نسل بازیابی-اوت (RAG) رویکردی برای ساختن سیستم های هوش مصنوعی است که یک مدل زبان را با یک منبع دانش خارجی ترکیب می کند. به عبارت ساده ، هوش مصنوعی ابتدا به دنبال اسناد مربوطه (مانند مقاله یا صفحات وب) مربوط به پرس و جو کاربر است و سپس از آن اسناد برای ایجاد پاسخ دقیق تر استفاده می کند. این روش برای کمک به آنها جشن گرفته شده است مدل های بزرگ زبان (LLMS) واقعی بمانید و با بیان پاسخ های آنها در داده های واقعی ، توهم را کاهش دهید.
به طور شهودی ، ممکن است کسی فکر کند که هرچه اسناد بیشتری را بازیابی می کند ، پاسخ آن را بهتر خواهد کرد. با این حال ، تحقیقات اخیر نشان می دهد پیچ و تاب تعجب آور: وقتی صحبت از تغذیه اطلاعات به یک هوش مصنوعی می شود ، گاهی اوقات کمتر بیشتر است.
کمتر اسناد ، پاسخ های بهتر
بوها مطالعه جدید توسط محققان دانشگاه عبری اورشلیم بررسی کرد شماره اسنادی که به یک سیستم RAG داده شده است ، بر عملکرد آن تأثیر می گذارد. بسیار مهم ، آنها مقدار کل متن را ثابت نگه داشتند – به این معنی که اگر اسناد کمتری ارائه می شد ، این اسناد برای پر کردن همان طول مانند بسیاری از اسناد ، کمی گسترش یافتند. به این ترتیب ، هرگونه اختلاف عملکرد می تواند به جای اینکه فقط یک ورودی کوتاه تر داشته باشد ، به مقدار اسناد نسبت داده شود.
محققان از مجموعه داده های پاسخ به سؤال (Musique) با سؤالات چیزهای بی اهمیت استفاده کردند که هر یک در ابتدا با 20 پاراگراف ویکی پدیا جفت شده اند (تنها تعداد کمی از آنها در واقع حاوی جواب هستند که بقیه حواس پرتی هستند). با پیرایش تعداد اسناد از 20 به پایین به 2-4 واقعاً مرتبط – و قرار دادن کسانی که زمینه کمی برای حفظ یک طول مداوم دارند – آنها سناریوهایی را ایجاد کردند که در آن AI قطعات کمتری از مواد برای در نظر گرفتن داشتند ، اما هنوز هم تقریباً همان کلمات برای خواندن بودند.
نتایج قابل توجه بود. در بیشتر موارد ، مدل های هوش مصنوعی با دقت بیشتری به آنها پاسخ می دادند که به جای مجموعه کامل ، اسناد کمتری به آنها داده می شد. عملکرد به طور قابل توجهی بهبود یافته است – در بعضی موارد تا 10 ٪ دقت (نمره F1) وقتی سیستم به جای یک مجموعه بزرگ ، فقط تعداد معدودی از اسناد پشتیبانی را استفاده می کرد. این تقویت ضد انعطاف پذیر در چندین مدل مختلف زبان با منبع باز ، از جمله انواع Llama متا و دیگران مشاهده شد ، که نشان می دهد این پدیده به یک مدل AI واحد گره خورده است.
یک مدل (qwen-2) یک استثناء قابل توجه بود که چندین اسناد را بدون افت نمره اداره می کرد ، اما تقریباً تمام مدل های آزمایش شده با اسناد کمتری به طور کلی عملکرد بهتری داشتند. به عبارت دیگر ، اضافه کردن مطالب مرجع بیشتر فراتر از قطعات مرتبط با کلید در واقع عملکرد آنها را بیشتر از آنچه که کمک کرده است آسیب می رسانند.
