
یک مقاله تحقیقاتی جدید از کانادا چارچوبی را پیشنهاد کرده است که به طور عمدی فشرده سازی JPEG را در طرح آموزشی یک شبکه عصبی معرفی می کند و می تواند نتایج بهتر و مقاومت بهتر در برابر حملات متخاصم را به دست آورد.
این یک ایده نسبتاً رادیکال است، زیرا عقل کلی فعلی این است که مصنوعات JPEG، که برای مشاهده انسان بهینه شده اند، و نه برای یادگیری ماشین، عموماً تأثیر مخربی بر شبکه های عصبی آموزش داده شده بر روی داده های JPEG دارند.

نمونه ای از تفاوت در وضوح بین تصاویر JPEG فشرده شده در مقادیر مختلف از دست دادن (از دست دادن بیشتر اجازه می دهد اندازه فایل کوچکتر، به بهای ترسیم و باند در سراسر گرادیان رنگ، در میان انواع دیگر مصنوعات). منبع: https://forums.jetphotos.com/forum/aviation-photography-videography-forums/digital-photo-processing-forum/1131923-how-to-fix-jpg-compression-artefacts?p=1131937#post1131937
گزارش سال 2022 از دانشگاه مریلند و هوش مصنوعی فیسبوک ادعا کرد فشردهسازی JPEG در آموزش شبکههای عصبی، علیرغم کار قبلی که شبکه های عصبی ادعا شده نسبت به مصنوعات فشرده سازی تصویر انعطاف پذیر هستند.
یک سال قبل از این، رشته فکری جدیدی در ادبیات ظاهر شد: فشردهسازی JPEG میتواند در واقع اهرم شوند برای نتایج بهتر در آموزش مدل.
با این حال، اگرچه نویسندگان آن مقاله توانستند نتایج بهبود یافتهای را در آموزش تصاویر JPEG با سطوح کیفی متفاوت به دست آورند، مدل پیشنهادی آنها آنقدر پیچیده و سنگین بود که عملی نشد. علاوه بر این، استفاده سیستم از تنظیمات بهینه سازی پیش فرض JPEG (کوانتیزاسیون) مانعی برای اثربخشی تمرین به اثبات رساند.
پروژه بعدی (2023 فشرده سازی سازگار با JPEG برای DNN Vision) سیستمی را آزمایش کرد که نتایج کمی بهتر از تصاویر آموزشی فشرده شده با JPEG با استفاده از یک منجمد شده مدل شبکه عصبی عمیق (DNN) با این حال، انجماد بخشهایی از یک مدل در طول آموزش باعث کاهش تطبیقپذیری مدل و همچنین انعطافپذیری گستردهتر آن در برابر دادههای جدید میشود.
JPEG-DL
در عوض، کار جدید، با عنوان یادگیری عمیق با الهام از JPEG، معماری بسیار ساده تری را ارائه می دهد که حتی می تواند بر مدل های موجود تحمیل شود.
محققان دانشگاه واترلو اظهار داشتند:
نتایج نشان می دهد که JPEG-DL به طور قابل توجهی و به طور مداوم از DL استاندارد در معماری های مختلف DNN با افزایش ناچیز پیچیدگی مدل بهتر عمل می کند.
به طور خاص، JPEG-DL دقت طبقهبندی را تا 20.9 درصد در برخی از مجموعه دادههای طبقهبندی دقیق بهبود میبخشد، در حالی که تنها 128 پارامتر قابل آموزش را به خط لوله DL اضافه میکند. علاوه بر این، برتری JPEG-DL نسبت به DL استاندارد با افزایش استحکام خصمانه مدل های آموخته شده و کاهش اندازه فایل تصاویر ورودی بیشتر نشان داده می شود.
نویسندگان ادعا میکنند که سطح بهینه کیفیت فشردهسازی JPEG میتواند به شبکه عصبی کمک کند تا موضوع/های مرکزی تصویر را تشخیص دهد. در مثال زیر، نتایج خط پایه (سمت چپ) را می بینیم که پرنده را در پس زمینه زمانی که ویژگی ها توسط شبکه عصبی به دست می آیند، ترکیب می کنند. در مقابل، JPEG-DL (راست) در تشخیص و مشخص کردن موضوع عکس موفق است.

آزمایشهایی در برابر روشهای پایه برای JPEG-DL. منبع: https://arxiv.org/pdf/2410.07081
“این پدیده،” توضیح می دهند، “فشرده سازی کمک می کند” در [2021] کاغذ، با این واقعیت توجیه میشود که فشردهسازی میتواند نویز و ویژگیهای مزاحم پسزمینه را حذف کند، در نتیجه شی اصلی را در یک تصویر برجسته میکند، که به DNNها کمک میکند پیشبینی بهتری داشته باشند.
