
درک RAG III: بازیابی و طبقه بندی مجدد با ادغام
تصویر ویرایشگر | میان ترم و کانوا
مقالات قبلی این مجموعه را بررسی کنید:
با ارائه آنچه که RAG چیست، چرا در زمینه مدلهای زبان بزرگ (LLM) اهمیت دارد و یک سیستم بازیابی و تولید معمولی برای RAG چگونه به نظر میرسد، سومین مقاله از مجموعه «درک RAG» رویکرد بهبود یافتهای را بررسی میکند. ساخت سیستم های RAG: بازیابی همجوشی.
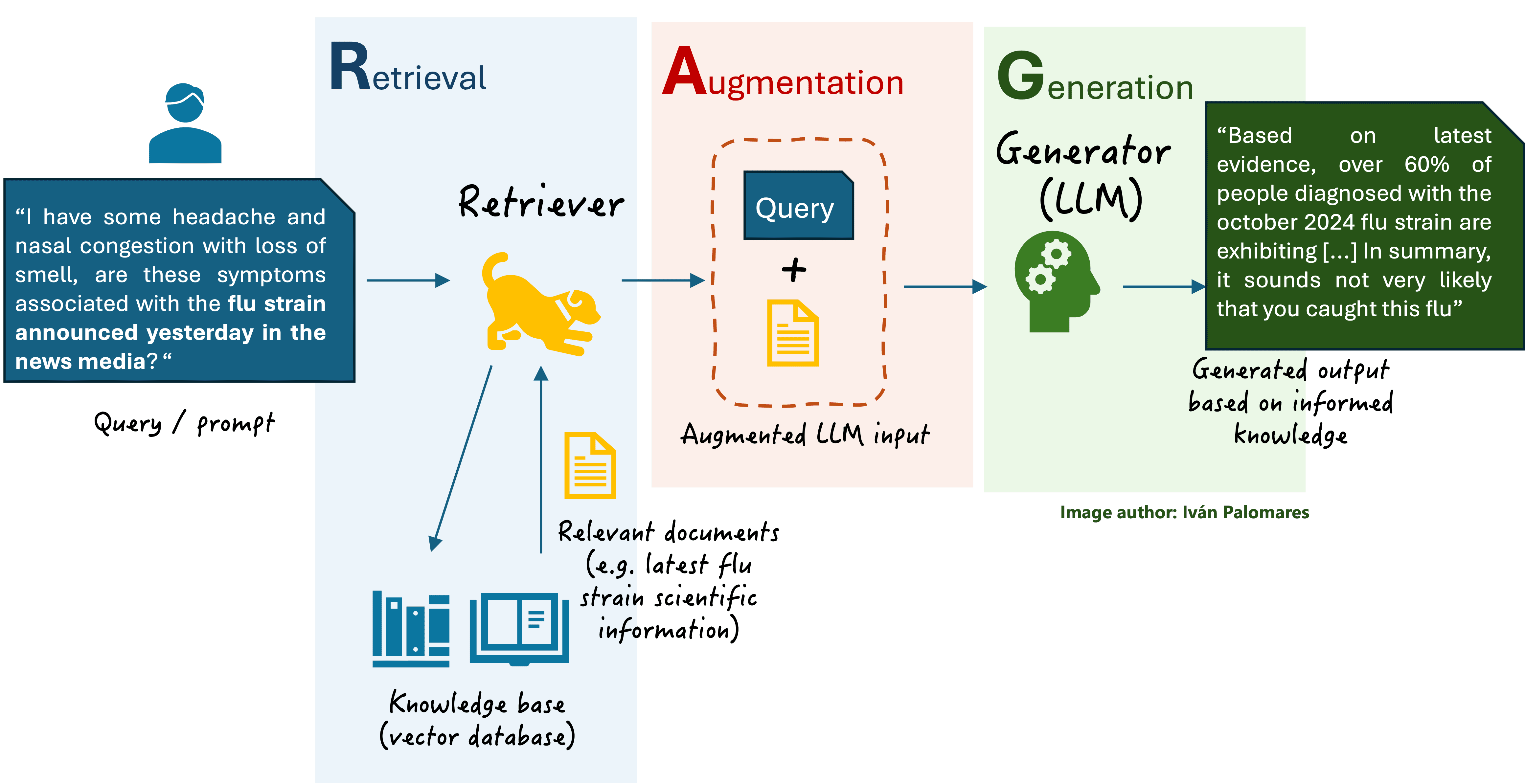
قبل از کاوش عمیق تر، ارزش آن را دارد که به طور خلاصه نمودار RAG را که در قسمت دوم این مجموعه بررسی کردیم، مرور کنیم.
