
راهنمای عملی برای انتخاب الگوریتم مناسب برای مشکل شما: از رگرسیون تا شبکه های عصبی
تصویر ویرایشگر | ایدئوگرام
این مقاله از طریق دستورالعملهای روشن نحوه انتخاب الگوریتم یا مدل یادگیری ماشینی (ML) مناسب برای انواع مختلف مشکلات دنیای واقعی و تجاری را توضیح میدهد. دانستن نحوه تصمیم گیری در مورد الگوریتم ML مناسب بسیار مهم است زیرا موفقیت هر پروژه ML به درستی این انتخاب بستگی دارد.
مقاله با ارائه یک مدل مبتنی بر سوال آغاز میشود و با مجموعهای جدولی از موارد استفاده مثال و دلایل منطقی در پس انتخاب بهترین الگوریتم برای هر یک به پایان میرسد. نمونهها از مشکلات ساده تا مشکلات پیشرفتهتر که به قابلیتهای هوش مصنوعی مدرن مانند مدلهای زبانی نیاز دارند، متغیر است.
توجه داشته باشید: برای سادگی، مقاله از این اصطلاح استفاده عمومی خواهد کرد الگوریتم ML برای مراجعه به انواع الگوریتمها، مدلها و تکنیکهای ML. بیشتر تکنیکهای ML مبتنی بر مدل هستند، با مدلی که برای استنتاج بهدنبال استفاده از یک الگوریتم ساخته میشود. بنابراین، در زمینه فنی تر، این اصطلاحات باید متمایز شوند.
یک مدل مبتنی بر سوال
سوالات کلیدی زیر برای راهنمایی مدیران پروژه های AI، ML و تجزیه و تحلیل داده ها به سمت انتخاب صحیح الگوریتم ML برای استفاده برای حل مشکل خاص خود طراحی شده اند.
سوال کلیدی 1: چه نوع مشکلی را باید حل کنید؟
- 1.A. آیا نیاز به پیش بینی چیزی دارید؟
- 1.B. اگر چنین است، آیا این یک مقدار عددی است یا یک طبقه بندی به دسته ها؟
- 1.C. اگر می خواهید یک مقدار عددی را پیش بینی کنید، آیا بر اساس متغیرها یا ویژگی های دیگری است؟ یا ارزش های آینده را بر اساس ارزش های تاریخی گذشته پیش بینی می کنید؟
سه سوال بالا مربوط به رویکردهای یادگیری پیش بینی شده یا تحت نظارت است. پاسخ دهید بله به سوال 1.A به این معنی است که شما به دنبال یک الگوریتم یادگیری نظارت شده هستید زیرا باید چیزی ناشناخته را در مورد داده های جدید یا آینده خود پیش بینی کنید. بسته به آنچه می خواهید پیش بینی کنید و چگونه، ممکن است با یک مواجه شوید طبقه بندی، رگرسیونیا پیش بینی سری های زمانی لکه دار کردن کدام؟ این همان چیزی است که سؤالات 1.B و 1.C به شما در تعیین آن کمک می کند.
اگر می خواهید دسته بندی ها را پیش بینی یا اختصاص دهید، با یک کار طبقه بندی مواجه می شوید. اگر می خواهید یک متغیر عددی مانند قیمت خانه را بر اساس ویژگی های دیگر مانند ویژگی های خانه پیش بینی کنید، این یک کار رگرسیونی است. در نهایت، اگر میخواهید یک مقدار عددی آینده را بر اساس مقادیر گذشته پیشبینی کنید، مثلاً قیمت یک صندلی تجاری یک پرواز را بر اساس تاریخچه روزانه میانگین قیمتهای گذشته آن پیشبینی کنید، در این صورت با پیشبینی سری زمانی کار روبرو هستید.