روش
JPEG-DL یک متمایز پذیر را معرفی می کند کوانتایزر نرم، که جایگزین عملیات کوانتیزاسیون غیر قابل تمایز در یک روال استاندارد بهینه سازی JPEG می شود.
این اجازه می دهد مبتنی بر گرادیان بهینه سازی تصاویر این در کدگذاری JPEG معمولی که از a استفاده می کند امکان پذیر نیست کوانتایزر یکنواخت با عملیات گرد کردن که نزدیکترین ضریب را تقریب میکند.
تمایز طرحواره JPEG-DL اجازه بهینه سازی مشترک پارامترهای مدل آموزشی و کوانتیزاسیون JPEG (سطح فشرده سازی) را می دهد. بهینه سازی مشترک به این معنی است که هم مدل و هم داده های آموزشی در کنار یکدیگر قرار می گیرند انتها به انتها فرآیند، و نیازی به انجماد لایه ها نیست.
اساساً، این سیستم فشرده سازی JPEG یک مجموعه داده (خام) را برای تناسب با منطق فرآیند تعمیم سفارشی می کند.
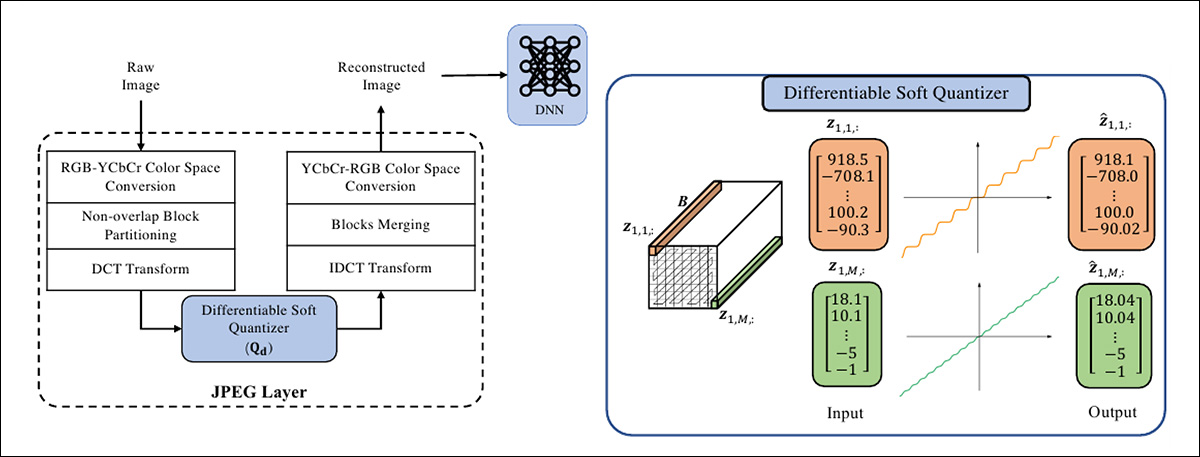
طرح مفهومی برای JPEG-DL.
ممکن است فرض شود که داده های خام می تواند علوفه ایده آل برای آموزش باشد. پس از همه، تصاویر زمانی که به صورت دستهای اجرا میشوند، بهطور کامل در فضای رنگی تمامقد مناسب از حالت فشرده خارج میشوند. پس فرمت اصلی چه تفاوتی دارد؟
خوب، از آنجایی که فشرده سازی JPEG برای مشاهده انسان بهینه شده است، قسمت هایی از جزئیات یا رنگ را به روشی مطابق با این هدف دور می کند. با توجه به تصویری از یک دریاچه در زیر آسمان آبی، سطوح فشردگی بیشتری روی آسمان اعمال خواهد شد، زیرا حاوی جزئیات «ضروری» نیست.
از سوی دیگر، یک شبکه عصبی فاقد فیلترهای غیرعادی است که به ما اجازه میدهند سوژههای مرکزی را صفر کنیم. درعوض، احتمالاً هر گونه مصنوعات نواری در آسمان را به عنوان داده های معتبر در نظر می گیرد که باید در آن ادغام شوند. فضای نهفته.

