
تسلط بر هنر تنظیم فراپارامتر: نکات، ترفندها و ابزارها
تصویر توسط آنتونی در Pexels
مدلهای یادگیری ماشینی (ML) حاوی پارامترهای قابل تنظیم زیادی به نام هایپرپارامتر هستند که نحوه یادگیری آنها از دادهها را کنترل میکنند. برخلاف پارامترهای مدل که به طور خودکار در طول آموزش یاد میشوند، ابرپارامترها باید به دقت توسط توسعهدهندگان پیکربندی شوند تا عملکرد مدل را بهینه کنند. این پارامترها از نرخ یادگیری و معماری شبکه در شبکههای عصبی تا عمق درخت در جنگلهای تصمیمگیری را شامل میشود که اساساً چگونگی پردازش اطلاعات را مدلها تعیین میکند.
این مقاله روشهای ضروری و شیوههای اثباتشده برای تنظیم این پیکربندیهای حیاتی برای دستیابی به عملکرد بهینه مدل را بررسی میکند.
هایپرپارامترها چیست؟
در ML، هایپرپارامترها مانند دستگیرهها و چرخدندههای یک سیستم رادیویی یا هر ماشین دیگری هستند: این چرخدندهها را میتوان به روشهای مختلفی تنظیم کرد و بر عملکرد دستگاه تأثیر گذاشت. به طور مشابه، فراپارامترهای یک مدل ML تعیین می کند که مدل چگونه داده ها را در طول آموزش و استنتاج یاد می گیرد و پردازش می کند و در نتیجه بر عملکرد، دقت و سرعت آن در اجرای بهینه کار مورد نظر تأثیر می گذارد.
توجه به این نکته ضروری است که همانطور که در بالا ذکر شد، پارامترها و هایپرپارامترها یکسان نیستند. پارامترهای مدل ML – وزن نیز نامیده می شود – توسط مدل در طول تمرین یاد گرفته و تنظیم می شود. این مورد برای ضرایب در مدل های رگرسیون و وزن اتصال در شبکه های عصبی است. از سوی دیگر، هایپرپارامترها توسط مدل یاد نمیگیرند، اما قبل از آموزش برای کنترل فرآیند یادگیری، توسط توسعهدهنده ML تعریف میشوند. برای مثال، چندین درخت تصمیم که با تنظیمات فراپارامترهای مختلف برای حداکثر عمق، معیار تقسیم و غیره آموزش داده شدهاند، میتوانند مدلهایی تولید کنند که ظاهر و رفتار متفاوتی داشته باشند، حتی زمانی که همه آنها بر روی مجموعههای دادههای یکسان آموزش دیده باشند.

تفاوت بین پارامترها و فراپارامترها در مدل های ML
تصویر توسط نویسنده
تنظیم فراپارامتر: نکات، ترفندها و ابزارها
به طور کلی، هرچه یک مدل ML پیچیدهتر باشد، دامنه فراپارامترهایی که برای بهینهسازی رفتار آن باید تنظیم شوند، گستردهتر است. جای تعجب نیست که شبکههای عصبی عمیق از جمله انواع مدلهایی هستند که متفاوتترین فراپارامترها را در نظر میگیرند – از نرخ یادگیری گرفته تا تعداد و نوع لایهها تا اندازه دستهای، به غیر از فعالسازی d، که به شدت بر غیرخطی بودن و توانایی یادگیری پیچیده تأثیر میگذارد. عناصر مفید مدل ها از داده ها
بنابراین این سوال پیش می آید: چگونه میتوانیم بهترین تنظیمات را برای فراپارامترهای مدل خود پیدا کنیم، در حالی که مانند جستجوی سوزن در انبار کاه است؟
یافتن بهترین «نسخه» مدل ما مستلزم ارزیابی عملکرد آن بر اساس معیارها است، بنابراین این امر به عنوان بخشی از فرآیند دورهای آموزش، ارزیابی و اعتبارسنجی مدل اتفاق میافتد، همانطور که در زیر نشان داده شده است.
