
یک تکنیک جدید پیشگامانه که توسط تیمی از محققان از Meta، UC Berkeley و NYU توسعه یافته است، نویدبخش بهبود نحوه برخورد سیستمهای هوش مصنوعی به وظایف عمومی است. معروف به “بهینه سازی اولویت فکر” (TPO)، هدف این روش ایجاد است مدل های زبان بزرگ (LLM) در پاسخ های خود متفکرتر و سنجیده تر هستند.
تلاش مشترک پشت TPO، تخصص برخی از موسسات پیشرو در تحقیقات هوش مصنوعی را گرد هم می آورد.
بهینه سازی ترجیحات مکانیک فکر
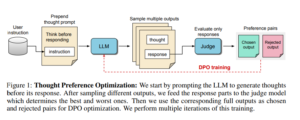
در هسته خود، TPO با تشویق مدلهای هوش مصنوعی برای ایجاد «گامهای فکری» قبل از ارائه پاسخ نهایی کار میکند. این فرآیند فرآیندهای شناختی انسان را تقلید می کند، جایی که ما اغلب قبل از بیان پاسخ خود به یک مشکل یا سؤال فکر می کنیم.
این تکنیک شامل چندین مرحله کلیدی است:
- از مدل خواسته می شود تا قبل از پاسخ دادن به یک پرسش، مراحل فکری را ایجاد کند.
- خروجی های متعددی ایجاد می شود که هر کدام مجموعه ای از مراحل فکری و پاسخ نهایی خود را دارند.
- یک مدل ارزیاب فقط پاسخ های نهایی را ارزیابی می کند، نه خود مراحل فکری را.
- سپس این مدل از طریق بهینه سازی اولویت ها بر اساس این ارزیابی ها آموزش داده می شود.
این رویکرد به طور قابل توجهی با تکنیک های قبلی متفاوت است، مانند درخواست زنجیرهای از فکر (CoT).. در حالی که CoT عمدتاً برای کارهای ریاضی و منطقی استفاده شده است، TPO طوری طراحی شده است که کاربرد وسیع تری در انواع مختلف پرس و جوها و دستورالعمل ها داشته باشد. علاوه بر این، TPO نیازی به نظارت صریح بر فرآیند تفکر ندارد و به مدل اجازه میدهد تا استراتژیهای تفکر مؤثر خود را توسعه دهد.
تفاوت کلیدی دیگر این است که TPO بر چالش داده های آموزشی محدود حاوی فرآیندهای فکری انسان غلبه می کند. با تمرکز ارزیابی بر روی خروجی نهایی به جای مراحل میانی، TPO اجازه می دهد تا الگوهای تفکر انعطاف پذیرتر و متنوع تری پدیدار شوند.
راه اندازی آزمایشی و نتایج
برای آزمایش اثربخشی TPO، محققان آزمایشهایی را با استفاده از دو معیار برجسته در زمینه مدلهای زبان هوش مصنوعی انجام دادند: AlpacaEval و Arena-Hard. این معیارها برای ارزیابی قابلیتهای کلی پیروی از دستورالعملهای مدلهای هوش مصنوعی در طیف گستردهای از وظایف طراحی شدهاند.
آزمایشها از Llama-3-8B-Instruct بهعنوان یک مدل بذر استفاده کردند، با مدلهای داور مختلف برای ارزیابی. این تنظیم به محققان اجازه داد تا عملکرد TPO را با مدلهای پایه مقایسه کنند و تأثیر آن را بر انواع مختلف وظایف ارزیابی کنند.
نتایج این آزمایشها امیدوارکننده بود و پیشرفتهایی را در چندین دسته نشان داد:
- استدلال و حل مسئله: همانطور که انتظار می رفت، TPO در کارهایی که نیاز به تفکر منطقی و تجزیه و تحلیل دارند، دستاوردهایی را نشان داد.
- دانش عمومی: جالب توجه است، این تکنیک همچنین عملکرد در پرس و جوهای مربوط به اطلاعات گسترده و واقعی را بهبود بخشید.
- بازاریابی: شاید تعجب آور باشد که TPO قابلیت های پیشرفته ای را در وظایف مربوط به بازاریابی و فروش نشان داد.
- وظایف خلاقانه: محققان به مزایای بالقوه در زمینه هایی مانند نوشتن خلاق اشاره کردند و پیشنهاد کردند که «تفکر» می تواند به برنامه ریزی و ساختار دادن به خروجی های خلاق کمک کند.
این پیشرفتها محدود به وظایف سنگین استدلال سنتی نبودند، که نشان میدهد TPO پتانسیل افزایش عملکرد هوش مصنوعی را در طیف گستردهای از برنامهها دارد. نرخ برد در معیارهای AlpacaEval و Arena-Hard پیشرفت های قابل توجهی را نسبت به مدل های پایه نشان داد، با TPO به نتایج رقابتی حتی در مقایسه با مدل های زبانی بسیار بزرگ تر.
با این حال، توجه به این نکته مهم است که اجرای فعلی TPO محدودیتهایی را نشان میدهد، به ویژه در وظایف ریاضی. محققان مشاهده کردند که عملکرد در مسائل ریاضی در مقایسه با مدل پایه کاهش یافته است، که نشان می دهد ممکن است برای پرداختن به حوزه های خاص اصلاحات بیشتری لازم باشد.
