
یک مقاله اخیر از تحقیقات LG AI نشان می دهد که مجموعه داده های “باز” که برای آموزش مدل های هوش مصنوعی استفاده می شود ممکن است احساس امنیتی کاذب ارائه دهد – دریافت که تقریباً چهار از پنج مجموعه داده هوش مصنوعی با عنوان “قابل استفاده تجاری” در واقع حاوی خطرات قانونی پنهان است.
چنین خطرات ناشی از درج مطالب دارای حق چاپ کپی رایت نشده تا شرایط محدود کننده صدور مجوز که در اعماق وابستگی های یک مجموعه داده دفن شده است. اگر یافته های این مقاله دقیق باشد ، شرکت هایی که به مجموعه داده های عمومی تکیه می کنند ممکن است نیاز به تجدید نظر در خطوط لوله هوش مصنوعی فعلی خود داشته باشند یا در معرض خطر قرار گرفتن در معرض حقوقی پایین دست قرار بگیرند.
محققان یک رادیکال و به طور بالقوه بحث برانگیز راه حل: نمایندگان انطباق مبتنی بر هوش مصنوعی قادر به اسکن و حسابرسی تاریخچه مجموعه داده ها سریعتر و دقیق تر از وکلای انسانی هستند.
در مقاله آمده است:
این مقاله طرفداری می کند که خطر قانونی مجموعه داده های آموزش AI فقط با بررسی شرایط مجوز سطح سطح قابل تعیین نیست. تجزیه و تحلیل کامل و پایان یافته از توزیع مجدد مجموعه داده ها برای اطمینان از انطباق ضروری است.
از آنجا که چنین تجزیه و تحلیل به دلیل پیچیدگی و مقیاس آن فراتر از توانایی های انسانی است ، عوامل هوش مصنوعی می توانند با انجام آن با سرعت و دقت بیشتر ، این شکاف را برطرف کنند. بدون اتوماسیون ، خطرات قانونی بحرانی تا حد زیادی ناشناخته باقی مانده است ، و توسعه اخلاقی هوش مصنوعی و پایبندی نظارتی را به خطر می اندازد.
“ما از جامعه تحقیقاتی هوش مصنوعی می خواهیم تا تجزیه و تحلیل حقوقی نهایی را به عنوان یک الزام اساسی بشناسد و رویکردهای AI محور را به عنوان مسیر مناسب برای انطباق مجموعه داده های مقیاس پذیر اتخاذ کند.”
سیستم خودکار محققان با بررسی 2،852 مجموعه داده محبوب که از نظر تجاری قابل استفاده هستند ، نشان داد که تنها 605 (حدود 21 ٪) پس از ردیابی تمام اجزای و وابستگی های آنها ، در واقع از نظر قانونی برای تجاری سازی ایمن بودند
در مقاله جدید عنوان شده است به مجوزهایی که می بینید اعتماد نکنید-انطباق با مجموعه داده ها نیاز به ردیابی چرخه عمر AI در مقیاس عظیم دارد، و از هشت محقق در LG AI Research آمده است.
حقوق و اشتباهات
نویسندگان برجسته را برجسته می کنند چالش در مواجهه با شرکت هایی که با توسعه هوش مصنوعی در یک منظره حقوقی به طور فزاینده ای نامشخص هستند – همانطور که ذهنیت سابق “استفاده عادلانه” در اطراف آموزش مجموعه داده ها جای خود را به یک محیط شکسته می دهد که در آن حمایت های قانونی نامشخص است و بندر ایمن دیگر تضمین نمی شود.
به عنوان یک انتشار اشاره کرد اخیراً ، شرکت ها در مورد منابع داده های آموزشی خود به طور فزاینده ای دفاعی می شوند. نویسنده آدام بیوک نظرات*:
‘[While] Openai منابع اصلی داده های GPT-3 را فاش کرد ، مقاله ای که GPT-4 را معرفی می کند فاش شده فقط این که داده هایی که این مدل آموزش داده شده است ترکیبی از “داده های در دسترس عموم (مانند داده های اینترنتی) و داده های دارای مجوز از ارائه دهندگان شخص ثالث” بود.
“انگیزه های این حرکت به دور از شفافیت توسط توسعه دهندگان هوش مصنوعی ، که در بسیاری موارد به هیچ وجه توضیحی نداده اند ، در هیچ جزئیات خاصی بیان نشده است.
“از طرف خود ، اوپای تصمیم خود را مبنی بر انتشار جزئیات بیشتر در مورد GPT-4 بر اساس نگرانی های مربوط به” چشم انداز رقابتی و پیامدهای ایمنی مدلهای در مقیاس بزرگ “، بدون هیچ توضیحی در این گزارش ، توجیه کرد.
