابل توجهی تکامل یافته اند. آنچه به عنوان ساده تولید متن و ابزارهای ترجمه شروع شده است ، اکنون در تحقیق ، تصمیم گیری و حل مسئله پیچیده استفاده می شود. یک عامل اصلی در این تغییر ، توانایی در حال رشد LLMS در تفکر سیستماتیک تر با تجزیه مشکلات ، ارزیابی چندین مورد و پالایش پاسخ های آنها به صورت پویا است. این مدل ها به جای صرفاً پیش بینی کلمه بعدی در یک دنباله ، اکنون می توانند استدلال ساختاری را انجام دهند و آنها را در انجام کارهای پیچیده مؤثرتر می کنند. مدل های پیشرو مانند Opai’s O3با جمینی گوگلوت R1 Deepseek این قابلیت ها را برای تقویت توانایی آنها در پردازش و تجزیه و تحلیل مؤثرتر اطلاعات ادغام کنید.
درک تفکر شبیه سازی شده
انسان به طور طبیعی قبل از تصمیم گیری گزینه های مختلفی را تجزیه و تحلیل می کند. چه برنامه ریزی تعطیلات یا حل مشکل ، ما اغلب برنامه های مختلفی را در ذهن خود شبیه سازی می کنیم تا چندین عامل را ارزیابی کنیم ، جوانب مثبت و منفی را ارزیابی کنیم و گزینه های خود را بر این اساس تنظیم کنیم. محققان در حال ادغام این توانایی LLMS برای افزایش قابلیت های استدلال خود هستند. در اینجا ، تفکر شبیه سازی شده اساساً به توانایی LLMS در انجام استدلال سیستماتیک قبل از ایجاد پاسخ اشاره دارد. این برخلاف بازیابی پاسخ از داده های ذخیره شده است. یک قیاس مفید حل یک مشکل ریاضی است:
- یک هوش مصنوعی اساسی ممکن است یک الگوی را تشخیص دهد و بدون تأیید آن به سرعت پاسخ ایجاد کند.
- هوش مصنوعی با استفاده از استدلال شبیه سازی شده از طریق مراحل کار می کند ، اشتباهات را بررسی می کند و منطق آن را قبل از پاسخگویی تأیید می کند.
زنجیره ای از فکر: آموزش هوش مصنوعی برای فکر کردن در مراحل
اگر LLMS مجبور به اجرای تفکر شبیه سازی شده مانند انسان باشد ، باید بتوانند مشکلات پیچیده را در مراحل کوچکتر و متوالی تجزیه کنند. اینجاست زنجیره ای از فکر (COT) تکنیک نقش مهمی ایفا می کند.
COT یک رویکرد سریع است که LLM ها را به صورت متقاطع راهنمایی می کند. این فرایند استدلال ساختاری به جای پرش به نتیجه گیری ، LLM ها را قادر می سازد تا مشکلات پیچیده را به مراحل ساده تر و قابل کنترل تقسیم کنند و آنها را به مرحله به مرحله حل کنند.
به عنوان مثال ، هنگام حل یک مشکل کلمه در ریاضی:
- یک هوش مصنوعی اساسی ممکن است تلاش کند تا مشکل را با یک مثال قبلاً دیده شده و پاسخی ارائه دهد.
- هوش مصنوعی با استفاده از استدلال زنجیره ای از هر مرحله ، هر مرحله را تشریح می کند ، و از طریق محاسبات قبل از رسیدن به یک راه حل نهایی ، از طریق محاسبات کار می کند.
این رویکرد در مناطقی که نیاز به کسر منطقی ، حل مسئله چند مرحله ای و درک متنی دارند ، کارآمد است. در حالی که مدل های قبلی به زنجیره های استدلال در انسان نیاز داشتند ، LLM های پیشرفته مانند Openai O3 و R1 Deepseek می توانند استدلال COT را به صورت تطبیقی یاد بگیرند و به کار گیرند.
چگونه LLM های پیشرو تفکر شبیه سازی شده را پیاده سازی می کنند
LLM های مختلف به روش های مختلف از تفکر شبیه سازی شده استفاده می کنند. در زیر مروری بر چگونگی Openai’s O3 ، Google DeepMind’s Models و Deepseek-R1 تفکر شبیه سازی شده به همراه نقاط قوت و محدودیت های مربوطه ارائه شده است.
