
تحقیقات جدید از روسیه یک روش غیر متعارف برای تشخیص تصاویر غیر واقعی AI ایجاد می کند-نه با بهبود صحت مدلهای بزرگ بینایی زبان (LVLMS) ، بلکه با استفاده عمدی از آنها تمایل به توهمبشر
رویکرد جدید چندین “حقایق اتمی” را در مورد یک تصویر با استفاده از LVLMS استخراج می کند ، سپس اعمال می شود استنباط زبان طبیعی (NLI) برای اندازه گیری منظم تناقضات بین این گفته ها-به طور موثری نقص های مدل را به یک ابزار تشخیصی برای تشخیص تصاویری که از عقل سلیم استفاده می کنند تبدیل می کند.

دو تصویر از Whoops! مجموعه داده در کنار بیانیه های خودکار توسط مدل LVLM. تصویر سمت چپ واقع بینانه است و منجر به توصیفات مداوم می شود ، در حالی که تصویر راست غیر معمول باعث توهم مدل می شود ، و اظهارات متناقض یا نادرست ایجاد می کند. منبع: https://arxiv.org/pdf/2503.15948
LVLM از وی خواسته شده است که واقع گرایی تصویر دوم را ارزیابی کند. چیزی از آنجا که شتر به تصویر کشیده شده دارای سه تپه است ، ناشناخته در طبیعتبشر
با این حال ، LVLM در ابتدا مخلوط می شود > 2 تپه با > 2 حیوان، از آنجا که این تنها راهی است که شما می توانید در یک “تصویر شتر” سه تپه مشاهده کنید. سپس به توهم چیزی حتی بعیدتر از سه تپه (یعنی “دو سر”) ادامه می یابد و هرگز به شرح دیگری که به نظر می رسد باعث ظن های آن شده است – هنگ اضافی غیرممکن است.
محققان اثر جدید دریافتند که مدل های LVLM می توانند این نوع ارزیابی را به صورت بومی انجام دهند و به طور همزمان با مدلهای (یا بهتر از) که بوده اند با ریز تنظیم شده برای یک کار از این نوع. از آنجا که تنظیم دقیق از نظر کاربرد پایین دست پیچیده ، گران و نسبتاً شکننده است ، کشف یک استفاده بومی برای یکی از موارد بزرگترین موانع جاده در انقلاب فعلی هوش مصنوعی پیچ و تاب و طراوت بر روندهای کلی ادبیات است.
ارزیابی باز
نویسندگان ادعا می کنند که اهمیت این رویکرد این است که می توان با آن مستقر شد منبع باز چارچوب ها در حالی که یک مدل پیشرفته و با سرمایه گذاری بالا مانند ChatGPT می تواند (مقاله قبول می کند) به طور بالقوه نتایج بهتری را در این کار ارائه می دهد ، ارزش واقعی بحث برانگیز ادبیات برای اکثر ما (و به ویژه برای جوامع سرگرمی و VFX) امکان ترکیب و توسعه پیشرفت های جدید در پیاده سازی های محلی است. در مقابل ، همه چیز که برای یک سیستم تجاری اختصاصی API در نظر گرفته شده است ، منوط به عقب نشینی ، افزایش قیمت خودسرانه و سیاست های سانسور است که احتمالاً بیشتر از نیازها و مسئولیت های کاربر ، نگرانی های شرکت یک شرکت را منعکس می کند.
در مقاله جدید عنوان شده است با توهم مبارزه نکنید ، از آنها استفاده کنید: برآورد رئالیسم تصویر با استفاده از NLI بر حقایق اتمی، و از پنج محقق در سراسر انستیتوی علوم و فناوری Skolkovo (SKOLTECH) ، انستیتوی فیزیک و فناوری مسکو و شرکت های روسی MTS AI و AIRI آمده است. کار دارای همراه با صفحه GitHubبشر
روش
نویسندگان از اسرائیل/ایالات متحده استفاده می کنند اوه مجموعه داده برای پروژه:

نمونه هایی از تصاویر غیرممکن از Whoops! مجموعه داده قابل توجه است که چگونه این تصاویر عناصر قابل قبول را جمع می کنند ، و اینکه غیرممکن بودن آنها باید بر اساس هماهنگی این جنبه های ناسازگار محاسبه شود. منبع: https://whoops-benchmark.github.io/
این مجموعه داده شامل 500 تصویر مصنوعی و بیش از 10،874 حاشیه نویسی است که به طور خاص برای آزمایش استدلال عوام مدل های هوش مصنوعی و درک ترکیبی طراحی شده است. این با همکاری طراحان وظیفه تولید تصاویر چالش برانگیز از طریق سیستم های متن به تصویر مانند ایجاد شده است دوره بین المللی و سری Dall-E-تولید سناریوهای دشوار یا غیرممکن برای گرفتن طبیعی:

نمونه های بیشتر از Whoops! مجموعه داده منبع: https://huggingface.co/datasets/nlphuji/whoops
رویکرد جدید در سه مرحله کار می کند: اول ، LVLM (به طور خاص llava-v1.6-mistral-7b) از ایجاد چندین جمله ساده – به نام “حقایق اتمی” – توصیف یک تصویر استفاده می شود. این اظهارات با استفاده از جستجوی پرتو متنوع، اطمینان از تنوع در خروجی ها.
