مدل های بزرگ زبان (LLM) مانند کلود روش استفاده ما از فناوری را تغییر داده اند. آنها ابزارهای قدرت مانند چت بابات ، به نوشتن مقاله و حتی ایجاد شعر کمک می کنند. اما علی رغم توانایی های شگفت انگیز آنها ، این مدل ها از بسیاری جهات هنوز رمز و راز هستند. مردم غالباً آنها را “جعبه سیاه” می نامند زیرا می توانیم ببینیم که آنها چه می گویند اما نه چگونه آنها را تشخیص می دهند. این عدم درک باعث ایجاد مشکلاتی می شود ، به خصوص در زمینه های مهم مانند پزشکی یا قانون ، جایی که اشتباهات یا تعصبات پنهان می تواند آسیب واقعی وارد کند.
درک چگونگی کار LLMS برای اعتماد به نفس ضروری است. اگر نتوانیم توضیح دهیم که چرا یک مدل پاسخ خاصی داده است ، اعتماد به نتایج آن ، به ویژه در مناطق حساس دشوار است. تفسیر همچنین به شناسایی و رفع تعصبات یا خطاها کمک می کند ، و اطمینان حاصل می شود که مدل ها ایمن و اخلاقی هستند. به عنوان مثال ، اگر یک مدل به طور مداوم از دیدگاه های خاص حمایت کند ، دانستن اینکه چرا می تواند به توسعه دهندگان کمک کند تا آن را اصلاح کنند. این نیاز به وضوح همان چیزی است که تحقیقات را در شفاف تر کردن این مدل ها انجام می دهد.
انسان شناسی ، شرکت پشت کلود، در تلاش برای باز کردن این جعبه سیاه بوده است. آنها پیشرفت مهیج در فهمیدن چگونگی تفکر LLM ها داشته اند ، و این مقاله به بررسی موفقیت های آنها در درک فرآیندهای کلود می پردازد.
نقشه برداری از افکار کلود
در اواسط سال 2012 ، تیم Anthropic یک هیجان انگیز کرد موفقیتبشر آنها یک “نقشه” اساسی در مورد چگونگی پردازش اطلاعات کلود ایجاد کردند. با استفاده از تکنیکی به نام دیکشنریآنها میلیون ها الگوی در “مغز” کلود – شبکه عصبی آن را پیدا کردند. هر الگوی یا “ویژگی” به یک ایده خاص متصل می شود. به عنوان مثال ، برخی از ویژگی ها به شهرهای Claude ، افراد مشهور یا اشتباهات برنامه نویسی کمک می کند. برخی دیگر با مباحث پیچیده تر ، مانند تعصب جنسیتی یا رازداری ، گره می زنند.
محققان دریافتند که این ایده ها در سلولهای عصبی جداگانه نیستند. درعوض ، آنها در بسیاری از نورون های شبکه کلود پخش می شوند ، که هر نورون به ایده های مختلف کمک می کند. این همپوشانی در وهله اول برای کشف این ایده ها به سختی باعث شد تا این ایده ها را بفهمد. اما با مشاهده این الگوهای مکرر ، محققان Anthropic شروع به رمزگشایی نحوه سازماندهی کلود افکار خود کردند.
ردیابی استدلال کلود
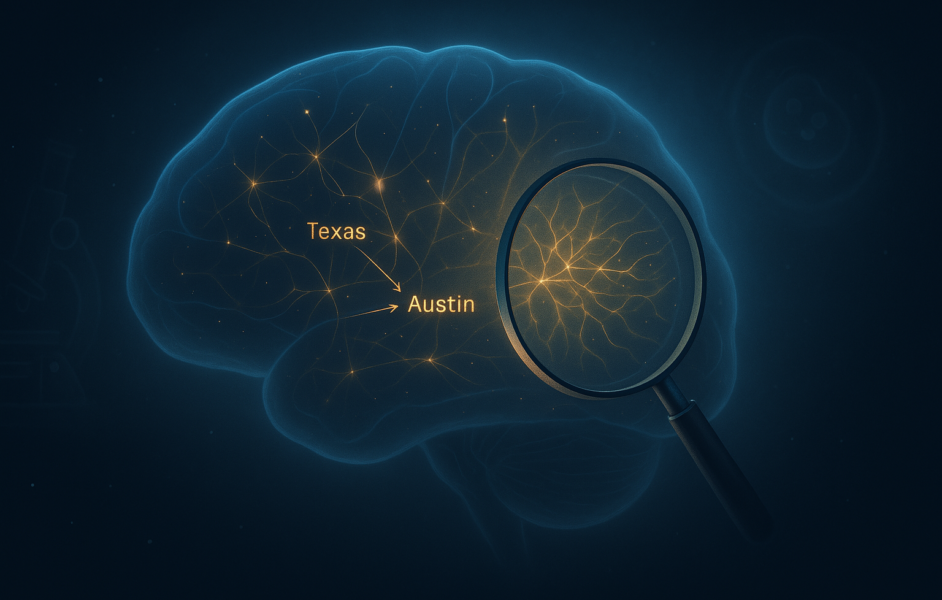
در مرحله بعد ، انسان شناسی می خواست ببیند که چگونه کلود از این افکار برای تصمیم گیری استفاده می کند. آنها اخیراً ابزاری به نام ساخته اند نمودارهای انتساب، که مانند یک راهنمای گام به گام برای روند تفکر کلود کار می کند. هر نقطه در نمودار ایده ای است که در ذهن کلود روشن می شود و فلش ها نشان می دهد که چگونه یک ایده به مرحله بعدی می رسد. این نمودار به محققان این امکان را می دهد تا چگونه کلود یک سؤال را به یک پاسخ تبدیل کند.
