
مدلهای زبان شاهد پیشرفتهای سریعی بودهاند و معماریهای مبتنی بر ترانسفورماتور در پردازش زبان طبیعی پیشرو هستند. با این حال، همانطور که مدلها مقیاس میشوند، چالشهای مدیریت زمینههای طولانی، کارایی حافظه و توان عملیاتی بیشتر شدهاند.
آزمایشگاه AI21 راه حل جدیدی با Jamba معرفی کرده است، یک مدل پیشرفته زبان بزرگ (LLM) که ترکیبی از نقاط قوت Transformer و معماری مامبا در یک چارچوب ترکیبی این مقاله به جزئیات جامبا می پردازد و معماری، عملکرد و کاربردهای بالقوه آن را بررسی می کند.
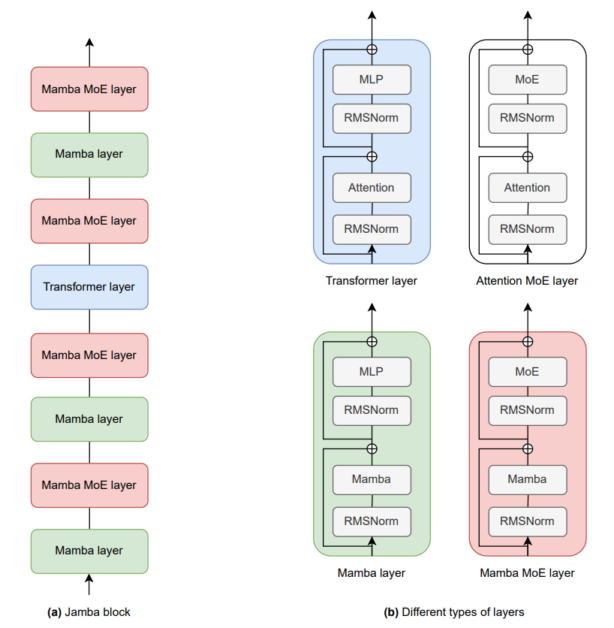
مروری بر جامبا
جامبا یک مدل زبان بزرگ ترکیبی است که توسط AI21 Labs توسعه یافته است و از ترکیب لایههای Transformer و لایههای Mamba استفاده میکند که با یک ترکیبی از کارشناسان (MOE) ماژول. این معماری به Jamba اجازه می دهد تا میزان استفاده از حافظه، توان عملیاتی و عملکرد را متعادل کند و آن را به ابزاری قدرتمند برای طیف گسترده ای از وظایف NLP تبدیل کند. این مدل به گونهای طراحی شده است که در یک واحد پردازش گرافیکی 80 گیگابایتی قرار بگیرد و توان پردازشی بالا و حافظه کوچکی را ارائه دهد و در عین حال عملکرد پیشرفتهای را در معیارهای مختلف حفظ کند.
معماری جامبا
معماری جامبا سنگ بنای قابلیت های آن است. این بر اساس یک طراحی ترکیبی جدید ساخته شده است که لایههای ترانسفورماتور را با لایههای Mamba در هم میپیوندد، و ماژولهای MoE را برای افزایش ظرفیت مدل بدون افزایش قابلتوجه نیازهای محاسباتی ترکیب میکند.
1. لایه های ترانسفورماتور
معماری Transformer به دلیل توانایی آن در مدیریت کارآمد پردازش موازی و گرفتن وابستگی های دوربرد در متن به استانداردی برای LLM های مدرن تبدیل شده است. با این حال، عملکرد آن اغلب با نیازهای حافظه و محاسبات بالا، به ویژه هنگام پردازش زمینه های طولانی، محدود می شود. جامبا با ادغام لایههای Mamba که در ادامه به بررسی آنها خواهیم پرداخت، این محدودیتها را برطرف میکند.