اگرچه یک انسان در یک تصویر به شدت فشرده شده (سمت چپ) نوارهای موجود در آسمان را از بین میبرد، یک شبکه عصبی نمیداند که این محتوا باید دور ریخته شود و به تصویری با کیفیت بالاتر (سمت راست) نیاز دارد. منبع: https://lensvid.com/post-processing/fix-jpeg-artifacts-in-photoshop/
بنابراین، بعید است که یک سطح از فشرده سازی JPEG با کل محتوای یک مجموعه داده آموزشی مطابقت داشته باشد، مگر اینکه یک دامنه بسیار خاص را نشان دهد. برای مثال، عکسهای انبوه جمعیت به فشردهسازی بسیار کمتری نسبت به تصویر با فوکوس باریک از یک پرنده نیاز دارند.
نویسندگان مشاهده می کنند که کسانی که با چالش های کوانتیزاسیون آشنا نیستند، اما با اصول اولیه ترانسفورماتورها معماری، می تواند این فرآیندها را به عنوان یک “عملیات توجه”، به طور گسترده
داده ها و آزمون ها
JPEG-DL در برابر معماری های مبتنی بر ترانسفورماتور و شبکه های عصبی کانولوشنال (سی ان ان). معماری های مورد استفاده بودند EfficientFormer-L1; ResNet; VGG; موبایل نت; و ShuffleNet.
نسخههای ResNet مورد استفاده مختص به سیفار مجموعه داده: ResNet32، ResNet56، و ResNet110. VGG8 و VGG13 برای آزمایشهای مبتنی بر VGG انتخاب شدند.
برای CNN، روش آموزشی از کار سال 2020 مشتق شده است تقطیر نمایندگی متضاد (CRD). برای EfficientFormer-L1 (مبتنی بر ترانسفورماتور)، روش تمرینی از سال 2023 راهاندازی مدلها با مدلهای بزرگتر استفاده شد.
برای وظایف ریزدانه مشخص شده در آزمون ها، از چهار مجموعه داده استفاده شد: سگ های استنفورد; دانشگاه آکسفورد گل ها; CUB-200-2011 (پرندگان CalTech); و حیوانات خانگی (“گربه ها و سگ ها”، همکاری بین دانشگاه آکسفورد و حیدرآباد در هند).
برای کارهای دقیق در CNN، نویسندگان از آن استفاده کردند PreAct ResNet-18 و DenseNet-BC. برای EfficientFormer-L1، روشی که در بالا ذکر شد راهاندازی مدلها با مدلهای بزرگتر استفاده شد.
در سراسر CIFAR-100 و وظایف ریزدانه، مقادیر مختلف تبدیل کسینوس گسسته فرکانسهای (DCT) در رویکرد فشردهسازی JPEG با استفاده از آدم بهینه ساز، به منظور انطباق با میزان یادگیری برای لایه JPEG در سراسر مدل هایی که آزمایش شده اند.
در تست های روی ImageNet-1Kدر تمام آزمایشها، نویسندگان از PyTorch استفاده کردند SqueezeNet، ResNet-18 و ResNet-34 به عنوان مدل های اصلی.
برای ارزیابی بهینهسازی لایه JPEG، محققان استفاده کردند نزول گرادیان تصادفی (SGD) به جای آدام، برای عملکرد پایدارتر. با این حال، برای آزمایش ImageNet-1K، روش از مقاله 2019 کوانتیزاسیون اندازه مرحله ای را یاد گرفتیم به کار گرفته شد.
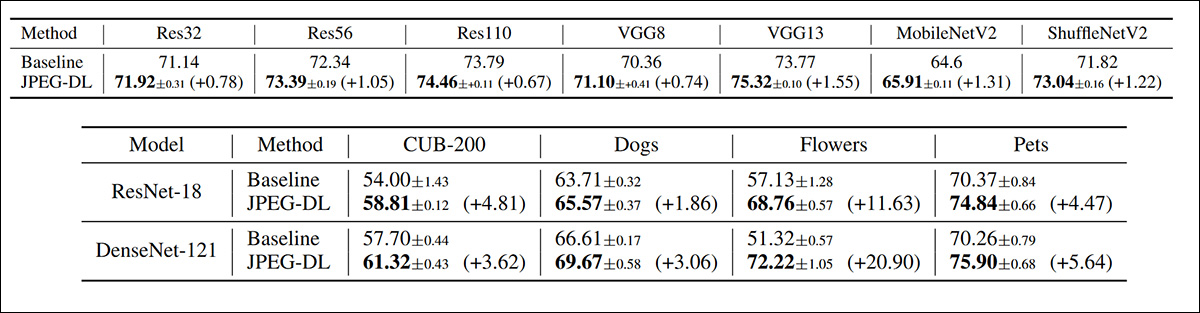
بالای 1 دقت اعتبارسنجی برای خط مبنا در مقابل JPEG-DL در CIFAR-100، با میانگین انحراف استاندارد و میانگین در سه اجرا. در زیر، دقت اعتبار سنجی برتر 1 در وظایف مختلف طبقه بندی تصاویر ریز دانه، در معماری های مدل های مختلف، مجدداً از سه پاس به طور میانگین محاسبه شده است.
