CUDA برای یادگیری ماشین: کاربردهای عملی
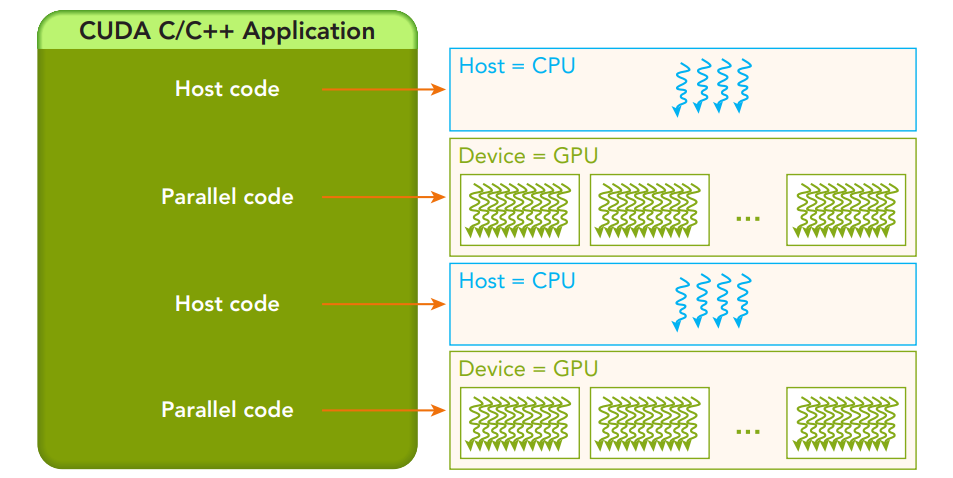
ساختار یک برنامه CUDA C/C++، که در آن کد میزبان (CPU) اجرای کد موازی روی دستگاه (GPU) را مدیریت می کند.
اکنون که اصول اولیه را پوشش دادیم، بیایید بررسی کنیم که چگونه CUDA میتواند برای وظایف رایج یادگیری ماشین اعمال شود.
ضرب ماتریس
ضرب ماتریس یک عملیات اساسی در بسیاری از الگوریتم های یادگیری ماشین، به ویژه در شبکه های عصبی است. CUDA می تواند به طور قابل توجهی این عملیات را تسریع کند. در اینجا یک پیاده سازی ساده وجود دارد:
__global__ void matrixMulKernel(float *A, float *B, float *C, int N)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0.0f;
if (row This implementation divides the output matrix into blocks, with each thread computing one element of the result. While this basic version is already faster than a CPU implementation for large matrices, there's room for optimization using shared memory and other techniques.
Convolution Operations
Convolutional Neural Networks (CNNs) rely heavily on convolution operations. CUDA can dramatically speed up these computations. Here's a simplified 2D convolution kernel:
__global__ void convolution2DKernel(float *input, float *kernel, float *output,
int inputWidth, int inputHeight,
int kernelWidth, int kernelHeight)
{
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x = 0 && inputX = 0 && inputY This kernel performs a 2D convolution, with each thread computing one output pixel. In practice, more sophisticated implementations would use shared memory to reduce global memory accesses and optimize for various kernel sizes.
Stochastic Gradient Descent (SGD)
SGD is a cornerstone optimization algorithm in machine learning. CUDA can parallelize the computation of gradients across multiple data points. Here's a simplified example for linear regression:
__global__ void sgdKernel(float *X, float *y, float *weights, float learningRate, int n, int d)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i >>(X, y, weights, learningRate, n, d);
}
}
این پیاده سازی وزن ها را به صورت موازی برای هر نقطه داده به روز می کند. این atomicAdd تابع برای مدیریت به روز رسانی همزمان وزنه ها به صورت ایمن استفاده می شود.
بهینه سازی CUDA برای یادگیری ماشین
در حالی که مثالهای بالا اصول استفاده از CUDA را برای وظایف یادگیری ماشین نشان میدهند، چندین تکنیک بهینهسازی وجود دارد که میتواند عملکرد را بیشتر افزایش دهد:
دسترسی به حافظه ترکیبی
GPUها زمانی به اوج کارایی دست می یابند که رشته ها در یک Warp به مکان های حافظه پیوسته دسترسی داشته باشند. اطمینان حاصل کنید که ساختارهای داده و الگوهای دسترسی شما دسترسی به حافظه ادغام شده را ارتقا می دهند.
استفاده از حافظه مشترک
حافظه مشترک بسیار سریعتر از حافظه جهانی است. از آن برای ذخیره اطلاعاتی که اغلب به آنها دسترسی دارید در یک بلوک رشته استفاده کنید.
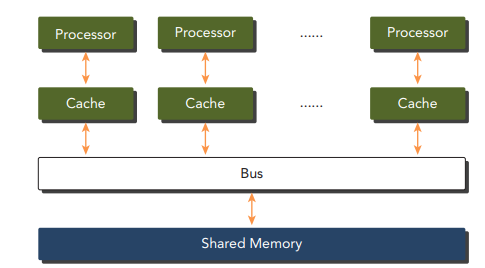
درک سلسله مراتب حافظه با CUDA
این نمودار معماری یک سیستم چند پردازنده ای با حافظه مشترک را نشان می دهد. هر پردازنده کش مخصوص به خود را دارد که امکان دسترسی سریع به داده های پرکاربرد را فراهم می کند. پردازنده ها از طریق یک گذرگاه مشترک ارتباط برقرار می کنند که آنها را به یک فضای حافظه مشترک بزرگتر متصل می کند.