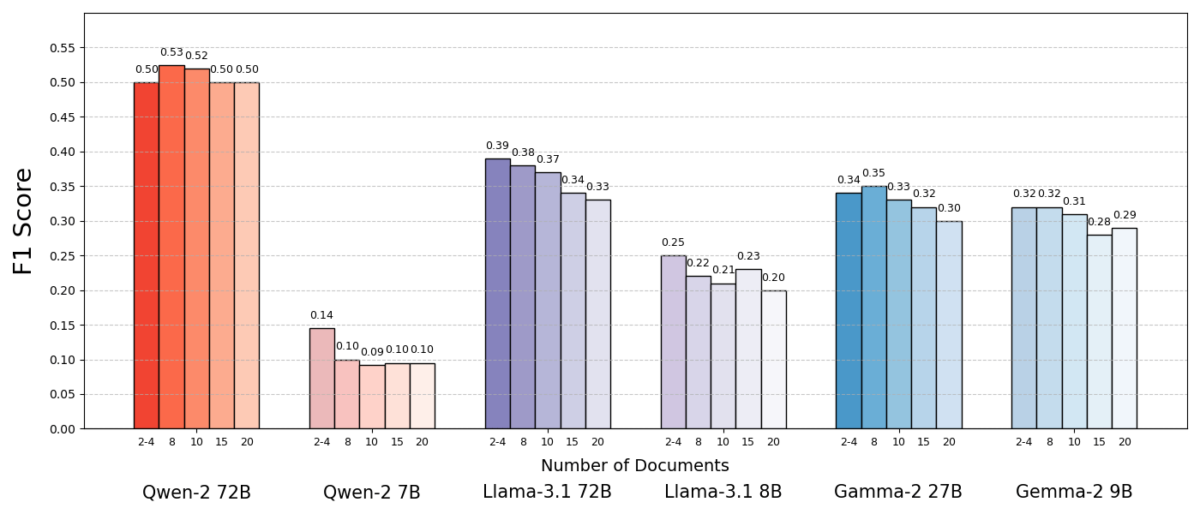
منبع: لوی و همکاران.
چرا این چنین تعجب آور است؟ به طور معمول ، سیستم های RAG با این فرض طراحی می شوند که بازیابی اطلاعات گسترده تری می تواند به هوش مصنوعی کمک کند – از این گذشته ، اگر جواب در چند اسناد اول نباشد ، ممکن است در دهم یا بیستم باشد.
این مطالعه به این اسکریپت می پردازد ، و نشان می دهد که به طور غیرقانونی روی اسناد اضافی می تواند آتش سوزی کند. حتی هنگامی که طول متن ثابت ثابت بود ، صرف حضور بسیاری از اسناد مختلف (هرکدام با متن و کوایر خاص خود) کار پاسخگویی را برای هوش مصنوعی چالش برانگیز تر کرد. به نظر می رسد که فراتر از یک نقطه خاص ، هر سند اضافی سر و صدای بیشتری را نسبت به سیگنال معرفی می کند ، مدل را گیج می کند و توانایی آن را در استخراج پاسخ صحیح مختل می کند.
چرا کمتر می تواند در پارچه بیشتر باشد
این نتیجه “کمتر بیشتر است” هنگامی که ما در نظر بگیریم که چگونه مدل های زبان AI اطلاعات را پردازش می کند ، منطقی است. هنگامی که یک هوش مصنوعی فقط به سایر اسناد داده می شود ، زمینه ای که می بیند متمرکز و عاری از حواس پرتی است ، دقیقاً مانند دانشجویی که فقط صفحات مناسب برای مطالعه به آنها داده شده است.
در مطالعه ، مدل ها وقتی فقط اسناد پشتیبان داده می شوند ، با استفاده از مواد بی ربط ، به طور قابل توجهی بهتر عمل می کنند. زمینه باقیمانده نه تنها کوتاه تر بلکه تمیزتر بود – این حقایق را شامل می شد که مستقیماً به جواب و هیچ چیز دیگری اشاره می کرد. این مدل با داشتن اسناد کمتری برای دستکاری ، می تواند توجه کامل خود را به اطلاعات مربوطه اختصاص دهد و باعث می شود که کمتر از آن استفاده شود.
