

7 الگوریتم یادگیری ماشینی که هر دانشمند داده باید بداند
تصویر توسط نویسنده | ایجاد شده در Canva
به عنوان یک دانشمند داده، باید به SQL و Python مسلط باشید. اما افزودن یادگیری ماشین به جعبه ابزار شما نیز می تواند بسیار مفید باشد.
ممکن است همیشه به عنوان یک دانشمند داده از یادگیری ماشینی استفاده نکنید. اما برخی از مشکلات با استفاده از الگوریتم های یادگیری ماشینی به جای برنامه نویسی سیستم های مبتنی بر قوانین بهتر حل می شوند.
این راهنما هفت الگوریتم یادگیری ماشینی ساده اما مفید را پوشش می دهد. ما یک مرور مختصر از الگوریتم ارائه می دهیم و سپس نحوه کار و ملاحظات اصلی آن را بیان می کنیم. علاوه بر این، ما همچنین برنامهها یا ایدههای پروژهای را پیشنهاد میکنیم که میتوانید با استفاده از کتابخانه scikit-learn ایجاد کنید.
1. رگرسیون خطی
رگرسیون خطی به شما امکان می دهد تا رابطه خطی بین متغیرهای وابسته و یک یا چند متغیر مستقل را مدل کنید. این یکی از اولین الگوریتم هایی است که می توانید برای پیش بینی متغیر هدف پیوسته از مجموعه ای از ویژگی ها به جعبه ابزار خود اضافه کنید.
نحوه عملکرد الگوریتم
برای یک مدل رگرسیون خطی شامل n پیش بینی کننده ها، معادله به صورت زیر به دست می آید:
یا:
- y مقدار پیش بینی شده است
- βمن ضرایب مدل هستند
- xمن پیش بینی کننده هستند
این الگوریتم مجموع مجذورهای باقیمانده را برای یافتن مقادیر بهینه β به حداقل می رساند: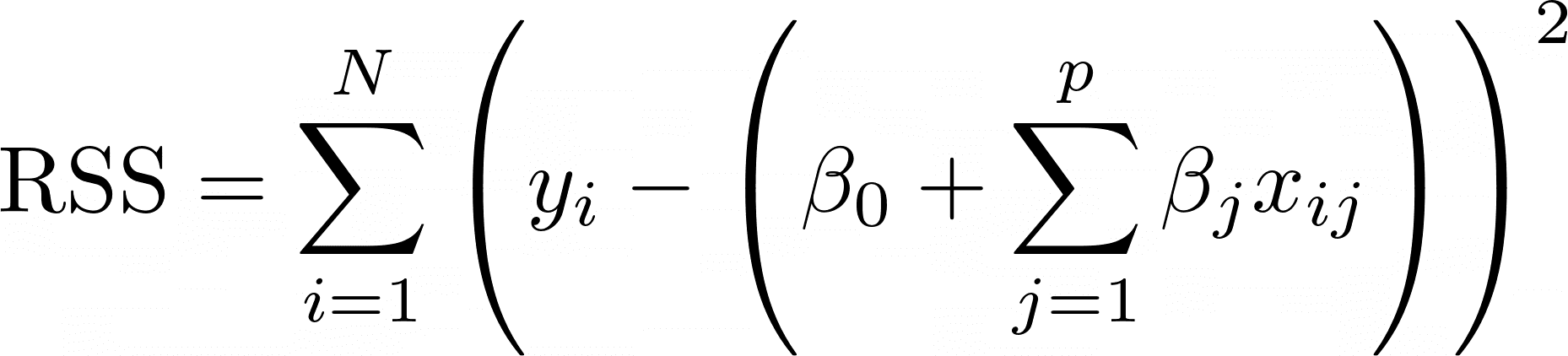
یا:
- N تعداد مشاهدات است
- p تعداد پیش بینی کننده ها است
- βمن ضرایب هستند
- xمن مقادیر پیش بینی کننده برای مشاهده i و پیش بینی j ام هستند
ملاحظات کلیدی
- یک رابطه خطی بین ویژگی های مجموعه داده را فرض می کند.
- حساس به چند خطی و پرت.
یک پروژه رگرسیون ساده برای پیشبینی قیمت املاک و مستغلات یک عمل خوب است.
2. رگرسیون لجستیک
رگرسیون لجستیک معمولاً برای مسائل طبقه بندی باینری استفاده می شود، اما می توانید از آن برای طبقه بندی چند کلاسه نیز استفاده کنید. مدل رگرسیون لجستیک این احتمال را ایجاد می کند که یک ورودی معین به یک کلاس مورد علاقه تعلق دارد.