اگر پاسخ دادید به 1.A برگردید خیر برای این سوال، و شما ترجیح می دهید اطلاعات خود را بهتر درک کنید یا الگوهای پنهان در آنها را کشف کنید، شانس خوبی وجود دارد که یادگیری بدون نظارت الگوریتم همان چیزی است که شما به دنبال آن هستید. به عنوان مثال، اگر می خواهید گروه های پنهان را در داده های خود کشف کنید (به یافتن بخش های مشتری فکر کنید)، وظیفه هدف شما این است گروه بندیو اگر میخواهید تراکنشهای غیرعادی یا تلاشهای غیرعادی برای ورود به یک سیستم بسیار امن را شناسایی کنید، تشخیص ناهنجاری الگوریتم ها رویکرد ترجیحی شما هستند.
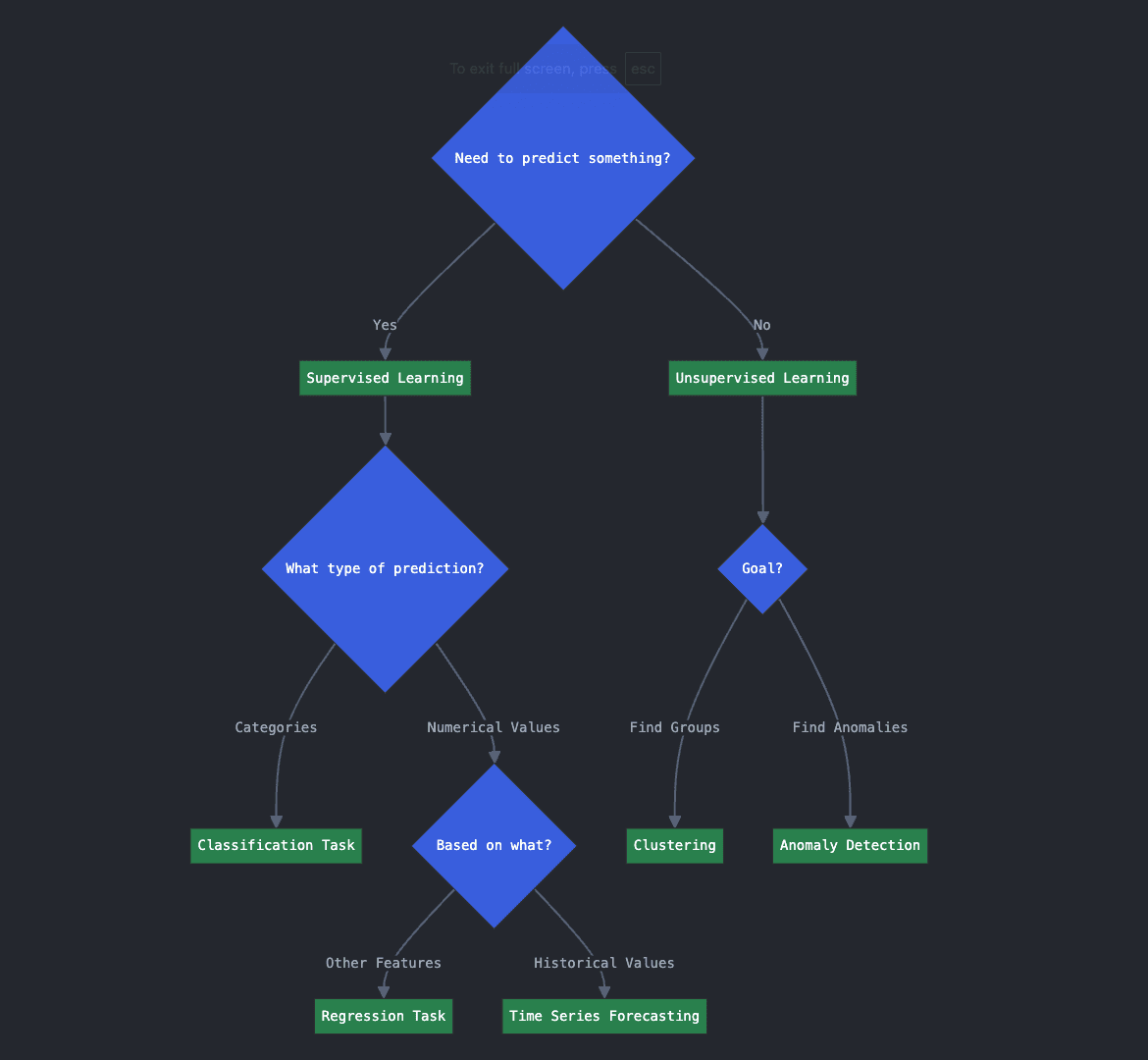
نمودار جریان تصمیم برای سوال کلیدی 1 (برای بزرگنمایی کلیک کنید)
تصویر توسط ناشر
سوال کلیدی 2: چه نوع داده ای دارید؟
حتی اگر پاسخ شما به گروه قبلی سوالات واضح بود و وظیفه هدف مشخصی در ذهن دارید، برخی از وظایف ML دارای الگوریتمهای متنوعی برای استفاده هستند. کدام را انتخاب می کنید؟ بخشی از این پاسخ در داده های شما، حجم و پیچیدگی آن نهفته است.
2.A. داده های ساختاریافته و ساده تر مرتب شده در جداول با ویژگی های کمی، می تواند با الگوریتم های ML ساده مانند رگرسیون خطی، طبقه بندی درخت تصمیم، خوشه بندی k-meansو غیره
