5 کتابخانه پایتون برای پیش بینی سری های زمانی پیشرفته
تصویر توسط ناشر
مقدمه
پیش بینی آینده همیشه جام مقدس تجزیه و تحلیل بوده است. چه بهینهسازی لجستیک زنجیره تامین، مدیریت بار شبکه انرژی، یا پیشبینی نوسانات بازار مالی، پیشبینی سریهای زمانی اغلب نیروی محرکه در تصمیمگیری حیاتی است. با این حال، در حالی که این مفهوم ساده است – استفاده از داده های تاریخی برای پیش بینی مقادیر آینده – اجرای آن بسیار دشوار است. داده های دنیای واقعی به ندرت به روندهای خطی و تیز موجود در کتاب های درسی مقدماتی پایبند هستند.
خوشبختانه، اکوسیستم پایتون برای پاسخگویی به این تقاضا تکامل یافته است. چشم انداز از بسته های صرفاً آماری به طیف گسترده ای از کتابخانه ها تغییر یافته است که یادگیری عمیق، خطوط لوله یادگیری ماشین و اقتصاد سنجی کلاسیک را ادغام می کند. اما با گزینه های بسیار زیاد، انتخاب چارچوب مناسب می تواند دشوار باشد.
این مقاله سر و صدا را کاهش می دهد تا روی آن تمرکز کنید 5 کتابخانه قدرتمند پایتون به طور خاص برای پیش بینی سری های زمانی پیشرفته طراحی شده است. ما فراتر از اصول اولیه می رویم تا ابزارهایی را که قادر به مدیریت داده های با ابعاد بالا، فصلی بودن پیچیده و متغیرهای برون زا هستند، کشف کنیم. برای هر کتابخانه، یک نمای کلی در سطح بالا از ویژگیهای عالی آن و یک قطعه کد مختصر «Hello World» ارائه میکنیم تا شما را فوراً شروع کنید.
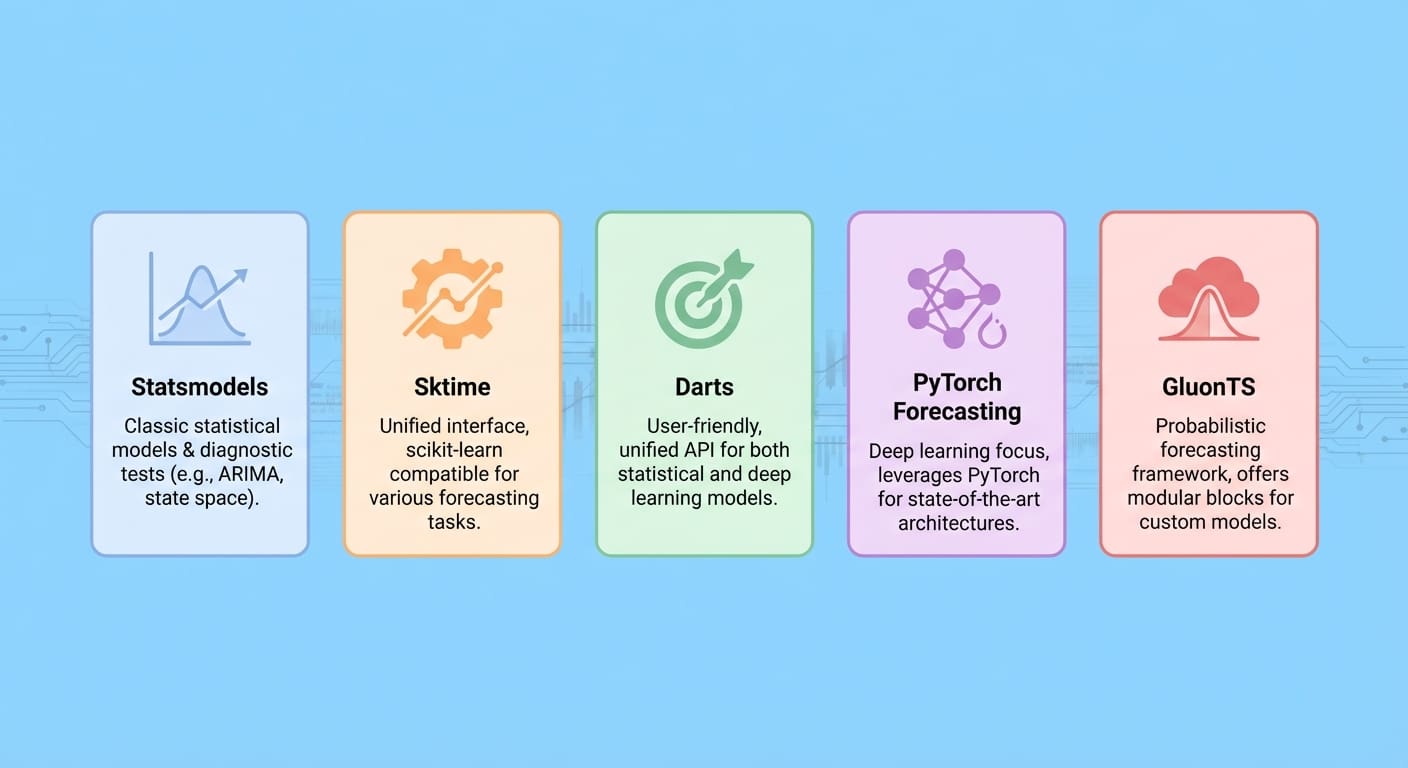
1. مدل های آماری
مدل های آماری بهترین مدلهای پیشبینی سریهای زمانی غیر ثابت و چند متغیره را عمدتاً بر اساس روشهای آماری و اقتصادسنجی ارائه میکند. همچنین کنترل صریح بر فصلی بودن، متغیرهای برون زا و اجزای روند را ارائه می دهد.