2. لایه های مامبا
مامبا یک مدل فضای حالت وضعیت اخیر (SSM) است که برای مدیریت روابط از راه دور در توالی کارآمدتر از RNN های سنتی یا حتی ترانسفورماتورها طراحی شده است. لایههای مامبا بهویژه در کاهش ردپای حافظه مرتبط با ذخیرهسازی حافظههای پنهان کلید-مقدار (KV) در Transformers مؤثر هستند. با در هم آمیختن لایههای Mamba با لایههای Transformer، Jamba مصرف کلی حافظه را کاهش میدهد و در عین حال عملکرد بالا را حفظ میکند، بهویژه در کارهایی که نیاز به مدیریت طولانی مدت دارند.
3. ترکیبی از کارشناسان (MOE) ماژول ها
این وزارت دفاع ماژول در جامبا یک رویکرد انعطاف پذیر برای مقیاس بندی ظرفیت مدل معرفی می کند. MoE به مدل اجازه می دهد تا تعداد پارامترهای موجود را بدون افزایش متناسب پارامترهای فعال در طول استنتاج افزایش دهد. در Jamba، MoE بر روی برخی از لایههای MLP اعمال میشود، با مکانیزم روتر، کارشناسان برتر را برای فعال کردن هر توکن انتخاب میکند. این فعالسازی انتخابی، جمبا را قادر میسازد تا در حین انجام وظایف پیچیده، کارایی بالایی داشته باشد.
تصویر زیر عملکرد یک هد القایی را در مدل هیبریدی Attention-Mamba نشان می دهد که یکی از ویژگی های کلیدی جامبا است. در این مثال، سر توجه مسئول پیشبینی برچسبهایی مانند «مثبت» یا «منفی» در پاسخ به وظایف تحلیل احساسات است. کلمات برجسته نشان میدهند که چگونه توجه مدل بهشدت بر روی نشانههای برچسب از چند نمونه عکس متمرکز شده است، به ویژه در لحظه حساس قبل از پیشبینی برچسب نهایی. این مکانیسم توجه نقش مهمی در توانایی مدل برای انجام یادگیری درون زمینه ای ایفا می کند، جایی که مدل باید برچسب مناسب را بر اساس زمینه داده شده و نمونه های چند تصویری استنباط کند.
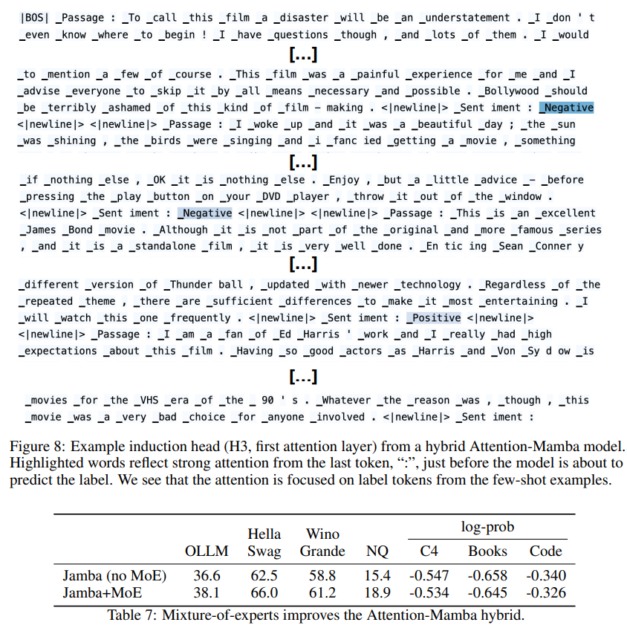
بهبود عملکرد ارائه شده با ادغام Mixture-of-Experts (MoE) با معماری ترکیبی Attention-Mamba در جدول مشخص شده است. با استفاده از MoE، جامبا ظرفیت خود را بدون افزایش متناسب هزینه های محاسباتی افزایش می دهد. این امر به ویژه در افزایش قابل توجه عملکرد در معیارهای مختلف مانند HellaSwag، WinoGrande و Natural Questions (NQ) مشهود است. مدل با MoE نه تنها دقت بالاتری را به دست میآورد (مثلاً 66.0% در WinoGrande در مقایسه با 62.5% بدون MoE) بلکه همچنین احتمالات گزارش بهبود یافته را در دامنههای مختلف نشان میدهد (مثلاً 0.534- در C4).
