تولید زبان طبیعی به صورت معکوس: آموزش ماشین تحریر برای نوشتن مانند انسان
تصویر ویرایشگر | نیمه راه
تولید زبان طبیعی (NLG) یک منطقه هیجان انگیز از هوش مصنوعی (AI)یا دقیق تر به پردازش زبان طبیعی (NLP)با هدف توانمند ساختن ماشینها برای تولید متن انسانمانند که ارتباط انسان و ماشین را برای حل مسئله هدایت میکند. این مقاله به بررسی چیستی NLG، چگونه کار میکند، و چگونه این زمینه طی چند سال گذشته تکامل یافته است و در عین حال اهمیت آن را در چندین کاربرد برجسته میکند.
درک تولید زبان طبیعی
هوش مصنوعی و سیستم های کامپیوتری به طور کلی بر اساس زبان انسان عمل نمی کنند، بلکه بر اساس نمایش دیجیتالی داده ها عمل می کنند. بنابراین، NLG شامل تبدیل داده های در حال پردازش به متن قابل خواندن توسط انسان است. موارد استفاده رایج برای NLG شامل نوشتن گزارش خودکار، رباتهای گفتگو، پاسخگویی به سؤال و ایجاد محتوای شخصیشده است.
برای درک بهتر نحوه عملکرد NLG، درک آن نیز ضروری است ارتباط با درک زبان طبیعی (NLU): NLG بر تولید زبان تمرکز دارد، در حالی که NLU بر تفسیر و درک آن تمرکز دارد. بنابراین، فرآیند تبدیل متضاد با آنچه در NLG اتفاق میافتد در NLU رخ میدهد: ورودیهای زبان انسانی مانند متن باید در نمایشهای دیجیتالی – اغلب برداری – متنی رمزگذاری شوند که الگوریتمها و مدلها میتوانند با یافتن معنای پیچیده آن را تحلیل، تفسیر و معنا کنند. . الگوهای زبان در متن
در هسته خود، NLG را می توان به عنوان یک دستور غذا فهمید. درست همانطور که یک سرآشپز مواد را به ترتیب خاصی برای ایجاد یک غذا جمع آوری می کند، سیستم های NLG عناصر زبان را بر اساس داده های ورودی مانند اطلاعات فوری و متنی جمع آوری می کنند.
درک این نکته مهم است که رویکردهای اخیر NLG، مانند معماری ترانسفورماتور که بعداً توضیح داده شد، اطلاعات موجود در ورودی ها را با ترکیب مراحل NLU در مراحل اولیه NLG ترکیب می کند. ایجاد یک پاسخ معمولاً مستلزم درک یک درخواست ورودی یا درخواستی است که توسط کاربر ایجاد شده است. هنگامی که این فرآیند درک اعمال می شود و قطعات زبانی پازل به شیوه ای معنی دار کنار هم قرار می گیرند، یک سیستم NLG یک پاسخ خروجی کلمه به کلمه تولید می کند. این بدان معنی است که زبان خروجی به طور کامل یکباره تولید نمی شود، بلکه کلمه به کلمه تولید می شود. به عبارت دیگر، مشکل بزرگتر تولید زبان به دنبالهای از مسائل سادهتر، یعنی مشکل پیشبینی کلمه بعدی، که به صورت تکراری و متوالی به آن نزدیک میشود، شکسته میشود.
THE مشکل پیش بینی کلمه بعدی در سطح پایین معماری به عنوان فرمول بندی شده است وظیفه طبقه بندی. همانطور که یک مدل طبقه بندی یادگیری ماشین معمولی می تواند برای طبقه بندی تصاویر حیوانات به عنوان پول نقد یا مشتریان بانک به عنوان واجد شرایط یا ناشایست برای وام آموزش داده شود، مدل NLG در مرحله آخر خود یک لایه طبقه بندی را گنجانده است که احتمال هر کلمه را تخمین می زند. در یک واژگان یا زبان، کلمه بعدی که سیستم باید به عنوان بخشی از پیام ایجاد کند: بنابراین، کلمه ای که بیشترین احتمال را دارد به عنوان کلمه بعدی واقعی برگردانده می شود.