این مثال نحوه وارد کردن و استفاده از مدل SARIMAX (Seasonal AutoRegressive Integrated Moving Average with eXogenous regressors) را از کتابخانه نشان می دهد:
از آنجایی که مدل های آماری.tsa.فضای حالت.ساریمکس واردات SARIMAX مدل = SARIMAX(بله، exog=X، سفارش دهید=(1،1،1)، فصلی_سفارش=(1،1،1،12)) پاسخ = مدل.تنظیم کنید() پیش بینی = پاسخ.پیش بینی(اقدامات=12، exog=X_آینده) |
2. زمان اسکی
طرفدار scikit-یادگیری? خبر خوب! زمان اسکی سبک ساختار کتابخانه یادگیری ماشینی محبوب را تقلید می کند و برای کارهای پیش بینی پیشرفته مناسب است، پیش بینی های پانل و چند متغیره را از طریق کاهش مدل یادگیری ماشین و ترکیب خط لوله امکان پذیر می کند.
به عنوان مثال، make_reduction() این تابع یک مدل یادگیری ماشین را به عنوان مؤلفه اصلی خود در نظر می گیرد و از بازگشت برای پیش بینی چندین مرحله از قبل استفاده می کند. توجه داشته باشید که fh “افق پیش بینی” است که امکان پیش بینی را فراهم می کند n مراحل، و X_future در صورتی که مدل از آنها استفاده کند، قرار است حاوی مقادیر آینده ویژگی های برون زا باشد.
از آنجایی که زمان اسکی.پیش بینی.سرودن واردات ساخت_کاهش از آنجایی که یاد بگیرند.با هم واردات RandomForestRegressor پیش بینی کننده = ساخت_کاهش(RandomForestRegressor()، استراتژی=” بازگشتی “) پیش بینی کننده.تنظیم کنید(y_train، X_train) y_pred = پیش بینی کننده.پیش بینی کنید(fh=[1,2,3]، X=X_آینده) |
3. دارت
THE دارت این کتابخانه به دلیل سادگی در مقایسه با سایر چارچوب ها متمایز است. API سطح بالای آن مدلهای یادگیری کلاسیک و عمیق را برای حل مشکلات پیشبینی احتمالی و چند متغیره ترکیب میکند. همچنین به طور موثر متغیرهای کمکی گذشته و آینده را ضبط می کند.