ویژگی های کلیدی معماری
- ترکیب لایه: معماری جامبا از بلوک هایی تشکیل شده است که ترکیب می شوند مامبا و لایه های ترانسفورماتور در یک نسبت خاص (مثلاً 1:7، یعنی یک لایه ترانسفورماتور برای هر هفت لایه مامبا). این نسبت برای عملکرد و کارایی بهینه تنظیم شده است.
- ادغام وزارت دفاع: لایههای MoE هر چند لایه اعمال میشوند و 16 کارشناس در دسترس هستند و 2 کارشناس برتر در هر توکن فعال میشوند. این پیکربندی به Jamba اجازه میدهد تا به طور موثر مقیاسبندی شود و در عین حال، مبادلات بین استفاده از حافظه و کارایی محاسباتی را مدیریت کند.
- عادی سازی و ثبات: برای اطمینان از پایداری در طول تمرین، Jamba از RMSNorm در لایههای Mamba استفاده میکند، که به کاهش مشکلاتی مانند سنبلههای فعالسازی بزرگ که میتواند در مقیاس رخ دهد، کمک میکند.
عملکرد و محک جمبا
جامبا به شدت در برابر طیف گسترده ای از معیارها آزمایش شده است و عملکرد رقابتی را در سراسر صفحه نشان می دهد. بخشهای زیر برخی از معیارهای کلیدی را که جامبا در آنها برتری داشته است، نشان میدهد و نقاط قوت آن را هم در وظایف عمومی NLP و هم در سناریوهای با زمینه طولانی نشان میدهد.
1. معیارهای رایج NLP
جامبا بر اساس چندین معیار آکادمیک مورد ارزیابی قرار گرفته است، از جمله:
- هلاسواگ (10 تیر): یک کار استدلال عقل سلیم که در آن جامبا نمره عملکرد 87.1٪ را به دست آورد که از بسیاری از مدل های رقیب پیشی گرفت.
- WinoGrande (5-shot): یکی دیگر از وظایف استدلالی که در آن جامبا امتیاز 82.5٪ را به دست آورد و دوباره توانایی خود را در مدیریت استدلال پیچیده زبانی نشان داد.
- ARC-Challenge (25 تیر): جامبا عملکرد قوی با امتیاز 64.4٪ نشان داد که نشان دهنده توانایی آن در مدیریت سوالات چالش برانگیز چند گزینه ای است.
در معیارهای کلی مانند MMLU (5-shot)، Jamba به امتیاز 67.4% دست یافت که نشان دهنده استحکام آن در انجام وظایف مختلف است.
2. ارزیابی های طولانی مدت
یکی از ویژگی های برجسته جامبا توانایی آن در مدیریت زمینه های بسیار طولانی است. این مدل از طول زمینه تا 256 هزار توکن پشتیبانی میکند که طولانیترین در میان مدلهای در دسترس عموم است. این قابلیت با استفاده از بنچمارک Needle-in-a-Haystack آزمایش شد، جایی که Jamba دقت بازیابی استثنایی را در طول های مختلف زمینه، از جمله تا 256 هزار توکن نشان داد.
3. توان عملیاتی و کارایی
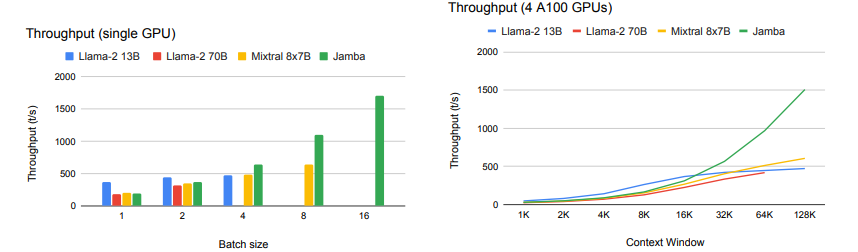
معماری ترکیبی جامبا به طور قابل توجهی توان عملیاتی را بهبود می بخشد، به ویژه با دنباله های طولانی.