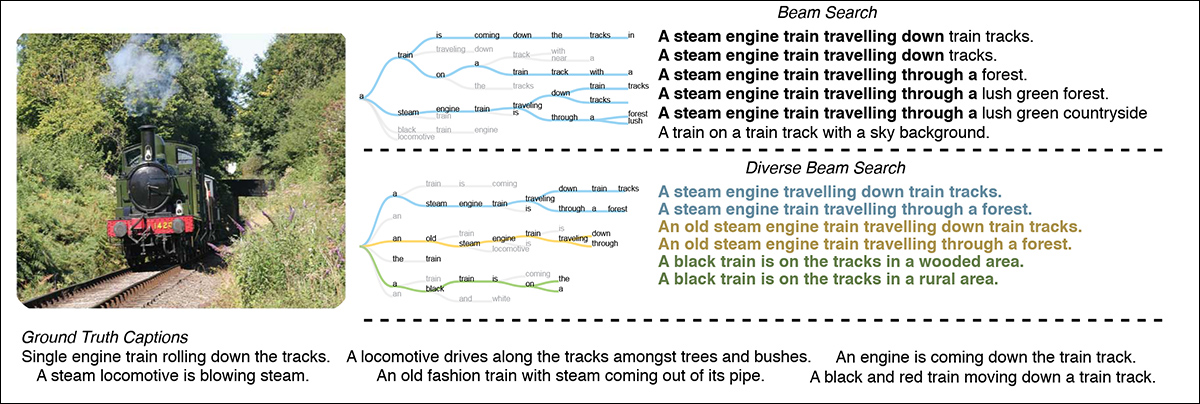
جستجوی پرتوهای متنوع با بهینه سازی یک هدف تنوع با اوج ، انواع بهتری از گزینه های عنوان را ایجاد می کند. منبع: https://arxiv.org/pdf/1610.02424
در مرحله بعد ، هر بیانیه تولید شده به طور سیستماتیک با هر عبارت دیگر با استفاده از یک مدل استنتاج زبان طبیعی مقایسه می شود ، که نمرات را نشان می دهد که نشان می دهد جفت اظهارات مستلزم ، متناقض است یا نسبت به یکدیگر خنثی هستند.
تضادها نشان دهنده توهم یا عناصر غیرواقعی در تصویر است:
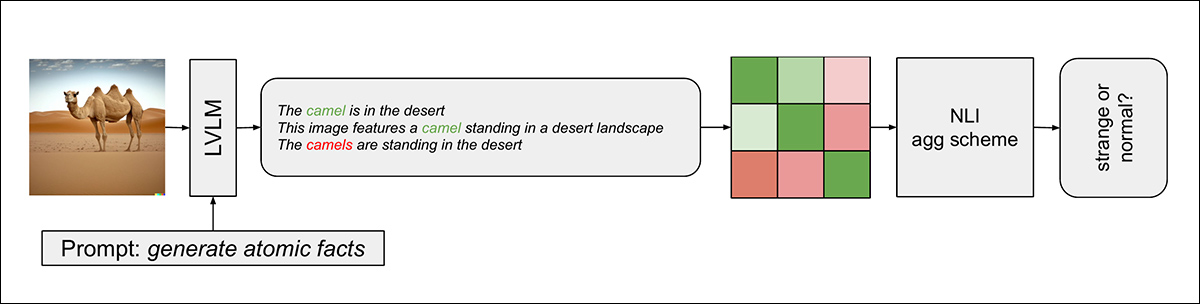
طرحواره برای خط لوله تشخیص.
سرانجام ، این روش این نمرات NLI زوج را به یک “نمره واقعیت” واحد تبدیل می کند که انسجام کلی اظهارات تولید شده را تعیین می کند.
محققان روشهای مختلف تجمیع را مورد بررسی قرار دادند و یک رویکرد مبتنی بر خوشه بندی بهترین عملکرد را انجام داد. نویسندگان اعمال کردند خوشه بندی k-mean الگوریتم برای جدا کردن نمرات NLI فردی به دو خوشه ، و سانتروئید سپس از خوشه با ارزش پایین به عنوان متریک نهایی انتخاب شد.