این مثال نشان میدهد که چگونه میتوان از پیادهسازی دارت از تحلیل گسترش پایه عصبی برای مدل پیشبینی سریهای زمانی قابل تفسیر (N-BEATS) استفاده کرد، که یک انتخاب دقیق برای مدیریت الگوهای زمانی پیچیده است.
از آنجایی که دارت.مدل ها واردات مدل NBEATS مدل = مدل NBEATS(input_chunk_length=24، output_chunk_length=12، n_epochs=10) مدل.تنظیم کنید(سری، پر حرف=درست است) پیش بینی = مدل.پیش بینی کنید(n=12) |
5 کتابخانه پایتون برای پیشبینی سریهای زمانی پیشرفته: یک مقایسه ساده
تصویر توسط ناشر
4. PyTorch Forecasts
برای مشکلات پیشبینی با ابعاد بالا و مقیاس بزرگ با دادههای بزرگ، پیش بینی PyTorch یک انتخاب محکم است که مدلهای پیشبینی پیشرفته مانند ترانسفورماتورهای فیوژن زمانی (TFT) و همچنین ابزارهای تفسیرپذیری مدل را ادغام میکند.
قطعه کد زیر به شکلی ساده، استفاده از مدل TFT را نشان می دهد. اگرچه به صراحت نشان داده نشده است، مدلهای این کتابخانه معمولاً از a نمونهسازی میشوند TimeSeriesDataSet (در مثال، dataset این نقش را بازی خواهد کرد).
از آنجایی که pytorch_forecasting واردات ترانسفورماتور فیوژن زمانی tft = ترانسفورماتور فیوژن زمانی.from_dataset(مجموعه داده) tft.تنظیم کنید(train_dataloader) پیش = tft.پیش بینی کنید(val_dataloader) |
5. گلوئون
اخیرا، GluonTS یک کتابخانه مبتنی بر یادگیری عمیق است که در پیشبینی احتمالی تخصص دارد، و آن را برای مدیریت عدم قطعیت در مجموعه دادههای سری زمانی بزرگ، از جمله مواردی با ویژگیهای غیر ثابت، ایدهآل میسازد.
ما با مثالی پایان میدهیم که نحوه وارد کردن ماژولها و کلاسهای GluonTS را نشان میدهد – یک مدل خودبازگشت عمیق (DeepAR) برای پیشبینی سریهای زمانی احتمالی که توزیع مقادیر احتمالی آینده را بهجای پیشبینی نقطهای پیشبینی میکند، آموزش میدهد:
از آنجایی که gluonts.مدل.عمیقا واردات برآوردگر DeepARE از آنجایی که gluonts.MX.مربی واردات مربی برآوردگر = برآوردگر DeepARE(فرکانس=“د”، prediction_length=14، مربی=مربی(دوره ها=5)) پیش بینی کننده = برآوردگر.فرم(train_data) |
نتیجه گیری
انتخاب ابزار مناسب از این زرادخانه بستگی به مبادلات خاص شما بین قابلیت تفسیر، سرعت تمرین و مقیاس داده های شما دارد. در حالی که کتابخانههای کلاسیک مانند Statsmodels دقت آماری را ارائه میکنند، چارچوبهای مدرنی مانند Darts و GluonTS مرزهای آنچه را که یادگیری عمیق میتواند با دادههای زمانی به دست آورد، افزایش میدهد. به ندرت یک راه حل “یک اندازه برای همه” در مورد پیش بینی پیشرفته وجود دارد. بنابراین ما شما را تشویق می کنیم که از این گزیده ها به عنوان سکوی پرتاب برای مقایسه چندین رویکرد با یکدیگر استفاده کنید. با معماری های مختلف و متغیرهای برون زا آزمایش کنید تا ببینید کدام کتابخانه به بهترین وجه تفاوت های ظریف سیگنال های شما را به تصویر می کشد.
ابزار موجود است. اکنون زمان تبدیل این سروصدای تاریخی به بینش های عملی آینده است.