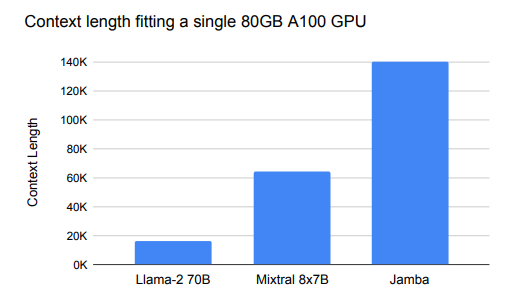
در آزمایشهای مقایسه توان عملیاتی (توکنها در هر ثانیه) در مدلهای مختلف، جامبا به طور مداوم از همتایان خود، بهویژه در سناریوهایی که شامل اندازههای دستهای بزرگ و زمینههای طولانی است، بهتر عمل میکرد. به عنوان مثال، جامبا با 128 هزار توکن، 3 برابر بیشتر از Mixtral، یک مدل قابل مقایسه، دست یافت.
استفاده از Jamba: Python
برای توسعه دهندگان و محققانی که مشتاق آزمایش جامبا هستند، آزمایشگاه AI21 این مدل را بر روی پلتفرم هایی مانند Hugging Face ارائه کرده است و آن را برای طیف گسترده ای از برنامه ها در دسترس قرار داده است. قطعه کد زیر نحوه بارگیری و تولید متن با استفاده از Jamba را نشان می دهد:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1")
tokenizer = AutoTokenizer.from_pretrained("ai21labs/Jamba-v0.1")
input_ids = tokenizer("In the recent Super Bowl LVIII,", return_tensors='pt').to(model.device)["input_ids"]
outputs = model.generate(input_ids, max_new_tokens=216)
print(tokenizer.batch_decode(outputs))
این اسکریپت ساده مدل جامبا و توکنایزر را بارگیری می کند، متنی را بر اساس یک دستور ورودی داده شده تولید می کند و خروجی تولید شده را چاپ می کند.
تنظیم دقیق جامبا
جامبا به عنوان یک مدل پایه طراحی شده است، به این معنی که می توان آن را برای وظایف یا برنامه های خاص تنظیم کرد. تنظیم دقیق به کاربران این امکان را می دهد که مدل را با دامنه های خاص تطبیق دهند و عملکرد را در کارهای تخصصی بهبود بخشند. مثال زیر نحوه تنظیم دقیق Jamba با استفاده از کتابخانه PEFT را نشان می دهد:
import torch
from datasets import load_dataset
from trl import SFTTrainer, SFTConfig
from peft import LoraConfig
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments
tokenizer = AutoTokenizer.from_pretrained("ai21labs/Jamba-v0.1")
model = AutoModelForCausalLM.from_pretrained(
"ai21labs/Jamba-v0.1", device_map='auto', torch_dtype=torch.bfloat16)
lora_config = LoraConfig(r=8,
target_modules=[
"embed_tokens","x_proj", "in_proj", "out_proj", # mamba
"gate_proj", "up_proj", "down_proj", # mlp
"q_proj", "k_proj", "v_proj"
# attention],
task_type="CAUSAL_LM", bias="none")
dataset = load_dataset("Abirate/english_quotes", split="train")
training_args = SFTConfig(output_dir="./results",
num_train_epochs=2,
per_device_train_batch_size=4,
logging_dir='./logs',
logging_steps=10, learning_rate=1e-5, dataset_text_field="quote")
trainer = SFTTrainer(model=model, tokenizer=tokenizer, args=training_args,
peft_config=lora_config, train_dataset=dataset,
)
trainer.train()
این قطعه کد، Jamba را روی مجموعه دادهای از نقل قولهای انگلیسی تنظیم میکند و پارامترهای مدل را برای تناسب بهتر با وظیفه خاص تولید متن در یک دامنه تخصصی تنظیم میکند.
استقرار و ادغام
آزمایشگاههای AI21 خانواده جامبا را از طریق پلتفرمها و گزینههای استقرار مختلف در دسترس قرار داده است:
- پلتفرم های ابری:
- در ارائه دهندگان ابری بزرگ از جمله Google Cloud Vertex AI، Microsoft Azure و NVIDIA NIM.
- به زودی به Amazon Bedrock، Databricks Marketplace و Snowflake Cortex عرضه می شود.