استفاده از دو خوشه به طور مستقیم با ماهیت باینری کار طبقه بندی ، یعنی متمایز واقع بینانه از تصاویر غیرواقعی است. منطق شبیه به انتخاب ساده ترین امتیاز در کل است. با این حال ، خوشه بندی به متریک اجازه می دهد تا به جای تکیه بر یک واحد ، میانگین تضاد را در چندین واقعیت نشان دهد دورتربشر
داده ها و آزمایشات
محققان سیستم خود را بر روی Whoops آزمایش کردند! معیار پایه ، با استفاده از چرخش تقسیمات تست (یعنی ، اعتبار سنجی متقابل). مدل های آزمایش شده بودند blip2 flant5-xl وت blip2 flant5-xxl در شکاف ها ، و blip2 flant5-xxl در قالب صفر-شات (یعنی ، بدون آموزش اضافی).
برای یک پایه اصلی آموزش ، نویسندگان LVLMS را با این عبارت برانگیختند آیا این غیرمعمول است؟ لطفاً به طور خلاصه با یک جمله کوتاه توضیح دهید ‘، که تحقیقات قبلی برای کشف تصاویر غیرواقعی مؤثر است.
مدل های ارزیابی شده بودند llava 1.6 mistral 7bبا Llava 1.6 Vicuna 13b، و دو اندازه (7/13 میلیارد پارامتر) از دستور دادنبشر
روش آزمایش در 102 جفت تصاویر واقع گرایانه و غیرواقعی (“عجیب”) متمرکز شده است. هر جفت از یک تصویر عادی و یک همتای تعریف کننده از همبستگی تشکیل شده بود.
سه حاشیه نویسی انسانی با برچسب تصاویر ، به اجماع 92 ٪ رسیدند و این نشانگر توافق قوی انسانی در مورد آنچه “عجیب” است. صحت روشهای ارزیابی با توانایی آنها در تمایز درست بین تصاویر واقع گرایانه و غیرواقعی اندازه گیری شد.
این سیستم با استفاده از اعتبار سنجی متقاطع سه برابر ، به طور تصادفی داده ها با یک دانه ثابت مورد بررسی قرار گرفت. نویسندگان وزن را برای نمرات متعهد (بیانیه هایی که از نظر منطقی موافق هستند) و نمرات تناقض (بیانیه هایی که از نظر منطقی تضاد دارند) در طول آموزش تنظیم کردند ، در حالی که نمرات “خنثی” در صفر ثابت بودند. دقت نهایی به عنوان میانگین در تمام تقسیمات تست محاسبه شد.
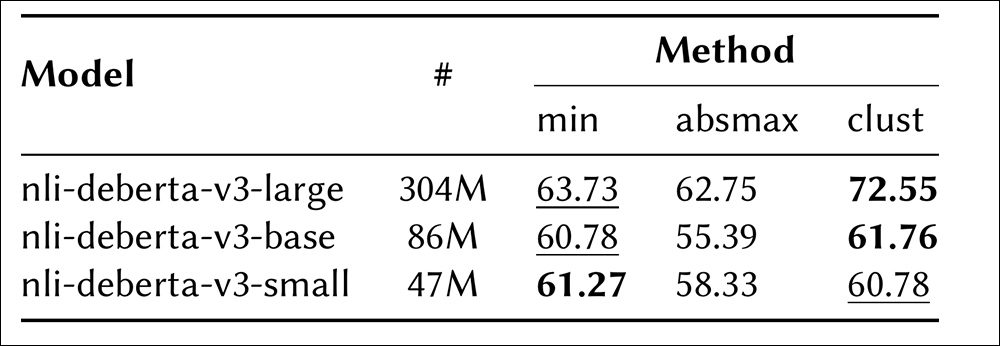
مقایسه مدل های مختلف NLI و روش های تجمع در زیر مجموعه از پنج واقعیت تولید شده ، با دقت اندازه گیری می شود.