2.B. داده های پیچیدگی متوسطبه عنوان مثال هنوز ساختار یافته است، اما دارای ده ها ویژگی، یا تصاویر با وضوح پایین، می تواند با آنها پردازش شود روش های مجموعه برای طبقه بندی و رگرسیون، که چندین نمونه مدل ML را در یک مورد برای دستیابی به نتایج پیش بینی بهتر ترکیب می کند. نمونه هایی از روش های گروهی هستند جنگل های تصادفی، افزایش گرادیان و XGBoost. برای کارهای دیگر مانند خوشه بندی، الگوریتم هایی مانند این را امتحان کنید DBSCAN یا خوشه بندی طیفی.
2.C. آخرین، داده های بسیار پیچیده مانند تصاویر، متن و صدا به طور کلی نیاز به معماری های پیشرفته تری مانند شبکه های عصبی عمیق: آموزش سخت تر، اما در حل مسائل دشوار زمانی که در معرض حجم قابل توجهی از داده های نمونه برای یادگیری قرار می گیرند، موثرتر است. برای موارد استفاده بسیار پیشرفته، مانند درک و تولید حجم بالایی از داده های زبانی (متن)، حتی ممکن است لازم باشد ابزارهای قدرتمندی را در نظر بگیرید. معماری های مبتنی بر ترانسفورماتور به عنوان مدل های زبان بزرگ (LLM).