پیامدهای توسعه هوش مصنوعی
موفقیت TPO در بهبود عملکرد در دسته های مختلف، امکانات هیجان انگیزی را برای برنامه های کاربردی هوش مصنوعی باز می کند. فراتر از استدلال سنتی و وظایف حل مسئله، این تکنیک می تواند قابلیت های هوش مصنوعی را در نوشتن خلاقانه، ترجمه زبان و تولید محتوا افزایش دهد. با اجازه دادن به هوش مصنوعی برای «فکر کردن» از طریق فرآیندهای پیچیده قبل از تولید خروجی، میتوانیم نتایج دقیقتری را در این زمینهها مشاهده کنیم.
در خدمات مشتری، TPO میتواند منجر به پاسخهای متفکرانهتر و جامعتر از چتباتها و دستیاران مجازی شود که به طور بالقوه رضایت کاربر را بهبود میبخشد و نیاز به مداخله انسانی را کاهش میدهد. علاوه بر این، در حوزه تجزیه و تحلیل دادهها، این رویکرد ممکن است هوش مصنوعی را قادر سازد تا قبل از نتیجهگیری از مجموعه دادههای پیچیده، دیدگاههای متعدد و همبستگیهای بالقوه را در نظر بگیرد که منجر به تحلیلهای روشنتر و قابل اعتمادتر شود.
علیرغم نتایج امیدوارکننده، TPO در شکل فعلی خود با چالشهای متعددی مواجه است. کاهش مشاهده شده در تکالیف مرتبط با ریاضی نشان می دهد که این تکنیک ممکن است به طور کلی در همه حوزه ها مفید نباشد. این محدودیت نیاز به اصلاحات خاص دامنه در رویکرد TPO را برجسته می کند.
چالش مهم دیگر افزایش بالقوه سربار محاسباتی است. فرآیند تولید و ارزیابی مسیرهای فکری چندگانه میتواند به طور بالقوه زمان پردازش و نیازهای منابع را افزایش دهد، که ممکن است کاربرد TPO را در سناریوهایی که پاسخهای سریع ضروری هستند، محدود کند.
علاوه بر این، مطالعه فعلی بر روی یک اندازه مدل خاص متمرکز شده است، و سؤالاتی را در مورد اینکه چقدر TPO به مدل های زبانی بزرگتر یا کوچکتر مقیاس می شود، ایجاد کرد. همچنین خطر «تفکر بیش از حد» وجود دارد – «تفکر» بیش از حد می تواند منجر به پاسخ های پیچیده یا بیش از حد پیچیده برای کارهای ساده شود.
ایجاد تعادل بین عمق فکر و پیچیدگی کار در دست، یک حوزه کلیدی برای تحقیق و توسعه آینده خواهد بود.
مسیرهای آینده
یکی از زمینه های کلیدی برای تحقیقات آینده، توسعه روش هایی برای کنترل طول و عمق فرآیندهای فکری هوش مصنوعی است. این می تواند شامل تعدیل پویا باشد که به مدل اجازه می دهد تا عمق تفکر خود را بر اساس پیچیدگی کار در دست تطبیق دهد. محققان همچنین ممکن است پارامترهای تعریف شده توسط کاربر را بررسی کنند و کاربران را قادر میسازند تا سطح تفکر مورد نظر را برای برنامههای مختلف مشخص کنند.
بهینه سازی کارایی در این زمینه بسیار مهم خواهد بود. توسعه الگوریتمهایی برای یافتن نقطه شیرین بین بررسی کامل و زمانهای پاسخ سریع میتواند کاربرد عملی TPO را در حوزههای مختلف و موارد استفاده به طور قابلتوجهی افزایش دهد.
همانطور که مدلهای هوش مصنوعی همچنان در اندازه و قابلیت رشد میکنند، بررسی اینکه چگونه مقیاسهای TPO با اندازه مدل بسیار مهم خواهد بود. جهت های تحقیقاتی آینده ممکن است شامل موارد زیر باشد:
- آزمایش TPO بر روی مدلهای پیشرفته زبان بزرگ برای ارزیابی تأثیر آن بر سیستمهای پیشرفتهتر هوش مصنوعی
- بررسی اینکه آیا مدل های بزرگتر به رویکردهای متفاوتی برای تولید و ارزیابی فکر نیاز دارند یا خیر
- بررسی پتانسیل TPO برای پر کردن شکاف عملکرد بین مدلهای کوچکتر و بزرگتر، به طور بالقوه استفاده کارآمدتر از منابع محاسباتی
این تحقیق میتواند به سیستمهای هوش مصنوعی پیشرفتهتری منجر شود که میتوانند با حفظ کارایی و دقت، وظایف پیچیدهتری را انجام دهند.
خط پایین
Thought Preference Optimization نشان دهنده گام مهمی به جلو در افزایش قابلیت های مدل های زبان بزرگ است. با تشویق سیستمهای هوش مصنوعی به «فکر کردن قبل از صحبت کردن»، TPO پیشرفتهایی را در طیف گستردهای از وظایف نشان داده است و به طور بالقوه تحولی در نحوه رویکرد ما به توسعه هوش مصنوعی ایجاد میکند.
همانطور که تحقیقات در این زمینه ادامه دارد، میتوان انتظار داشت که اصلاحات بیشتری در این تکنیک، رفع محدودیتهای فعلی و گسترش کاربردهای آن مشاهده شود. آینده هوش مصنوعی ممکن است شامل سیستمهایی باشد که نه تنها اطلاعات را پردازش میکنند، بلکه درگیر فرآیندهای شناختی بیشتر شبیه انسان میشوند که منجر به هوش مصنوعی دقیقتر، آگاهتر از زمینه و در نهایت مفیدتر میشود.