نحوه عملکرد الگوریتم
رگرسیون لجستیک از تابع لجستیک (تابع سیگموئید) برای پیش بینی احتمالات استفاده می کند:

جایی که βمن ضرایب مدل هستند. احتمالی را ایجاد می کند که می تواند برای تخصیص برچسب های کلاس آستانه گذاری شود.
ملاحظات کلیدی
- مقیاس بندی ویژگی می تواند عملکرد مدل را بهبود بخشد.
- عدم تعادل طبقاتی را با استفاده از تکنیک هایی مانند نمونه گیری مجدد یا وزن دهی اصلاح کنید.
می توانید از رگرسیون لجستیک برای کارهای طبقه بندی مختلف استفاده کنید. طبقه بندی اینکه آیا ایمیل هرزنامه است یا نه می تواند پروژه ساده ای باشد که می توانید روی آن کار کنید.
3. درختان تصمیم
درختان تصمیم مدل های بصری هستند که هم برای طبقه بندی و هم برای رگرسیون استفاده می شوند. همانطور که از نام آن پیداست، با تقسیم داده ها به شاخه ها بر اساس مقادیر ویژگی، تصمیم گیری می شود.
نحوه عملکرد الگوریتم
الگوریتم ویژگیهایی را انتخاب میکند که دادهها را بر اساس معیارهایی مانند ناخالصی جینی یا آنتروپی به بهترین شکل تقسیم میکند. روند به صورت بازگشتی ادامه می یابد.
آنتروپی: اختلال در مجموعه داده را اندازه گیری می کند:
ناخالصی جینی: ناخالصی جینی احتمال طبقه بندی اشتباه یک نقطه انتخابی را اندازه گیری می کند:
الگوریتم درخت تصمیم ویژگی و تقسیمی را انتخاب می کند که منجر به بیشترین کاهش ناخالصی می شود (به دست آوردن اطلاعات برای آنتروپی یا بهره جینی برای ناخالصی جینی).
ملاحظات کلیدی
- تفسیر ساده است اما اغلب در معرض تطبیق بیش از حد است.
- می تواند داده های مقوله ای و عددی را مدیریت کند.
می توانید یک درخت تصمیم را در مورد یک مسئله طبقه بندی که قبلاً روی آن کار کرده اید آموزش دهید و بررسی کنید که آیا مدل بهتری نسبت به رگرسیون لجستیک است یا خیر.
4. جنگل های تصادفی
جنگل تصادفی یک روش یادگیری گروهی است که چندین درخت تصمیم میسازد و پیشبینیهای آنها را برای نتایج قویتر و دقیقتر میانگین میدهد.
نحوه عملکرد الگوریتم
با ترکیب بسته بندی (تجمع بوت استرپ) و انتخاب ویژگی تصادفی، چندین درخت تصمیم می سازد. هر درخت به نتیجه رای میدهد و نتیجهای که بیشترین رای داده شده، پیشبینی نهایی میشود. الگوریتم جنگل تصادفی با میانگین گیری نتایج در همه درختان، بیش از حد برازش را کاهش می دهد.
ملاحظات کلیدی
- مجموعه دادههای بزرگ را به خوبی مدیریت میکند و بیش از حد برازش را کاهش میدهد.
- ممکن است از نظر محاسباتی فشرده تر از یک درخت تصمیم واحد باشد.
می توانید یک الگوریتم جنگل تصادفی را برای پروژه پیش بینی ریزش مشتری اعمال کنید.
5. ماشینهای بردار پشتیبانی (SVM)
Support Vector Machine یا SVM یک الگوریتم طبقه بندی است. این با یافتن ابر صفحه بهینه کار می کند، صفحه ای که حاشیه را به حداکثر می رساند و دو کلاس را در فضای ویژگی از هم جدا می کند.
نحوه عملکرد الگوریتم
هدف، به حداکثر رساندن حاشیه بین کلاس ها با استفاده از بردارهای پشتیبانی است. مسئله بهینه سازی به صورت زیر تعریف می شود:
که در آن w بردار وزن، x استمن بردار ویژگی است و yمن برچسب کلاس است.
ملاحظات کلیدی
- در صورت استفاده از ترفند هسته، می توان برای داده های غیرخطی قابل جداسازی استفاده کرد. الگوریتم به انتخاب تابع هسته حساس است.
- برای مجموعه داده های بزرگ به حافظه و قدرت محاسباتی قابل توجهی نیاز دارد.
می توانید از SVM برای طبقه بندی متن ساده یا مشکل تشخیص هرزنامه استفاده کنید.
6. K-نزدیکترین همسایه (KNN)
K-Nearest Neighbors یا KNN یک الگوریتم ساده و غیر پارامتری است که برای طبقه بندی و رگرسیون با یافتن K نقاط نزدیک به نمونه پرس و جو استفاده می شود.