با توجه به نتایج اولیه نشان داده شده در بالا ، مقاله آمده است:
” [‘clust’] روش به عنوان یکی از بهترین عملکردها برجسته است. این بدان معنی است که تجمع همه نمرات تضاد بسیار مهم است ، نه اینکه فقط روی ارزشهای شدید تمرکز کنید. علاوه بر این ، بزرگترین مدل NLI (NLI-DEBERTA-V3-LARGE) از همه دیگران برای همه روشهای جمع آوری بهتر عمل می کند ، و این نشان می دهد که جوهر مسئله را به طور مؤثر ضبط می کند. “
نویسندگان دریافتند که وزن های بهینه به طور مداوم از تضاد در مورد مستلزم برخوردار هستند ، و این نشان می دهد که تضادها برای تمایز تصاویر غیرواقعی آموزنده تر هستند. روش آنها از تمام روشهای صفر شات آزمایش شده بهتر عمل می کند ، و از نزدیک به عملکرد مدل BLIP2 تنظیم شده نزدیک نزدیک می شود:
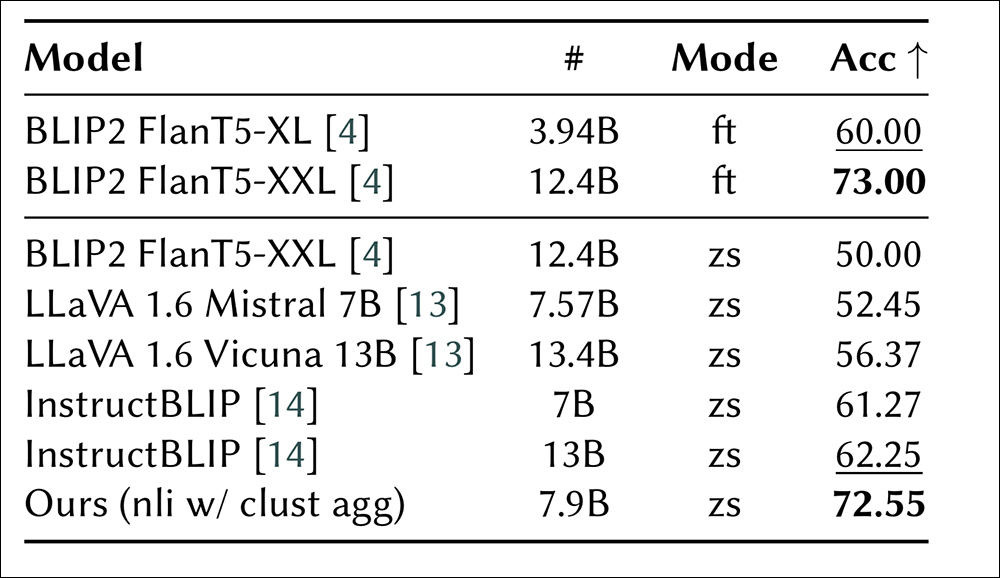
عملکرد رویکردهای مختلف در مورد Whoops! معیار روشهای تنظیم شده (FT) در بالا ظاهر می شوند ، در حالی که روش های صفر-شات (ZS) در زیر ذکر شده است. اندازه مدل تعداد پارامترها را نشان می دهد و از دقت به عنوان متریک ارزیابی استفاده می شود.
آنها همچنین ، تا حدودی غیر منتظره ، خاطرنشان كردند كه با توجه به همان فوریت ، آموزش های بهتر از مدل های Llava قابل مقایسه عمل می كنند. این مقاله ضمن شناخت دقت برتر GPT-4O ، بر اولویت نویسندگان برای نشان دادن راه حل های عملی و منبع باز تأکید می کند و به نظر می رسد ، به طور منطقی می تواند در سوءاستفاده صریح توهمات به عنوان ابزاری تشخیصی ادعای تازگی داشته باشد.
پایان
با این حال ، نویسندگان بدهی پروژه خود را به سال 2024 تصدیق می کنند قصبها Outing ، همکاری بین دانشگاه تگزاس در دانشگاه دالاس و جانس هاپکینز.

نمونه ای از نحوه ارزیابی FaithScore. اول ، اظهارات توصیفی در یک پاسخ تولید LVLM مشخص می شود. در مرحله بعد ، این گفته ها به حقایق اتمی فردی تقسیم می شوند. سرانجام ، حقایق اتمی در برابر تصویر ورودی برای تأیید صحت آنها مقایسه می شوند. متن زیر خطی محتوای توصیفی عینی را برجسته می کند ، در حالی که متن آبی حاکی از بیانیه های توهم شده است ، و به FaityScore اجازه می دهد تا یک اندازه گیری قابل تفسیر از صحت واقعی ارائه دهد. منبع: https://arxiv.org/pdf/2311.01477
FaithScore وفاداری توصیفات تولید شده توسط LVLM را با تأیید سازگاری در برابر محتوای تصویر اندازه گیری می کند ، در حالی که روش های جدید مقاله به صراحت از توهم LVLM برای تشخیص تصاویر غیرواقعی از طریق تضادها در حقایق تولید شده با استفاده از استنتاج زبان طبیعی استفاده می کند.
کار جدید ، به طور طبیعی ، وابسته به عجیب و غریب مدل های زبان فعلی و به موجب آنها برای توهم است. اگر توسعه مدل همیشه باید یک مدل کاملاً غیر مسکن را به وجود آورد ، حتی اصول کلی کار جدید دیگر قابل اجرا نیست. با این حال ، این باقی مانده است چشم انداز چالش برانگیزبشر
اولین بار منتشر شد سه شنبه ، 25 مارس 2025