به عنوان مثال، در ضرب ماتریس:
__global__ void matrixMulSharedKernel(float *A, float *B, float *C, int N)
{
__shared__ float sharedA[TILE_SIZE][TILE_SIZE];
__shared__ float sharedB[TILE_SIZE][TILE_SIZE];
int bx = blockIdx.x; int by = blockIdx.y;
int tx = threadIdx.x; int ty = threadIdx.y;
int row = by * TILE_SIZE + ty;
int col = bx * TILE_SIZE + tx;
float sum = 0.0f;
for (int tile = 0; tile This optimized version uses shared memory to reduce global memory accesses, significantly improving performance for large matrices.
Asynchronous Operations
CUDA supports asynchronous operations, allowing you to overlap computation with data transfer. This is particularly useful in machine learning pipelines where you can prepare the next batch of data while the current batch is being processed.
cudaStream_t stream1, stream2;
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
// Asynchronous memory transfers and kernel launches
cudaMemcpyAsync(d_data1, h_data1, size, cudaMemcpyHostToDevice, stream1);
myKernel>>(d_data1, ...);
cudaMemcpyAsync(d_data2, h_data2, size, cudaMemcpyHostToDevice, stream2);
myKernel>>(d_data2, ...);
cudaStreamSynchronize(stream1);
cudaStreamSynchronize(stream2);
هسته های تانسور
برای بارهای کاری یادگیری ماشین، هسته های تانسور NVIDIA (موجود در معماری های جدیدتر GPU) می تواند سرعت های قابل توجهی را برای عملیات ضرب ماتریس و پیچیدگی ایجاد کند. کتابخانه ها مانند cuDNN و cuBLAS به طور خودکار از هسته های Tensor در صورت موجود بودن استفاده می کند.
چالش ها و ملاحظات
در حالی که CUDA مزایای فوق العاده ای برای یادگیری ماشین ارائه می دهد، مهم است که از چالش های بالقوه آگاه باشید:
- مدیریت حافظه: حافظه GPU در مقایسه با حافظه سیستم محدود است. مدیریت کارآمد حافظه بسیار مهم است، به ویژه هنگام کار با مجموعه داده ها یا مدل های بزرگ.
- سربار انتقال داده: انتقال داده ها بین CPU و GPU می تواند یک گلوگاه باشد انتقال را به حداقل برسانید و در صورت امکان از عملیات ناهمزمان استفاده کنید.
- دقت: پردازنده های گرافیکی به طور سنتی در محاسبات تک دقیق (FP32) برتری دارند. در حالی که پشتیبانی از دقت دوگانه (FP64) بهبود یافته است، اغلب کندتر است. بسیاری از وظایف یادگیری ماشینی میتوانند با دقت پایینتری به خوبی کار کنند (مثلاً FP16)، که پردازندههای گرافیکی مدرن بسیار کارآمد از عهده آن برمیآیند.
- پیچیدگی کد: نوشتن کد CUDA کارآمد می تواند پیچیده تر از کد CPU باشد. استفاده از کتابخانه هایی مانند cuDNN، cuBLAS و فریمورک هایی مانند TensorFlow یا PyTorch می توانند به حذف بخشی از این پیچیدگی کمک کنند.
با افزایش اندازه و پیچیدگی مدلهای یادگیری ماشین، ممکن است یک GPU واحد دیگر برای مدیریت حجم کار کافی نباشد. CUDA این امکان را فراهم می کند که برنامه شما را در چندین GPU، چه در یک گره یا در یک خوشه، مقیاس بندی کنید.
ساختار برنامه نویسی CUDA
برای استفاده موثر از CUDA، درک ساختار برنامه نویسی آن ضروری است، که شامل نوشتن هسته ها (عملکردهایی که روی GPU اجرا می شوند) و مدیریت حافظه بین میزبان (CPU) و دستگاه (GPU) است.
حافظه میزبان در مقابل حافظه دستگاه
در CUDA، حافظه به طور جداگانه برای میزبان و دستگاه مدیریت می شود. توابع اصلی مورد استفاده برای مدیریت حافظه به شرح زیر است:
- cudaMalloc: حافظه را روی دستگاه اختصاص می دهد.
- cudaMemcpy: داده ها را بین هاست و دستگاه کپی می کند.
- cudaFree: حافظه دستگاه را آزاد می کند.
مثال: جمع دو آرایه
بیایید به مثالی نگاه کنیم که دو آرایه را با استفاده از CUDA جمع میکند:
__global__ void sumArraysOnGPU(float *A, float *B, float *C, int N) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx >>(d_A, d_B, d_C, N);
cudaMemcpy(h_C, d_C, bytes, cudaMemcpyDeviceToHost);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
free(h_A);
free(h_B);
free(h_C);
return 0;
}
در این مثال، حافظه هم به هاست و هم به دستگاه اختصاص داده می شود، داده ها به دستگاه منتقل می شود و هسته برای انجام محاسبات راه اندازی می شود.
نتیجه گیری
CUDA یک ابزار قدرتمند برای مهندسین یادگیری ماشینی است که به دنبال سرعت بخشیدن به مدل های خود و مدیریت مجموعه داده های بزرگتر هستند. با درک مدل حافظه CUDA، بهینه سازی دسترسی به حافظه و استفاده از چندین پردازنده گرافیکی، می توانید عملکرد برنامه های یادگیری ماشین خود را به میزان قابل توجهی افزایش دهید.