نحوه عملکرد الگوریتم
الگوریتم فاصله (مانند اقلیدسی) بین نقطه پرس و جو و سایر نقاط مجموعه داده را محاسبه می کند، سپس کلاس اکثر همسایگان خود را اختصاص می دهد.
ملاحظات کلیدی
- انتخاب k و متریک فاصله می تواند عملکرد قابل توجهی را تحت تاثیر قرار دهد.
- مستعد نفرین ابعاد به عنوان فاصله در فضاهای با ابعاد بالا.
میتوانید روی یک مسئله طبقهبندی ساده کار کنید تا ببینید KNN چگونه با سایر الگوریتمهای طبقهبندی مقایسه میشود.
7. K-Means Clustering
K-Means یک الگوریتم خوشهبندی رایج است که مجموعه داده را بر اساس شباهت اندازهگیری شده توسط متریک فاصله به k خوشه تقسیم میکند. نقاط داده در یک خوشه به یکدیگر شباهت بیشتری نسبت به نقاط دیگر خوشه دارند.
نحوه عملکرد الگوریتم
الگوریتم در دو مرحله زیر تکرار می شود:
- هر نقطه داده را به نزدیکترین مرکز خوشه ای اختصاص دهید.
- به روز رسانی مرکزها بر اساس میانگین امتیازهای اختصاص داده شده به آنها.
الگوریتم K-means مجموع مجذورات فواصل را به حداقل می رساند: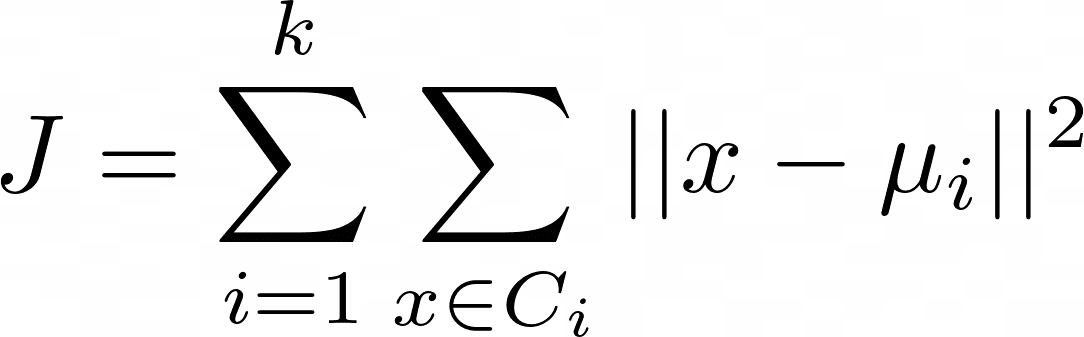
جایی که μمن مرکز ثقل خوشه C استمن.
ملاحظات کلیدی
- نسبت به انتخاب تصادفی اولیه سانتروئیدها کاملاً حساس است
- این الگوریتم به موارد پرت نیز حساس است.
- نیاز به تعریف k از قبل دارد که همیشه واضح نیست.
برای اعمال خوشهبندی k-means، میتوانید روی تقسیمبندی مشتری و فشردهسازی تصویر از طریق کمیسازی رنگ کار کنید.
نتیجه گیری
امیدوارم این راهنمای مختصر الگوریتم های یادگیری ماشین برای شما مفید بوده باشد. این لیست جامعی از الگوریتم های یادگیری ماشین نیست، بلکه نقطه شروع خوبی است. هنگامی که با این الگوریتمها راحت شدید، ممکن است بخواهید بهبود گرادیان و غیره را اضافه کنید.
همانطور که پیشنهاد شد، می توانید پروژه های ساده ای را با استفاده از این الگوریتم ها ایجاد کنید تا نحوه عملکرد آنها را بهتر درک کنید. اگر علاقه مند هستید، بررسی کنید 5 پروژه یادگیری ماشینی در دنیای واقعی که می توانید این آخر هفته ایجاد کنید.
یادگیری ماشینی مبارک!
درباره بالا پریا سی
Bala Priya C یک توسعه دهنده و نویسنده فنی هندی است. او از کار در تقاطع ریاضیات، برنامه نویسی، علم داده و تولید محتوا لذت می برد. زمینه های مورد علاقه و تخصص او شامل DevOps، علم داده و پردازش زبان طبیعی است. او عاشق خواندن، نوشتن، کدنویسی و قهوه است! در حال حاضر، او در حال کار بر روی یادگیری و به اشتراک گذاری دانش خود با جامعه توسعه دهندگان با ایجاد آموزش ها، راهنماهای نحوه انجام، نظرات و موارد دیگر است. Bala همچنین مروری بر منابع جذاب و آموزش های کدنویسی ایجاد می کند.