شفافیت می تواند یک اصطلاح ناعادلانه باشد – یا به سادگی یک اشتباه. به عنوان مثال ، پرچمدار Adobe شبکیه مدل تولیدی ، که بر روی داده های سهام آموزش داده شده است که Adobe حق بهره برداری از آن را دارد ، ظاهراً به مشتریان اطمینان می داد که در مورد قانونی بودن استفاده خود از سیستم. بعداً ، برخی شواهد پدیدار شد این که گلدان داده های Firefly با داده های بالقوه دارای حق چاپ از سیستم عامل های دیگر “غنی شده” شده است.
همانطور که ما در اوایل این هفته بحث شد، ابتکارات در حال رشد وجود دارد که برای اطمینان از رعایت مجوز در مجموعه داده ها طراحی شده است ، از جمله مواردی که فقط فیلم های YouTube را با مجوزهای انعطاف پذیر Creative Commons Script می کند.
مشکل این است که مجوزها به خودی خود ممکن است اشتباه یا خطا به اشتباه باشند ، همانطور که به نظر می رسد تحقیقات جدید نشان می دهد.
بررسی مجموعه داده های منبع باز
تهیه یک سیستم ارزیابی مانند Nexus نویسندگان دشوار است که زمینه به طور مداوم در حال تغییر باشد. بنابراین در مقاله آمده است که سیستم چارچوب انطباق داده های Nexus بر اساس “سابقه های مختلف و دلایل قانونی در این مقطع زمانی” است.
Nexus از یک عامل محور AI به نام استفاده می کند ناقص بودن برای انطباق خودکار داده ها. AutoCplummiance از سه ماژول اصلی تشکیل شده است: یک ماژول ناوبری برای اکتشاف وب. یک ماژول پاسخ پاسخ (QA) برای استخراج اطلاعات ؛ و یک ماژول امتیاز دهی برای ارزیابی ریسک قانونی.
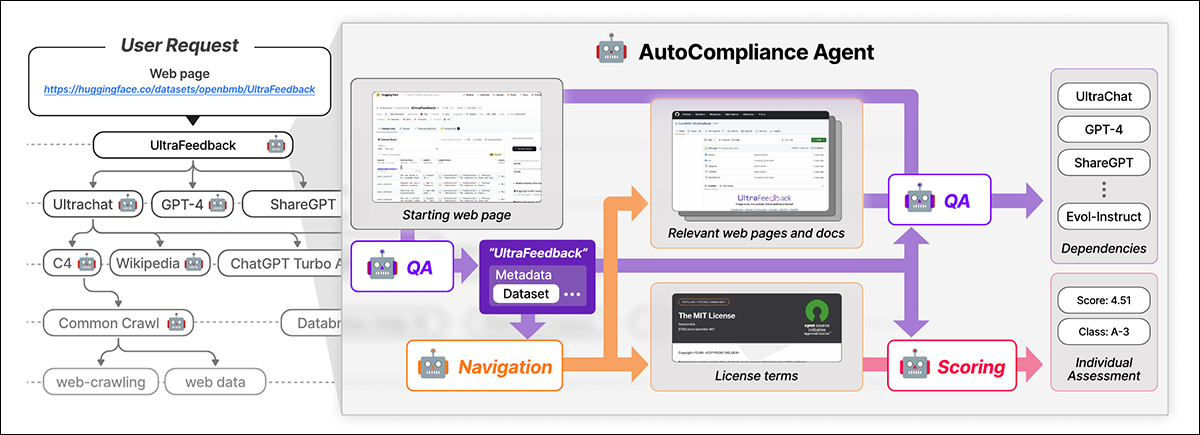
AutoCplumbliance با یک صفحه وب ارائه شده توسط کاربر آغاز می شود. هوش مصنوعی جزئیات کلیدی را استخراج می کند ، منابع مرتبط را جستجو می کند ، شرایط و وابستگی های مجوز را مشخص می کند و نمره ریسک قانونی را تعیین می کندبشر منبع: https://arxiv.org/pdf/2503.02784
این ماژول ها از مدل های AI تنظیم شده خوب ، از جمله بازپرداخت مدل ، روی داده های مصنوعی و دارای برچسب انسانی آموزش دیده است. AutoCoctive همچنین از یک بانک اطلاعاتی برای نتایج ذخیره سازی برای افزایش کارآیی استفاده می کند.