نظر در مورد دور اولیه نتایج نشان داده شده در بالا، نویسندگان بیان می کنند:
در هر هفت مدل آزمایش شده برای CIFAR-100، JPEG-DL به طور مداوم بهبودهایی را ارائه می دهد، با افزایش دقت 1.53 درصدی. در وظایف ریزدانه، JPEG-DL افزایش عملکرد قابل توجهی را با بهبود تا 20.90٪ در تمام مجموعه داده ها با استفاده از دو مدل مختلف ارائه می دهد.
نتایج آزمایش های ImageNet-1K در زیر نشان داده شده است:

نتایج صحت اعتبار سنجی Top-1 در ImageNet در چارچوب های مختلف.
در اینجا در این مقاله آمده است:
با افزایش ناچیز پیچیدگی (اضافه کردن 128 پارامتر)، JPEG-DL به افزایش 0.31٪ در دقت بالای 1 برای SqueezeNetV1.1 در مقایسه با خط پایه با استفاده از یک دور منفرد دست می یابد. [quantization] عملیات
با افزایش تعداد دورهای کوانتیزاسیون به پنج، شاهد بهبودی اضافی 0.20% هستیم که منجر به افزایش کل 0.51% نسبت به خط پایه میشود.
محققان همچنین این سیستم را با استفاده از داده های به خطر انداخته شده توسط این سیستم آزمایش کردند حمله خصمانه نزدیک می شود روش امضای گرادیان سریع (FGSM) و نزول گرادیان پیش بینی شده (PGD).
این حملات در دو مدل از CIFAR-100 انجام شد:

نتایج آزمایش برای JPEG-DL، در برابر دو چارچوب استاندارد حمله متخاصم.
نویسندگان بیان می کنند:
‘[The] مدلهای JPEG-DL به طور قابلتوجهی استحکام خصمانه را در مقایسه با مدلهای استاندارد DNN بهبود میبخشند، با بهبودهایی تا 15% برای FGSM و 6% برای PGD.
علاوه بر این، همانطور که قبلا در مقاله نشان داده شد، نویسندگان مقایسه ای از نقشه های ویژگی استخراج شده با استفاده از GradCAM++ – چارچوبی که می تواند ویژگی های استخراج شده را به صورت بصری برجسته کند.

یک تصویر GradCAM++ برای طبقهبندی تصویر پایه و JPEG-DL، با ویژگیهای استخراجشده برجسته.
این مقاله خاطرنشان می کند که JPEG-DL یک نتیجه بهبود یافته ایجاد می کند، و در یک نمونه حتی قادر به طبقه بندی تصویری بود که خط پایه نتوانست آن را شناسایی کند. با توجه به تصویری که قبلاً نشان داده شده بود پرندگان، نویسندگان میگویند:
‘[It] واضح است که نقشههای ویژگی از مدل JPEG-DL کنتراست قابل توجهی بهتری را بین اطلاعات پیشزمینه (پرنده) و پسزمینه در مقایسه با نقشههای ویژگی تولید شده توسط مدل پایه نشان میدهند.
به طور خاص، شی پیشزمینه در نقشههای ویژگی JPEG-DL در یک کانتور کاملاً مشخص قرار میگیرد که باعث میشود از نظر بصری از پسزمینه متمایز شود.
در مقابل، نقشههای ویژگی مدل پایه ساختار ترکیبیتری را نشان میدهند، جایی که پیشزمینه انرژی بالاتری در فرکانسهای پایین دارد و باعث میشود که به آرامی با پسزمینه ترکیب شود.
نتیجه گیری
JPEG-DL برای استفاده در موقعیتهایی در نظر گرفته شده است که دادههای خام در دسترس هستند – اما بسیار جالب است که ببینیم آیا برخی از اصول برجستهشده در این پروژه میتوانند در آموزش دادههای مرسوم، که در آن محتوا ممکن است کیفیت پایینتری داشته باشد (به عنوان مثال غالباً با مجموعه دادههای فرامقیاس حذف شده از اینترنت رخ میدهد).
همانطور که وجود دارد، این تا حد زیادی یک مشکل حاشیه نویسی باقی می ماند، اگرچه در مورد آن پرداخته شده است تشخیص تصویر مبتنی بر ترافیک، و جاهای دیگر.
اولین بار پنجشنبه 10 اکتبر 2024 منتشر شد