معماری ترانسفورماتور رمزگذار-رمزگشا پایه و اساس مدلهای زبان بزرگ مدرن (LLM) را تشکیل میدهد که در وظایف NLG برتری دارند. در مرحله نهایی پشته رمزگشا (گوشه سمت راست بالای نمودار زیر) یک لایه طبقه بندی است که برای یادگیری پیش بینی کلمه بعدی که باید تولید شود آموزش داده شده است.
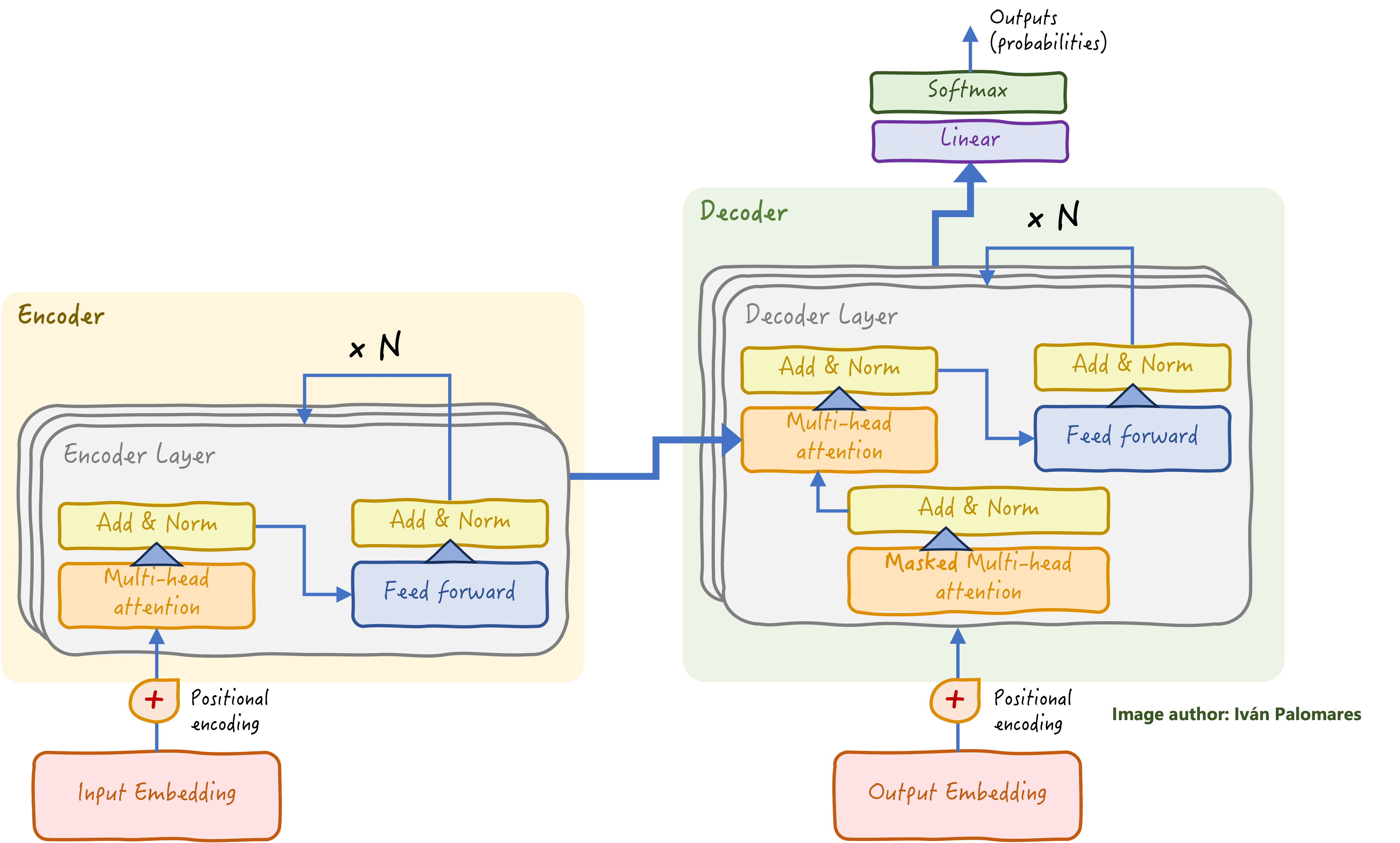
معماری ترانسفورماتور کلاسیک: پشته رمزگذار بر درک زبان ورودی متمرکز است، در حالی که پشته رمزگشا از اطلاعات آموخته شده برای ایجاد یک پاسخ کلمه به کلمه استفاده می کند.