AutoCoctive با URL مجموعه داده های ارائه شده توسط کاربر شروع می شود و آن را به عنوان موجودیت ریشه ، در جستجوی شرایط و وابستگی های مجوز خود و به صورت بازگشتی به ردیابی مجموعه داده های مرتبط برای ایجاد نمودار وابستگی مجوز می پردازد. پس از ترسیم همه اتصالات ، نمرات انطباق را محاسبه می کند و طبقه بندی ریسک را تعیین می کند.
چارچوب انطباق داده ها که در کار جدید بیان شده است ، مختلف را مشخص می کند« انواع موجودیت درگیر در چرخه عمر داده ، از جمله مجموعه داده ها، که ورودی اصلی برای آموزش AI را تشکیل می دهد. نرم افزار پردازش داده ها و مدل های هوش مصنوعی، که برای تبدیل و استفاده از داده ها استفاده می شود. وت ارائه دهندگان خدمات پلتفرم، که مدیریت داده ها را تسهیل می کند.
این سیستم با در نظر گرفتن این اشخاص مختلف و وابستگی متقابل آنها ، خطرات قانونی را به طور کامل ارزیابی می کند ، و فراتر از ارزیابی روتختی مجوزهای مجموعه داده ها حرکت می کند تا یک اکوسیستم گسترده تر از مؤلفه های درگیر در توسعه هوش مصنوعی را شامل شود.
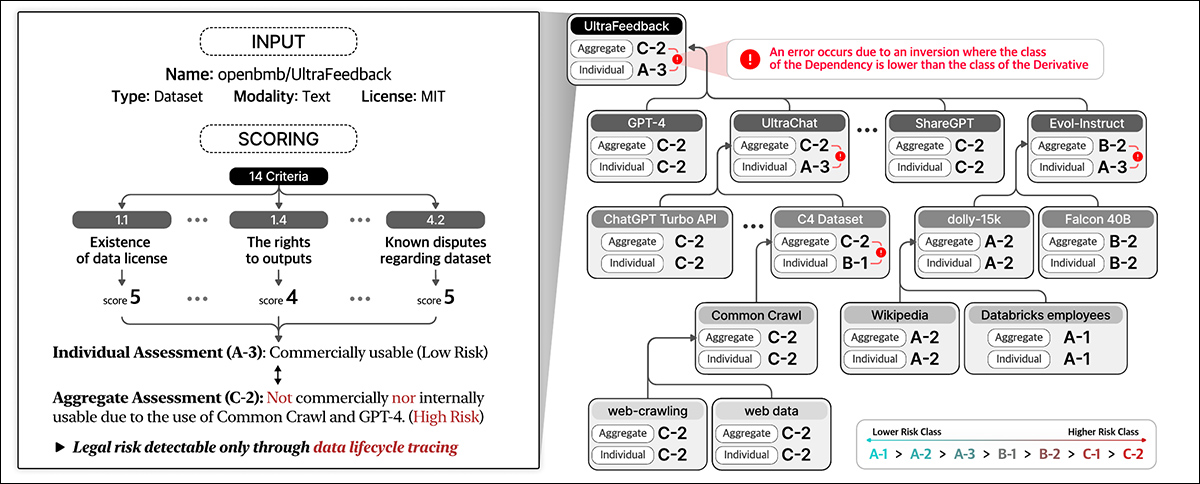
انطباق داده ها ریسک قانونی را در طول چرخه کامل داده ها ارزیابی می کند. این نمرات را بر اساس جزئیات مجموعه داده و در 14 معیار ، طبقه بندی اشخاص جداگانه و جمع آوری ریسک در بین وابستگی ها اختصاص می دهد.
آموزش و معیارها
نویسندگان URL های 1000 مجموعه داده برتر بارگیری شده را در بغل کردن صورت استخراج کردند و به طور تصادفی 216 مورد را به زیر نمونه برداری می کردند تا یک مجموعه آزمایش را تشکیل دهند.
مدل Exaone بود با ریز تنظیم شده در مجموعه داده های سفارشی نویسندگان ، با ماژول ناوبری و ماژول پاسخ به سؤال داده های مصنوعی، و ماژول امتیاز دهی با استفاده از داده های دارای برچسب انسانی.
برچسب های حقیقت زمین توسط پنج کارشناس حقوقی که حداقل 31 ساعت در کارهای مشابه آموزش دیده بودند ، ایجاد شدند. این کارشناسان انسانی به طور دستی وابستگی ها و شرایط مجوز را برای 216 مورد آزمایش شناسایی کرده اند ، سپس یافته های خود را از طریق بحث جمع و تصفیه کردند.