از طرف دیگر ، هنگامی که بسیاری از اسناد بازیابی شد ، هوش مصنوعی مجبور شد از طریق ترکیبی از محتوای مربوطه و بی ربط الک شود. غالباً این اسناد اضافی “مشابه اما نامربوط” بودند – ممکن است یک موضوع یا کلمات کلیدی را با پرس و جو به اشتراک بگذارند اما در واقع حاوی جواب نیستند. چنین محتوا می تواند مدل را گمراه کند. هوش مصنوعی ممکن است تلاش را برای اتصال نقاط به اسنادی که در واقع منجر به پاسخ صحیح نمی شوند ، یا از این بدتر ، هدر دهد ، یا از این بدتر ، ممکن است اطلاعات را از منابع چندگانه نادرست ادغام کند. این خطر توهم را افزایش می دهد – مواردی که هوش مصنوعی پاسخی ایجاد می کند که قابل قبول به نظر می رسد اما در هیچ منبع واحد وجود ندارد.
در اصل ، تغذیه بیش از حد اسناد به مدل می تواند اطلاعات مفید را رقیق کرده و جزئیات متناقض را معرفی کند ، و تصمیم گیری در مورد واقعیت را برای هوش مصنوعی سخت تر می کند.
جالب اینجاست که محققان دریافتند که اگر اسناد اضافی به وضوح بی ربط باشد (برای مثال ، متن غیر مرتبط تصادفی) ، مدل ها در نادیده گرفتن آنها بهتر بودند. مشکل واقعی از حواس پرتی داده هایی که به نظر می رسد مرتبط است: وقتی همه متون بازیابی شده در موضوعات مشابه قرار دارند ، هوش مصنوعی فرض می کند که باید از همه آنها استفاده کند ، و ممکن است تلاش کند تا بگوییم کدام جزئیات در واقع مهم هستند. این با مشاهده مطالعه هماهنگ است حواس پرتی تصادفی باعث سردرگمی کمتری نسبت به حواس پرتی های واقع گرایانه شد در ورودی هوش مصنوعی می تواند مزخرفات آشکار را فیلتر کند ، اما اطلاعات ظریف و بی نظیر یک تله نرم و صاف است-تحت پوشش ارتباط قرار می گیرد و جواب را از بین می برد. با کاهش تعداد اسناد فقط به موارد واقعی ، از تنظیم این تله ها در وهله اول خودداری می کنیم.
همچنین یک مزیت عملی وجود دارد: بازیابی و پردازش اسناد کمتری ، سربار محاسباتی را برای یک سیستم RAG کاهش می دهد. هر سندی که به آن کشیده می شود باید مورد تجزیه و تحلیل قرار گیرد (تعبیه شده ، خوانده شده و در آن مدل حضور داشته باشد) ، که از منابع زمان و محاسباتی استفاده می کند. از بین بردن اسناد اضافی باعث می شود سیستم کارآمدتر شود – می تواند پاسخ سریعتر و با هزینه کمتری پیدا کند. در سناریوهایی که با تمرکز روی منابع کمتری ، دقت بهبود یافته است ، ما یک برد برنده می گیریم: پاسخ های بهتر و یک فرآیند لاغر و کارآمدتر.

منبع: لوی و همکاران.
Rethinking Rag: جهت های آینده
این شواهد جدید نشان می دهد که کیفیت اغلب در بازیابی مقدار کمیت می کند ، پیامدهای مهمی برای آینده سیستم های هوش مصنوعی دارد که به دانش خارجی متکی هستند. این نشان می دهد که طراحان سیستم های RAG باید در اولویت قرار دادن فیلتر هوشمند و رتبه بندی اسناد از حجم کامل قرار بگیرند. به جای واکشی 100 گذرگاه ممکن و امیدوار بودن جواب در جایی در آنجا دفن شده است ، ممکن است عاقلانه تر باشد که فقط چند مورد برتر بسیار مهم را بدست آورید.