تکامل تکنیک ها و معماری های NLG
NLG به طور قابل توجهی از سیستمهای مبتنی بر قوانین محدود و نسبتاً ایستا در روزهای اولیه NLP به مدلهای پیچیدهای مانند Transformers و LLMs امروزی تکامل یافته است که قادر به انجام طیف قابل توجهی از وظایف زبانی، از جمله درک نه تنها زبان انسانی، بلکه همچنین تولید کد هستند. معرفی نسبتاً اخیر نسل افزوده بازیابی (RAG) قابلیتهای NLG را افزایش داده است و با ادغام دانش خارجی به عنوان ورودی متنی اضافی به فرآیند تولید، برخی از محدودیتهای LLM مانند توهمات و منسوخ شدن دادهها را برطرف میکند. RAG به فعال کردن پاسخهای مرتبطتر و متنیتر که به زبان انسانی بیان میشوند، کمک کرد، و اطلاعات مرتبط را در زمان واقعی بازیابی کرد تا درخواستهای ورودی کاربر را غنیتر کند.
روندها، چالش ها و جهت گیری های آینده
آینده NLG روشن به نظر می رسد، اگرچه بدون چالش نیست:
- از صحت متن تولید شده اطمینان حاصل کنید: همانطور که مدل ها در پیچیدگی و پیچیدگی افزایش می یابند، اطمینان از اینکه آنها محتوای واقعی و مناسب با زمینه تولید می کنند، اولویت اصلی توسعه دهندگان هوش مصنوعی است.
- ملاحظات اخلاقی: پرداختن به مسائلی مانند سوگیری در متن تولید شده و احتمال استفاده نادرست یا استفاده غیرقانونی که نیازمند چارچوب های قوی تر برای استقرار مسئولانه هوش مصنوعی است، ضروری است.
- هزینه آموزش و ساخت مدل ها: منابع محاسباتی قابل توجه مورد نیاز برای آموزش مدل های پیشرفته NLG، مانند مدل های مبتنی بر ترانسفورماتور، می تواند مانعی برای بسیاری از سازمان ها باشد و دسترسی آنها را محدود کند. ارائه دهندگان ابر و شرکت های بزرگ هوش مصنوعی به تدریج راه حل هایی را برای از بین بردن این بار به بازار معرفی می کنند.
همانطور که فناوریهای هوش مصنوعی همچنان در حال توسعه هستند، میتوانیم انتظار داشته باشیم NLGهای پیشرفتهتر و بصریتری داشته باشیم که همچنان خطوط بین ارتباطات انسان و ماشین محور را محو کنند.
درباره ایوان پالومارس کاراسکوزا
ایوان پالومارس کاراسکوزا یک رهبر، نویسنده، سخنران و مشاور در AI، یادگیری ماشین، یادگیری عمیق و LLM است. او دیگران را در استفاده از هوش مصنوعی در دنیای واقعی آموزش می دهد و راهنمایی می کند.