با سیستم خودکارآمدی آموزش دیده و کالیبره شده انسان در برابر آزمایش شده chatgpt-4o وت دفع طرفدار ، به ویژه وابستگی های بیشتری در شرایط مجوز کشف شد:
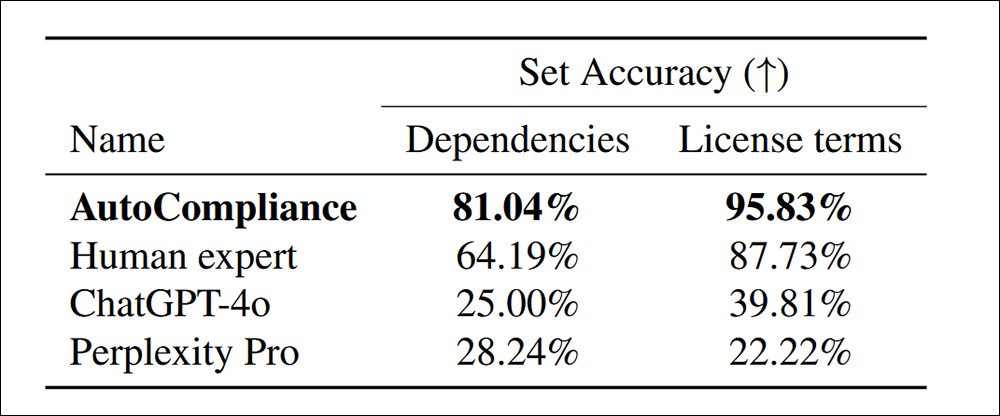
دقت در شناسایی وابستگی ها و شرایط مجوز برای 216 مجموعه داده ارزیابی.
در مقاله آمده است:
“اتوپلندی به طور قابل توجهی از سایر عوامل و متخصص انسان بهتر عمل می کند و در هر کار به دقت 81.04 ٪ و 95.83 ٪ رسیده است. در مقابل ، هر دو ChatGPT-4O و PERPELEXITY PRO به ترتیب دقت نسبتاً کمی را برای کارهای منبع و مجوز نشان می دهند.
“این نتایج عملکرد برتر اتم را نشان می دهد ، و اثربخشی آن در انجام هر دو کار با دقت قابل توجه را نشان می دهد ، در حالی که همچنین نشانگر شکاف عملکرد قابل توجهی بین مدلهای مبتنی بر هوش مصنوعی و متخصص انسانی در این حوزه ها است.”
از نظر کارآیی ، رویکرد خودکار سازی فقط 53.1 ثانیه طول کشید ، بر خلاف 2418 ثانیه برای ارزیابی معادل انسانی در همان کارها.
علاوه بر این ، عملکرد ارزیابی 0.29 دلار در مقایسه با 207 دلار برای متخصصان انسانی هزینه دارد. لازم به ذکر است که این مبتنی بر اجاره یک گره GCP A2-MEGAGPU-16GPU ماهانه با نرخ 14،225 دلار در هر ماه است-نشان می دهد که این نوع از راندمان در درجه اول مربوط به یک عملیات در مقیاس بزرگ است.
تحقیق مجموعه داده ها
برای تجزیه و تحلیل ، محققان 3،612 مجموعه داده را با ترکیب 3000 مجموعه داده بارگیری شده از بغل کردن صورت با 612 مجموعه داده از 2023 انتخاب کردند ابتکار عمل ارائه دادهبشر
در مقاله آمده است:
“با شروع از 3،612 موجود هدف ، ما در مجموع 17429 موجود منحصر به فرد را شناسایی کردیم ، جایی که 13،817 نهاد به عنوان وابستگی مستقیم یا غیرمستقیم موجودات هدف ظاهر شدند.
“برای تجزیه و تحلیل تجربی ما ، ما یک موجودیت و نمودار وابستگی مجوز آن را در نظر می گیریم که اگر یک وابستگی و ساختار چند لایه ای در صورت داشتن یک یا چند وابستگی داشته باشد ، یک ساختار تک لایه ای داشته باشد.
“از 3،612 مجموعه داده هدف ، 2،086 (57.8 ٪) ساختارهای چند لایه ای داشتند ، در حالی که 1.526 نفر دیگر (42.2 ٪) ساختارهای تک لایه ای داشتند که هیچ وابستگی ندارند.”
مجموعه داده های دارای حق چاپ فقط می توانند با مرجع قانونی توزیع شوند ، که ممکن است از مجوز ، استثناء قانون حق چاپ یا شرایط قرارداد تهیه شود. توزیع مجدد غیرمجاز می تواند منجر به عواقب قانونی ، از جمله نقض حق چاپ یا نقض قرارداد شود. بنابراین شناسایی واضح عدم رعایت ضروری است.