- چارچوب های توسعه هوش مصنوعی:
- ادغام با چارچوب های محبوب مانند LangChain و LlamaIndex (آینده).
- AI21 Studio:
- دسترسی مستقیم از طریق پلتفرم توسعه خود AI21.
- صورت در آغوش گرفته:
- مدل های موجود برای دانلود و آزمایش.
- استقرار در محل:
- گزینه هایی برای استقرار خصوصی و در محل برای سازمان هایی با نیازهای امنیتی خاص یا انطباق.
- راه حل های سفارشی:
- AI21 خدمات سفارشی سازی و تنظیم دقیق مدل را برای مشتریان سازمانی ارائه می دهد.
ویژگی های برنامه نویس دوستانه
مدل های جامبا دارای چندین قابلیت داخلی هستند که آنها را به ویژه برای توسعه دهندگان جذاب می کند:
- فراخوانی تابع: ابزارهای خارجی و APIها را به راحتی در جریان کاری هوش مصنوعی خود ادغام کنید.
- خروجی JSON ساختاریافته: ساختارهای داده تمیز و قابل تجزیه را مستقیماً از ورودی های زبان طبیعی ایجاد کنید.
- سند هضم شی: پردازش و درک ساختارهای پیچیده سند.
- بهینه سازی RAG: ویژگی های داخلی برای بهبود خطوط لوله تولید افزوده بازیابی.
این ویژگی ها، همراه با پنجره زمینه طولانی مدل و پردازش کارآمد، جامبا را به ابزاری همه کاره برای طیف گسترده ای از سناریوهای توسعه تبدیل می کند.
ملاحظات اخلاقی و هوش مصنوعی مسئول
در حالی که قابلیت های جامبا چشمگیر است، بسیار مهم است که به استفاده از آن با ذهنیت هوش مصنوعی مسئولانه نزدیک شوید. آزمایشگاه AI21 بر چند نکته مهم تاکید دارد:
- مدل پایه طبیعت: مدل های Jamba 1.5 مدل های پایه از پیش آموزش دیده بدون تراز یا تنظیم دستورالعمل خاص هستند.
- عدم وجود محافظ های داخلی: مدل ها مکانیسم های تعدیل ذاتی ندارند.
- استقرار دقیق: پیش از استفاده از جامبا در محیط های تولیدی یا با استفاده کنندگان نهایی، سازگاری و تدابیر اضافی باید اعمال شود.
- حریم خصوصی داده ها: هنگام استفاده از استقرارهای مبتنی بر ابر، به مدیریت داده ها و الزامات انطباق توجه داشته باشید.
- آگاهی تعصب: مانند همه مدل های زبان بزرگ، Jamba ممکن است سوگیری های موجود در داده های آموزشی خود را منعکس کند. کاربران باید از این موضوع آگاه باشند و اقدامات کاهشی مناسب را اعمال کنند.
با در نظر گرفتن این عوامل، توسعهدهندگان و سازمانها میتوانند از قابلیتهای جامبا به طور مسئولانه و اخلاقی استفاده کنند.
فصل جدیدی در توسعه هوش مصنوعی؟
معرفی خانواده جمبا توسط AI21 Labs نقطه عطف مهمی در تکامل مدل های زبان بزرگ است. جامبا با ترکیب نقاط قوت ترانسفورماتورها و مدلهای فضای حالت، یکپارچهسازی ترکیبی از تکنیکهای متخصص، و افزایش مرزهای طول زمینه و سرعت پردازش، فرصتهای جدیدی را برای کاربردهای هوش مصنوعی در سراسر صنایع باز میکند.
همانطور که جامعه هوش مصنوعی به کاوش و توسعه این معماری نوآورانه ادامه میدهد، میتوان انتظار داشت که شاهد پیشرفتهای بیشتری در کارایی مدل، درک متن طولانی و استقرار عملی هوش مصنوعی باشیم. خانواده جامبا نه تنها مجموعه جدیدی از مدلها را نشان میدهد، بلکه یک تغییر بالقوه در نحوه رویکرد ما به طراحی و اجرای سیستمهای هوش مصنوعی در مقیاس بزرگ است.