برای درک بهتر کار نمودارهای انتساب ، این مثال را در نظر بگیرید: وقتی از وی سؤال شد ، “سرمایه دولت با دالاس چیست؟” کلود باید متوجه شود که دالاس در تگزاس است ، سپس به یاد می آورد که پایتخت تگزاس آستین است. نمودار انتساب این فرایند دقیق را نشان داد – بخشی از Claude پرچم گذاری “تگزاس” ، که منجر به انتخاب قسمت دیگری “آستین” شد. این تیم حتی آن را با استفاده از قسمت “تگزاس” آزمایش کرد و مطمئناً جواب را تغییر داد. این نشان می دهد که کلود فقط حدس نمی زند – این مشکل را انجام می دهد ، و اکنون می توانیم آن را تماشا کنیم.
چرا این مهم است: قیاس از علوم بیولوژیکی
برای دیدن اینکه چرا این مسئله اهمیت دارد ، راحت است که در مورد برخی از تحولات مهم در علوم بیولوژیکی فکر کنید. درست همانطور که اختراع میکروسکوپ به دانشمندان اجازه می دهد سلول ها را کشف کنند – بلوک های ساختمانی پنهان زندگی – این ابزارهای تفسیر به محققان هوش مصنوعی اجازه می دهند تا بلوک های ساختمانی را در مدلهای فکر کنند. و درست همانطور که نقشه برداری از مدارهای عصبی در مغز یا توالی ژنوم ، راه را برای پیشرفت های پزشکی هموار می کند ، نقشه برداری از کارهای داخلی کلود می تواند راه را برای هوش قابل اطمینان تر و کنترل کننده دستگاه هموار کند. این ابزارهای تفسیر می توانند نقش مهمی ایفا کنند و به ما کمک می کنند تا به روند تفکر مدل های هوش مصنوعی بپردازیم.
چالش ها
حتی با وجود این همه پیشرفت ، ما هنوز از درک کامل LLM هایی مانند کلود دور هستیم. در حال حاضر ، نمودارهای انتساب فقط می توانند در مورد یک در چهار تصمیمات کلود توضیح دهند. در حالی که نقشه ویژگی های آن چشمگیر است ، بخشی از آنچه در مغز کلود اتفاق می افتد را در بر می گیرد. با میلیاردها پارامتر ، کلود و سایر LLM ها برای هر کار محاسبات بی شماری را انجام می دهند. ردیابی هرکدام برای دیدن اینکه چگونه یک پاسخ پاسخ می دهد مانند تلاش برای دنبال کردن هر نورون در مغز انسان در طی یک فکر واحد.
چالش “توهین. ” بعضی اوقات ، مدلهای هوش مصنوعی پاسخ هایی را ایجاد می کنند اما در واقع نادرست هستند – مانند با اطمینان با بیان یک واقعیت نادرست.
تعصب یکی دیگر از موانع مهم است. مدل های هوش مصنوعی از مجموعه داده های وسیعی که از اینترنت جدا شده اند ، می آموزند ، که ذاتاً تعصبات انسانی را حمل می کنند – استرسپ ، پیش داوری و سایر نقص های اجتماعی. اگر کلود این تعصبات را از آموزش خود بیرون بیاورد ، ممکن است آنها را در پاسخ های خود منعکس کند. باز کردن جایی که این تعصبات سرچشمه می گیرد و چگونه آنها بر استدلال مدل تأثیر می گذارند ، یک چالش پیچیده است که هم به راه حل های فنی و هم در نظر گرفتن دقیق داده ها و اخلاق نیاز دارد.
خط پایین
کار Anthropic در ساخت مدل های بزرگ زبان (LLM) مانند Claude قابل درک تر یک قدم مهم در شفافیت هوش مصنوعی است. آنها با آشکار کردن چگونگی پردازش CLAUDE اطلاعات و تصمیم گیری ، آنها به سمت پرداختن به نگرانی های کلیدی در مورد مسئولیت پذیری هوش مصنوعی می پردازند. این پیشرفت در را برای ادغام ایمن LLM ها در بخش های مهم مانند مراقبت های بهداشتی و قانون ، جایی که اعتماد و اخلاق بسیار مهم است ، باز می کند.
با توسعه روش های بهبود تفسیر ، صنایعی که در مورد اتخاذ هوش مصنوعی محتاط بوده اند ، اکنون می توانند دوباره تجدید نظر کنند. مدل های شفاف مانند کلود مسیری روشنی را برای آینده هوش مصنوعی فراهم می کنند – مواردی که نه تنها هوش انسانی را تکرار می کنند بلکه استدلال آنها را نیز توضیح می دهند.