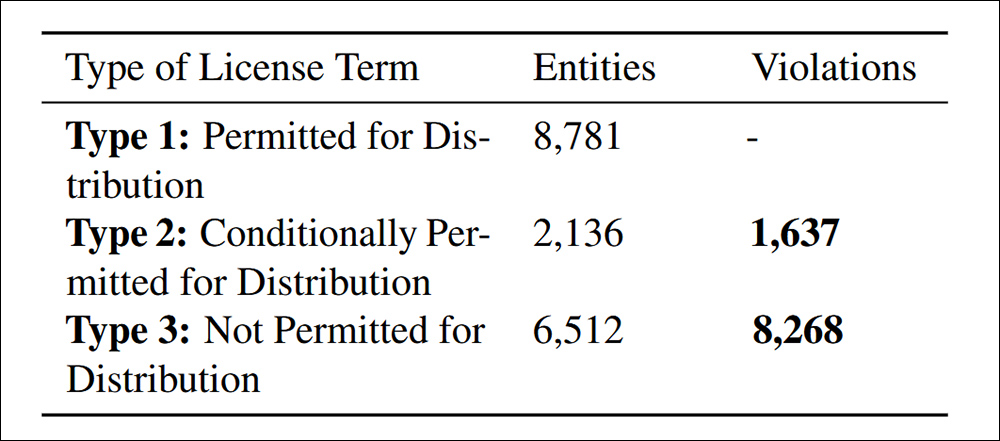
نقض توزیع در زیر معیار استناد شده مقاله 4.4. انطباق داده ها
در این مطالعه 9905 مورد از توزیع مجدد مجموعه داده های غیر سازگار ، به دو دسته تقسیم شده است: 83.5 ٪ صریحاً طبق شرایط صدور مجوز ممنوع بودند و باعث می شود توزیع مجدد به یک نقض قانونی واضح باشد. و 16.5 ٪ مجموعه داده های مربوط به شرایط مجوز متناقض ، جایی که توزیع مجدد در تئوری مجاز بود اما نتوانست شرایط مورد نیاز را برآورده کند ، و باعث ایجاد خطر قانونی پایین دست می شود.
نویسندگان اعتراف می کنند که معیارهای خطر ارائه شده در Nexus جهانی نیستند و ممکن است از نظر صلاحیت و کاربرد هوش مصنوعی متفاوت باشد ، و پیشرفت های آینده باید در سازگاری با تغییر مقررات جهانی ضمن تصفیه بررسی حقوقی AI متمرکز باشد.
پایان
این یک مقاله طولانی و عمدتاً غیر دوستانه است ، اما شاید بزرگترین عامل عقب افتاده در تصویب صنعت فعلی هوش مصنوعی باشد – این احتمال که ظاهراً داده های “باز” بعداً توسط اشخاص ، افراد و سازمان های مختلف ادعا می شود.
تحت DMCA ، تخلفات به طور قانونی می تواند جریمه های گسترده ای در یک هر روز پایه در مواردی که تخلفات می تواند به میلیون ها نفر برسد ، مانند مواردی که توسط محققان کشف شده است ، مسئولیت قانونی بالقوه واقعاً قابل توجه است.
علاوه بر این ، شرکت هایی که می توانند ثابت کنند که از داده های بالادست بهره مند شده اند نمی توانند (طبق معمول) حداقل در بازار تأثیرگذار ایالات متحده ، نادانی را بهانه ای ادعا کنید. در حال حاضر آنها هیچ ابزار واقع بینانه ای برای نفوذ به پیامدهای هزارتوی دفن شده در توافق نامه های مجوز مجموعه داده های منبع باز ندارند.
مشکل در تدوین سیستمی مانند Nexus این است که به اندازه کافی چالش برانگیز باشد که بتوانید آن را به صورت هر حالت در داخل ایالات متحده یا یک پایه در داخل اتحادیه اروپا کالیبراسیون کنید. چشم انداز ایجاد یک چارچوب واقعاً جهانی (نوعی “Interpol برای استحکام داده”) نه تنها با انگیزه های متناقض دولت های متنوع درگیر تضعیف می شود ، بلکه این واقعیت است که هم این دولت ها و هم قوانین فعلی آنها در این زمینه دائماً در حال تغییر هستند.
* جایگزینی من از لینک های لینک برای استناد به نویسندگان.
« شش نوع در مقاله تجویز می شود ، اما دو مورد نهایی تعریف نشده اند.
اولین بار جمعه ، 7 مارس 2025 منتشر شد