نویسندگان این مطالعه بر لزوم روشهای بازیابی برای “تعادل بین ارتباط و تنوع” در اطلاعاتی که به یک مدل ارائه می دهند ، تأکید می کنند. به عبارت دیگر ، ما می خواهیم پوشش کافی از موضوع را برای پاسخ به این سؤال ارائه دهیم ، اما نه آنقدر که واقعیت های اصلی در دریایی از متن عجیب و غریب غرق می شوند.
محققان با حرکت به جلو ، به احتمال زیاد تکنیک هایی را کشف می کنند که به مدل های AI کمک می کند تا چندین اسناد را با لطف بیشتری اداره کنند. یک رویکرد این است که سیستم های بهتر رتریور را توسعه دهید یا مجدداً رتبه بندی کنند که می توانند مشخص کنند که کدام اسناد واقعاً ارزش را اضافه می کنند و کدام یک از آنها فقط درگیری را معرفی می کنند. زاویه دیگر در حال بهبود مدل های زبان است: اگر یک مدل (مانند QWEN-2) بدون از دست دادن دقت موفق به کنار آمدن با بسیاری از اسناد شود ، بررسی می کند که چگونه آن را آموزش داده یا ساختار یافته است می تواند سرنخ هایی را برای ساخت مدل های دیگر ارائه دهد. شاید مدل های بزرگ زبان در آینده سازوکارهایی را برای تشخیص اینکه چه زمانی دو منبع می گویند همان چیز (یا متناقض با یکدیگر) را در بر می گیرند و بر این اساس تمرکز می کنند. هدف این است که مدل ها بتوانند از منابع مختلفی استفاده کنند بدون اینکه طعمه سردرگمی شوند – به طور موثری بهترین های هر دو جهان را بدست آورند (وسعت اطلاعات و وضوح تمرکز).
همچنین شایان ذکر است که سیستم های AI ویندوز زمینه های بزرگتر را به دست می آورند (امکان خواندن متن بیشتر به طور همزمان) ، صرفاً ریختن داده های بیشتر در سریع یک گلوله نقره ای نیست. زمینه بزرگتر به طور خودکار به معنای درک بهتر نیست. این مطالعه نشان می دهد که حتی اگر یک هوش مصنوعی بتواند 50 صفحه را به طور همزمان بخواند ، به 50 صفحه از اطلاعات با کیفیت مختلط می دهد ممکن است نتیجه خوبی نداشته باشد. این مدل هنوز از داشتن محتوای مربوط به سرپرستی و مرتبط با آن استفاده می کند ، نه یک زباله غیرقابل تفکیک. در حقیقت ، بازیابی هوشمند ممکن است در دوران ویندوزهای زمینه غول پیکر بسیار مهم تر شود – برای اطمینان از اینکه ظرفیت اضافی برای دانش ارزشمند به جای سر و صدا استفاده می شود.
یافته ها از “اسناد بیشتر ، همان طول” (مقاله با عنوان مناسب) یک بررسی مجدد فرضیات ما را در تحقیقات هوش مصنوعی تشویق کنید. گاهی اوقات ، تغذیه با هوش مصنوعی تمام داده های ما به همان اندازه که فکر می کنیم مؤثر نیست. ما با تمرکز بر روی بخش های مرتبط با اطلاعات ، نه تنها صحت پاسخ های تولید شده توسط AI را بهبود می بخشیم بلکه سیستم ها را نیز کارآمدتر و راحت تر می کنیم. این یک درس ضد انعطاف پذیر است ، اما یکی از آنها دارای نتایج هیجان انگیز است: سیستم های RAG آینده ممکن است با انتخاب دقیق کمتر و اسناد بهتر برای بازیابی ، باهوش تر و لاغر باشند.