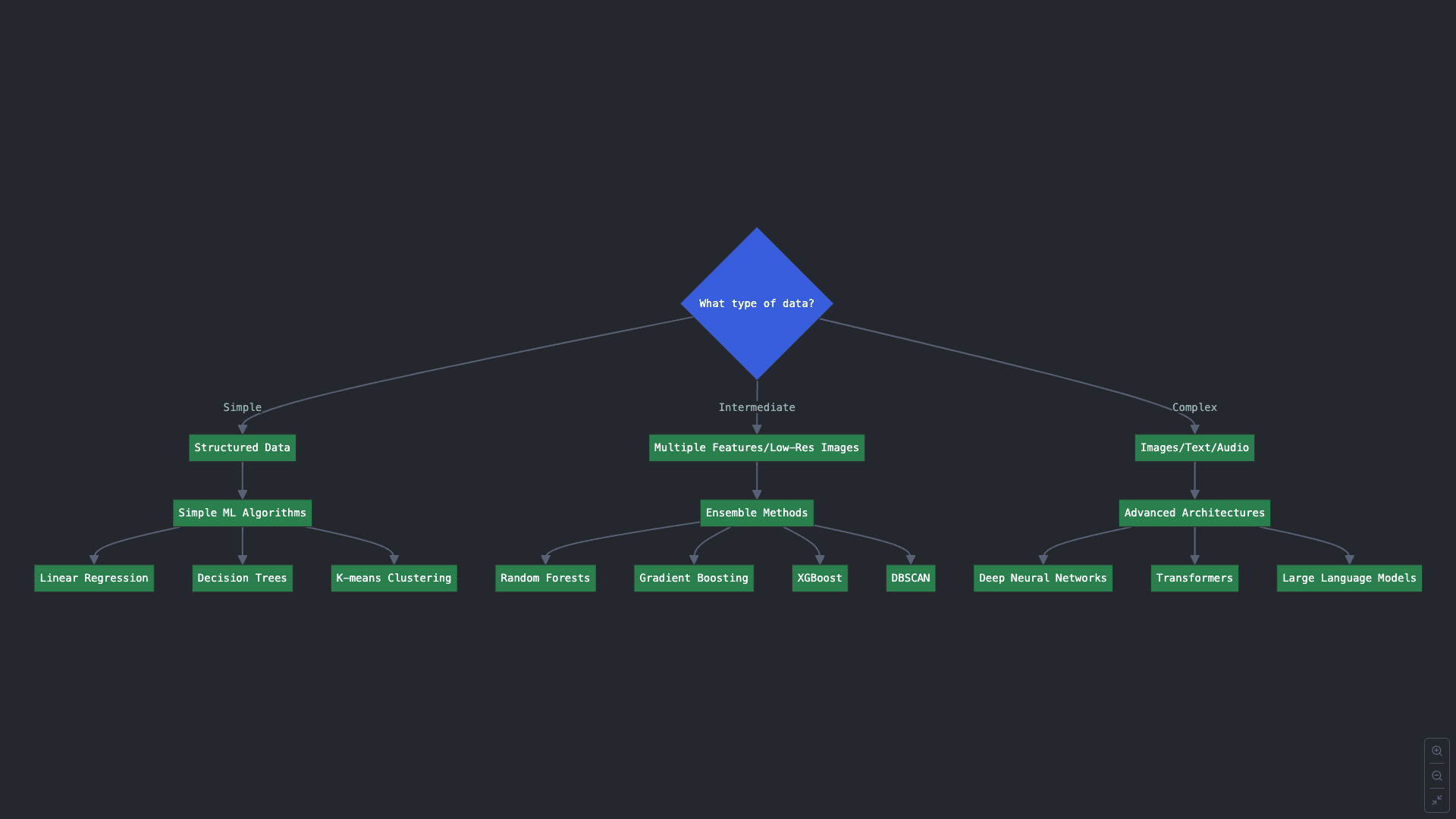
نمودار جریان تصمیم برای سوال کلیدی 2 (برای بزرگنمایی کلیک کنید)
تصویر توسط ناشر
سوال کلیدی 3: به چه سطحی از تفسیرپذیری نیاز دارید؟
در برخی زمینهها که درک چگونگی تصمیمگیری الگوریتم ML از جمله پیشبینیها، عوامل ورودی بر تصمیمگیری و چگونگی تأثیرگذاری، اهمیت دارد. تفسیرپذیری جنبه مهم دیگری است که می تواند بر انتخاب الگوریتم شما تأثیر بگذارد. به عنوان یک قاعده کلی، هر چه الگوریتم ساده تر باشد، قابل تفسیرتر است. بنابراین، رگرسیون خطی و درختهای تصمیم کوچک از جمله قابل تفسیرترین راهحلها هستند، در حالی که شبکههای عصبی عمیق با معماریهای داخلی پیچیده معمولاً نامیده میشوند. مدل های جعبه سیاه به دلیل دشواری در تفسیر تصمیمات و درک رفتار آنها. اگر تعادلی بین تفسیرپذیری و کارایی بالا در دادههای پیچیده مورد نیاز باشد، روشهای مجموعه مبتنی بر درختهای تصمیمگیری، مانند جنگلهای تصادفی، اغلب یک راهحل سازش خوب هستند.