Openai O3: فکر کردن مثل یک شطرنج
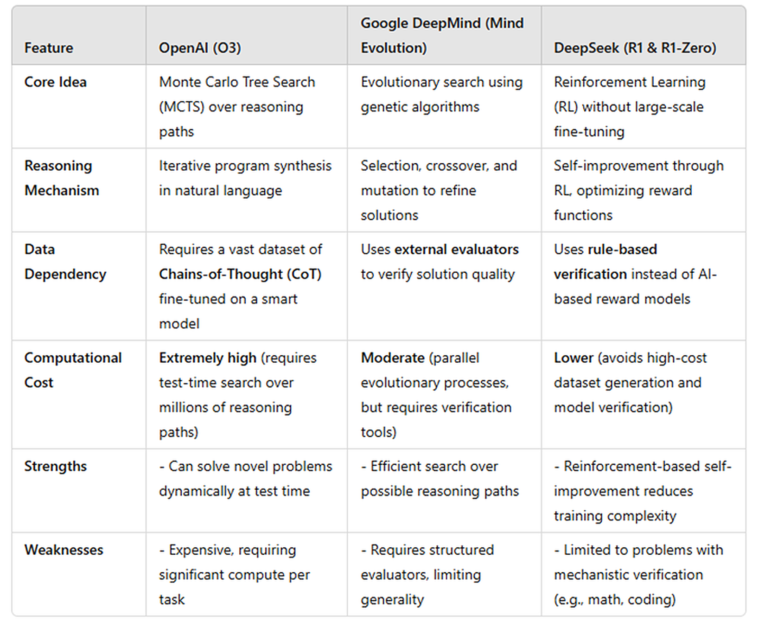
در حالی که جزئیات دقیق در مورد مدل O3 Openai هنوز مشخص نیست ، محقق اعتقاد داشتن از تکنیکی شبیه به جستجوی درخت مونت کارلو (MCTS) ، استراتژی مورد استفاده در بازی های AI محور مانند الفاگوبشر O3 مانند یک بازیکن شطرنج که چندین حرکت را قبل از تصمیم گیری تجزیه و تحلیل می کند ، راه حل های مختلف را بررسی می کند ، کیفیت آنها را ارزیابی می کند و امیدوار کننده ترین را انتخاب می کند.
بر خلاف مدل های قبلی که به تشخیص الگوی متکی هستند ، O3 به طور فعال مسیرهای استدلال را با استفاده از تکنیک های COT تولید و اصلاح می کند. در حین استنتاج ، مراحل محاسباتی اضافی را برای ساخت زنجیره های استدلال چندگانه انجام می دهد. اینها سپس توسط یک مدل ارزیاب ارزیابی می شوند – احتمالاً یک مدل پاداش برای اطمینان از انسجام و صحت منطقی آموزش دیده است. پاسخ نهایی بر اساس یک مکانیسم امتیاز دهی برای ارائه یک خروجی خوب فصلی انتخاب شده است.
O3 یک فرآیند چند مرحله ای ساختاری را دنبال می کند. در ابتدا ، آن را بر روی یک مجموعه داده وسیع از زنجیره های استدلال انسان تنظیم می کند ، و الگوهای تفکر منطقی را درونی می کند. در زمان استنتاج ، راه حل های مختلفی برای یک مشکل معین ایجاد می کند ، آنها را بر اساس صحت و انسجام رتبه بندی می کند و در صورت لزوم بهترین را اصلاح می کند. در حالی که این روش به O3 اجازه می دهد تا قبل از پاسخگویی و بهبود دقت ، خود را اصلاح کند ، تجارت هزینه محاسباتی است-استفاده از چندین امکان به قدرت پردازش قابل توجهی نیاز دارد و آن را کندتر و با منابع بیشتر می کند. با این وجود ، O3 در تجزیه و تحلیل پویا و حل مسئله برتری دارد و آن را در بین مدلهای پیشرفته AI امروز قرار می دهد.
Google DeepMind: پاسخ های پالایش مانند ویرایشگر
DeepMind رویکرد جدیدی به نام “تکامل ذهن، “که استدلال را به عنوان یک فرآیند پالایش مکرر رفتار می کند. این مدل به جای تجزیه و تحلیل چندین سناریو آینده ، بیشتر شبیه یک ویرایشگر است که پیش نویس های مختلف مقاله را تصفیه می کند. این مدل چندین پاسخ ممکن ایجاد می کند ، کیفیت آنها را ارزیابی می کند و بهترین را تصحیح می کند.