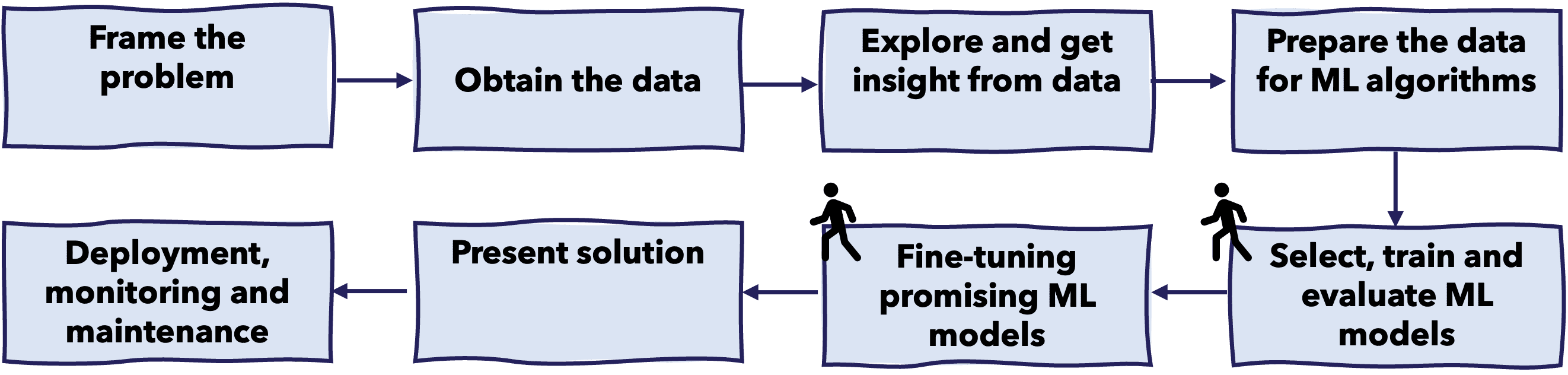
در چرخه حیات سیستمهای ML، تنظیم فراپارامتر در طول آموزش و ارزیابی مدل صورت میگیرد.
تصویر توسط نویسنده
البته، زمانی که چندین ابرپارامتر برای بازی وجود دارد، و هر کدام میتوانند طیفی از مقادیر ممکن را بگیرند، تعداد ترکیبهای ممکن – موقعیتهایی که میتوان همه دکمههای سیستم رادیویی را در آنها تنظیم کرد – میتواند به سرعت بسیار زیاد شود. تشکیل همه ترکیبات ممکن از نظر هزینه و زمان سرمایه گذاری غیر قابل مقرون به صرفه باشد، به همین دلیل به راه حل های بهتری نیاز است. به عبارت فنی تر، فضای جستجو بسیار زیاد می شود. یک ابزار متداول برای انجام کارآمدتر این کار دشوار بهینه سازی، استفاده از آن است فرآیند تحقیق. دو تکنیک رایج جستجو برای تنظیم هایپرپارامتر عبارتند از:
- جستجوی شبکه ای: این روش به طور کامل در یک زیرمجموعه مشخص شده دستی از فضای فراپارامتر جستجو می کند و تمام ترکیبات ممکن را در آن زیر مجموعه آزمایش می کند. این امر بار امتحان کردن مناطق مختلف فضای جستجو را کاهش میدهد، اما همچنان میتواند از نظر محاسباتی گران شود هنگام برخورد با پارامترها و مقادیر زیادی در هر پارامتر. به عنوان مثال، بیایید یک مدل شبکه عصبی را فرض کنیم که بر اساس آن سعی می کنیم دو ابرپارامتر را تنظیم کنیم: میزان یادگیریبا ارزش ها، 0.01، 0.1 و 1; و اندازه دستهبا ارزش ها 16، 32، 64 و 128. جستجوی شبکه ای ارزیابی می کند 3 × 4 = 12 در مجموع، 12 نسخه از مدل را آموزش داده و آنها را برای شناسایی بهترین عملکرد ارزیابی می کند.
- جستجوی تصادفی: جستجوی تصادفی با نمونه برداری از ترکیبات تصادفی فراپارامترها فرآیند را ساده می کند. سریعتر از جستجوی شبکهای است و اغلب راهحلهای خوبی با هزینه محاسباتی پایینتر پیدا میکند، به خصوص زمانی که برخی از فراپارامترها تأثیر بیشتری بر عملکرد مدل نسبت به بقیه دارند.
علاوه بر این فنون تحقیق، سایر نکات و ترفندها مواردی که برای بهبود بیشتر فرآیند تنظیم هایپرپارامتر باید در نظر گرفته شوند عبارتند از:
- اعتبارسنجی متقابل برای ارزیابی مدل قوی تر: اعتبارسنجی متقابل یک رویکرد ارزیابی رایج برای اطمینان از تعمیم بیشتر مدل شما به دادههای آینده یا غیرقابل مشاهده است، در نتیجه معیار عملکرد قابل اعتمادتری ارائه میکند. ترکیب روشهای جستجو و اعتبارسنجی متقابل یک رویکرد بسیار رایج است، اگرچه شامل چرخههای آموزشی و زمان بیشتری است که در فرآیند کلی سرمایهگذاری میشود.