طرح اصلی RAG
بازیابی فیوژن توضیح داده شد
رویکردهای بازیابی فیوژن شامل ادغام یا تجمیع جریان های اطلاعاتی متعدد در مرحله بازیابی یک سیستم RAG است. به یاد بیاورید که در مرحله بازیابی، بازیابی – یک موتور بازیابی اطلاعات – پرس و جوی کاربر اصلی را برای LLM می گیرد، آن را در یک نمایش برداری دیجیتالی رمزگذاری می کند و از آن برای جستجوی یک پایگاه دانش بزرگ برای اسنادی استفاده می کند که به شدت با پرس و جو مطابقت دارند. پس از آن، پرس و جو اصلی با افزودن اطلاعات متنی اضافی ناشی از اسناد بازیابی شده، افزوده می شود و در نهایت ورودی افزوده شده به LLM ارسال می شود که پاسخی را ایجاد می کند.
با اعمال طرح های ادغام در مرحله بازیابی، زمینه اضافه شده به پرس و جو اصلی می تواند منسجم تر و مرتبط تر شود و پاسخ نهایی تولید شده توسط LLM را بیشتر بهبود بخشد. بازیابی ادغام دانش را از چندین سند بازیابی شده (نتایج جستجو) می گیرد و آنها را در یک زمینه معنی دار و دقیق تر ترکیب می کند. با این حال، طرح اصلی RAG که قبلاً میدانیم میتواند چندین سند پایه دانش را نیز بازیابی کند، نه لزوماً فقط یک. پس تفاوت بین این دو رویکرد چیست؟
تفاوت اصلی بین بازیابی سنتی RAG و بازیابی ادغام در نحوه پردازش اسناد بازیابی شده متعدد و ادغام در پاسخ نهایی است. در RAG کلاسیک، محتویات اسناد بازیابی شده به سادگی به هم متصل می شوند یا حداکثر به صورت استخراجی خلاصه می شوند و سپس به عنوان زمینه اضافی به LLM برای تولید پاسخ وارد می شوند. هیچ تکنیک فیوژن پیشرفته ای اعمال نمی شود. در همین حال، در بازیابی ادغام، مکانیسم های تخصصی تری برای ترکیب اطلاعات مرتبط در اسناد متعدد استفاده می شود. این فرآیند ادغام می تواند در مرحله افزایش (مرحله بازیابی) یا حتی در مرحله تولید اتفاق بیفتد.
- ادغام در مرحله رشد شامل بکارگیری تکنیک هایی برای سازماندهی مجدد، فیلتر کردن یا ترکیب چندین سند قبل از ارسال به مولد می شود. دو نمونه هستند طبقه بندی مجددکه در آن اسناد قبل از وارد شدن به مدل با درخواست کاربر، امتیاز بندی و رتبه بندی می شوند. تجمعجایی که مرتبط ترین اطلاعات از هر سند در یک زمینه واحد ادغام می شود. تجمیع از طریق روش های کلاسیک بازیابی اطلاعات مانند TF-IDF (فرکانس مدت – فرکانس معکوس سند)، عملیات جاسازی و غیره اعمال می شود.
- ادغام در فاز تولید شامل LLM (مولد) می شود که هر سند بازیابی شده را به طور مستقل پردازش می کند – از جمله درخواست کاربر – و هنگام ایجاد پاسخ نهایی، اطلاعات حاصل از چندین کار پردازشی را ادغام می کند. به طور کلی، مرحله افزایش در RAG بخشی از مرحله تولید است. یک روش رایج در این دسته، Fusion-in-Decoder (FiD) است که به LLM اجازه می دهد تا هر سند بازیابی شده را جداگانه پردازش کند و سپس اطلاعات آنها را در حین ایجاد پاسخ نهایی ترکیب کند. رویکرد FiD به تفصیل در شرح داده شده است این مقاله.