سوال کلیدی 4: چه مقدار داده را مدیریت می کنید؟
این موضوع ارتباط نزدیکی با سوال کلیدی 2 دارد. برخی از الگوریتمهای ML بسته به حجم دادههایی که برای آموزش آنها استفاده میشود، کارآمدتر از سایرین هستند. از سوی دیگر، گزینههای پیچیدهای مانند شبکههای عصبی معمولاً به مقادیر بیشتری داده نیاز دارند تا یاد بگیرند که چگونه وظایفی را که برای انجام آن طراحی شدهاند، حتی به قیمت قربانی کردن آموزش مؤثر، انجام دهند. یک قانون سرانگشتی خوب در اینجا این است که حجم داده در بیشتر موارد با پیچیدگی داده ها در انتخاب نوع الگوریتم مناسب ارتباط نزدیکی دارد.
نمونه های کاربردی
برای نتیجه گیری و تکمیل این راهنما، در اینجا جدولی با برخی موارد استفاده واقعی وجود دارد که در آن عوامل تصمیم گیری در نظر گرفته شده در این مقاله شرح داده شده است:
| موارد استفاده کنید | نوع مشکل | الگوریتم پیشنهادی | داده ها | ملاحظات کلیدی |
|---|---|---|---|---|
| پیش بینی فروش ماهانه | رگرسیون | رگرسیون خطی | داده های ساخت یافته | قابل تفسیر، سریع، کارآمد برای داده های کوچک |
| کشف تقلب در معاملات | طبقه بندی باینری | رگرسیون لجستیک، SVM | داده های ساخت یافته | تعادل بین دقت و سرعت |
| طبقه بندی محصولات در تصاویر | طبقه بندی تصویر | شبکه های عصبی کانولوشن (CNN) | تصاویر (داده های بدون ساختار) | دقت بالا، هزینه محاسباتی بالا |
| تجزیه و تحلیل احساسات در بررسی محصول | طبقه بندی متن (NLP) | مدل های ترانسفورماتور (BERT، GPT) | متن (داده های بدون ساختار) | به منابع پیشرفته و بسیار دقیق نیاز دارد |
| پیشبینی ریزش با مجموعه دادههای بزرگ | طبقه بندی یا رگرسیون | جنگل تصادفی، افزایش گرادیان | مجموعه داده های ساختاریافته و بزرگ | کمتر قابل تفسیر، برای داده های بزرگ بسیار موثر است |
| تولید خودکار متن یا پاسخ به پرس و جوها | NLP پیشرفته | مدل های زبان بزرگ (GPT، BERT) | حجم زیاد متن | هزینه محاسباتی بالا، نتایج دقیق |
دریابید که الگوریتم های یادگیری ماشین چگونه کار می کنند!

نحوه کار الگوریتم ها را در چند دقیقه بیابید
… فقط با مثال های ساده حسابی
نحوه کار را در کتاب الکترونیکی جدید من بیابید:
بر الگوریتم های یادگیری ماشین مسلط شوید
پوشش می دهد توضیحات و نمونه ها از 10 بهترین الگوریتمبه عنوان:
رگرسیون خطی، k-نزدیکترین همسایه ها، ماشین های بردار پشتیبانی می کند و خیلی بیشتر…
در نهایت پرده را عقب بکشید
الگوریتم های یادگیری ماشینی
از دانشگاهیان دوری کنید فقط نتایج