این فرایند با الهام از الگوریتم های ژنتیکی ، پاسخ های با کیفیت بالا را از طریق تکرار تضمین می کند. این امر به ویژه برای کارهای ساختاری مانند معماهای منطق و چالش های برنامه نویسی مؤثر است ، جایی که معیارهای واضح بهترین پاسخ را تعیین می کنند.
با این حال ، این روش محدودیت هایی دارد. از آنجا که برای ارزیابی کیفیت پاسخ به یک سیستم امتیاز دهی خارجی متکی است ، ممکن است با استدلال انتزاعی و بدون پاسخ صحیح یا نادرست مبارزه کند. بر خلاف O3 ، که به طور پویا دلایل در زمان واقعی ، مدل DeepMind بر پالایش پاسخ های موجود متمرکز است و باعث می شود که آن را برای سؤالات بازتر انعطاف پذیر تر کند.
Deepseek-R1: یادگیری استدلال مانند دانش آموز
DeepSeek-R1 از یک رویکرد مبتنی بر یادگیری تقویت شده استفاده می کند که به آن اجازه می دهد تا به جای ارزیابی چندین پاسخ در زمان واقعی ، قابلیت های استدلال را در طول زمان توسعه دهد. DeepSeek-R1 به جای تکیه بر داده های استدلال از پیش تولید شده ، با حل مشکلات ، دریافت بازخورد و بهبود تکراری-یادآوری می کند که دانش آموزان مهارت های حل مسئله خود را از طریق تمرین اصلاح می کنند.
این مدل از یک حلقه یادگیری تقویت شده ساختاری پیروی می کند. با یک مدل پایه مانند شروع می شود. Deepseek-v3، و از شما خواسته می شود که مشکلات ریاضی را به صورت گام به گام حل کنند. هر پاسخ از طریق اجرای کد مستقیم تأیید می شود ، و با استفاده از نیاز به یک مدل اضافی برای تأیید صحت ، استفاده می شود. اگر راه حل صحیح باشد ، مدل پاداش می گیرد. اگر نادرست باشد ، مجازات می شود. این فرآیند به طور گسترده ای تکرار می شود و به DeepSeek-R1 اجازه می دهد تا مهارت های استدلال منطقی خود را اصلاح کرده و مشکلات پیچیده تری را در طول زمان اولویت بندی کند.
یک مزیت اصلی این رویکرد کارآیی است. بر خلاف O3 ، که استدلال گسترده ای را در زمان استنباط انجام می دهد ، Deepseek-R1 قابلیت های استدلال را در حین آموزش تعبیه می کند ، و آن را سریعتر و مقرون به صرفه تر می کند. بسیار مقیاس پذیر است زیرا نیازی به مجموعه داده های عظیم با برچسب یا یک مدل تأیید گران ندارد.
با این حال ، این رویکرد مبتنی بر یادگیری تقویت شده دارای تجارت است. از آنجا که به وظایف با نتایج قابل اثبات متکی است ، در ریاضیات و برنامه نویسی برتری دارد. با این وجود ، ممکن است با استدلال انتزاعی در قانون ، اخلاق یا حل مسئله خلاق مبارزه کند. در حالی که استدلال ریاضی ممکن است به حوزه های دیگر منتقل شود ، کاربرد گسترده تر آن نامشخص است.
جدول: مقایسه بین O3 Openai ، تکامل ذهن DeepMind و R1 Deepseek
آینده استدلال هوش مصنوعی
استدلال شبیه سازی شده گامی مهم در جهت اطمینان و هوشمند تر هوش مصنوعی است. با تکامل این مدل ها ، تمرکز از تولید ساده متن به توسعه توانایی های حل مسئله قوی که از نزدیک شبیه تفکر انسان است ، تغییر می کند. پیشرفت های آینده به احتمال زیاد بر ساختن مدل های هوش مصنوعی قادر به شناسایی و تصحیح خطاها ، ادغام آنها با ابزارهای خارجی برای تأیید پاسخ ها و تشخیص عدم اطمینان در هنگام مواجهه با اطلاعات مبهم خواهد بود. با این حال ، یک چالش اساسی تعادل عمق استدلال با راندمان محاسباتی است. هدف نهایی توسعه سیستمهای هوش مصنوعی است که به طرز فکری پاسخ های خود را در نظر می گیرند ، از صحت و قابلیت اطمینان اطمینان می دهند ، دقیقاً مانند یک متخصص انسانی که قبل از اقدام ، هر تصمیم را با دقت ارزیابی می کند.