طبقهبندی مجدد یکی از سادهترین و در عین حال مؤثرترین روشهای ترکیبی برای ترکیب معنادار اطلاعات از چندین منبع بازیابی شده است. بخش زیر به طور مختصر نحوه کار این کار را توضیح می دهد:
طبقه بندی مجدد چگونه کار می کند؟
در فرآیند رتبه بندی مجدد، مجموعه اولیه اسناد بازیابی شده توسط بازیابی مجدد سازماندهی می شود تا ارتباط با درخواست کاربر بهبود یابد، در نتیجه نیازهای کاربر را بهتر برآورده کرده و کیفیت کلی نتیجه را بهبود می بخشد. Retriever اسناد بازیابی شده را به یک جزء الگوریتمی به نام منتقل می کند سرباز سادهکه نتایج بازیابی شده را بر اساس معیارهایی مانند ترجیحات کاربر آموخته شده مجدد ارزیابی می کند و مرتب سازی اسناد را با هدف به حداکثر رساندن ارتباط نتایج ارائه شده به آن کاربر خاص اعمال می کند. مکانیسم هایی مانند میانگین وزنی یا سایر اشکال امتیاز دهی برای ترکیب و اولویت بندی اسناد در بالاترین رتبه ها استفاده می شود، به طوری که محتوای اسنادی که در نزدیکی بالاترین رتبه بندی شده اند به احتمال زیاد بخشی از متن نهایی ترکیب شده به عنوان محتوای اسناد طبقه بندی شده در موقعیت های پایین تر
نمودار زیر مکانیسم طبقه بندی مجدد را نشان می دهد:
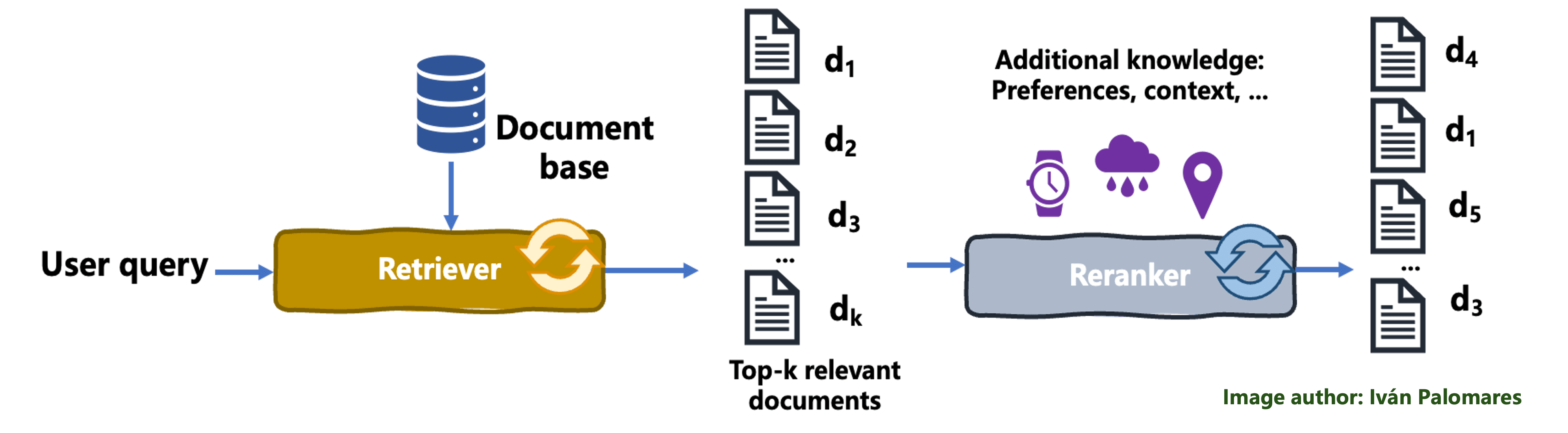
فرآیند طبقه بندی مجدد
بیایید یک مثال را برای درک بهتر طبقه بندی مجدد، در زمینه گردشگری در شرق آسیا توضیح دهیم. مسافری را تصور کنید که در حال جستجوی سیستم RAG برای “بهترین مقاصد برای دوستداران طبیعت در آسیا” است. یک سیستم بازیابی اولیه ممکن است فهرستی از اسناد شامل راهنمای کلی سفر، مقالاتی در مورد شهرهای محبوب آسیایی و توصیههایی برای پارکهای طبیعی را بازگرداند. با این حال، یک مدل رتبهبندی مجدد، احتمالاً با استفاده از اولویتهای خاص مسافر و دادههای متنی اضافی (مانند فعالیتهای ترجیحی، فعالیتهایی که قبلاً از آنها لذت میبردید، یا مقصدهای قبلی)، میتواند این اسناد را برای اولویتبندی محتوای مرتبط با این کاربر مجدداً مرتب کند. میتواند پارکهای ملی آرام، مسیرهای پیادهروی کمتر شناختهشده، و تورهای دوستدار محیطزیست را که ممکن است در بالای لیست پیشنهادات همه قرار نگیرند برجسته کند، و نتایجی را ارائه دهد که «درست به هدف» برای گردشگران طبیعتدوست مانند هدف ما ارائه میکند. کاربر.
به طور خلاصه، رتبهبندی مجدد چندین اسناد بازیابی شده را بر اساس معیارهای مربوط به کاربر اضافی مرتب میکند تا فرآیند استخراج محتوا را روی اسناد رتبه اول متمرکز کند، در نتیجه ارتباط پاسخهای تولید شده بعدی را بهبود میبخشد.
درباره ایوان پالومارس کاراسکوزا
ایوان پالومارس کاراسکوزا یک رهبر، نویسنده، سخنران و مشاور در AI، یادگیری ماشین، یادگیری عمیق و LLM است. او دیگران را در استفاده از هوش مصنوعی در دنیای واقعی آموزش می دهد و راهنمایی می کند.