- به تدریج جستجو را اصلاح کنید: با یک محدوده بزرگ یا گسترده از مقادیر برای هر هایپرپارامتر شروع کنید، سپس آن را بر اساس نتایج اولیه برای تجزیه و تحلیل بیشتر مناطق اطراف امیدوارکننده ترین ترکیبات، اصلاح کنید.
- از خاموش شدن زودهنگام استفاده کنید: در فرآیندهای آموزشی بسیار وقت گیر مانند فرآیندهای شبکه های عصبی عمیق، توقف زودهنگام اجازه می دهد تا زمانی که عملکرد به سختی بهبود می یابد، روند متوقف شود. این یک راه حل موثر در برابر مشکلات بیش از حد برازش است. آستانه توقف اولیه را می توان به عنوان نوع خاصی از فراپارامتر در نظر گرفت که همچنین می تواند تنظیم شود.
- دانش دامنه برای نجات: از دانش دامنه برای تعریف محدودیتها یا زیرمجموعههای واقعی برای فراپارامترهای خود استفاده کنید، و شما را به معقولترین محدودهها راهنمایی میکند تا در مراحل اولیه امتحان کنید و فرآیند جستجو را چابکتر میکند.
- راه حل های خودکار: رویکردهای پیشرفتهای مانند بهینهسازی بیزی برای بهینهسازی هوشمندانه فرآیند تنظیم با متعادل کردن اکتشاف و بهرهبرداری، مشابه برخی از اصول یادگیری تقویتی مانند الگوریتمهای راهزن وجود دارد.
نمونه هایی از هایپرپارامترها
بیایید به چند پارامتر کلیدی Random Forest با مثال ها و توضیحات عملی نگاهی بیندازیم:
⚙️ n_estimators: [100, 500, 1000]
- چه: تعداد درختان در جنگل
- مثال: با 10000 نمونه، شروع از 500 درخت اغلب به خوبی جواب می دهد.
- چرا: درختان بیشتر = تعمیم بهتر اما بازدهی کاهشی. برای پیدا کردن نقطه شیرین، خطای OOB را کنترل کنید
⚙️ max_depth: [10, 20, 30, None]
- چه: حداکثر عمق هر درخت
- مثال: برای داده های جدولی با 20 ویژگی، با شروع کنید
max_depth=20 - چرا: درختان عمیقتر الگوهای پیچیدهتری را میگیرند، اما خطر بیش از حد برازش را دارند.
Noneبگذارید درختان رشد کنند تا زمانی که برگها پاک شوند
⚙️ min_samples_split: [2, 5, 10]
- چه: حداقل نمونه های مورد نیاز برای تقسیم گره
- مثال: با داده های نویز،
min_samples_split=10می تواند به کاهش بیش از حد مناسب کمک کند - چرا: مقادیر بالاتر = تقسیم بندی محافظه کارانه تر، تعمیم بهتر در داده های پر سر و صدا
⚙️ min_samples_leaf: [1, 2, 4]
- چه: حداقل نمونه های مورد نیاز در گره های برگ
- مثال: برای یک طبقه بندی نامتعادل،
min_samples_leaf=4پیش بینی های معنی دار برگ را تضمین می کند - چرا: مقادیر بالاتر از گره های برگ بسیار کوچک که می توانند نویز را نشان دهند، جلوگیری می کند.
⚙️ bootstrap: [True, False]
- چه: آیا هنگام ساخت درخت از بوت استرپینگ استفاده شود یا خیر
- مثال: نادرست برای مجموعه داده های کوچک (چرا:
Trueامکان تخمین خطاهای خارج از کیسه را فراهم می کند اما تنها از حدود 63 درصد نمونه ها در هر درخت استفاده می کند.
نتیجه گیری
با اجرای استراتژی های بهینه سازی سیستماتیک فراپارامتر، توسعه دهندگان می توانند زمان توسعه مدل را به میزان قابل توجهی کاهش دهند و در عین حال عملکرد را بهبود بخشند. ترکیبی از تکنیکهای جستجوی خودکار و تخصص دامنه به تیمها این امکان را میدهد تا به طور مؤثر در فضاهای پارامترهای بزرگ پیمایش کنند و پیکربندیهای بهینه را شناسایی کنند. همانطور که سیستمهای ML پیچیدهتر و پیچیدهتر میشوند، تسلط بر این رویکردهای تنظیم برای ایجاد مدلهای قوی و کارآمد که تأثیر واقعی دارند، مهم نیست که کار چقدر پیچیده باشد، ارزش بیشتری پیدا میکند.